12 - Communication Client-Serveur
Nous allons créer aujourd'hui un serveur dynamique Web en Python.
Il pourra recevoir des paramètres via une requête GET ou une requête POST.
Prérequis : Archi protocole HTTP et surtout les activités Python.
Evaluation ✎ : questions 07-10-11-18-19-22-23-24.
Documents de cours :
1 - Un serveur http en Python
Voyons comment réaliser un petit serveur Python basique de façon à pouvoir réaliser un site dynamique.
Bien entendu, le serveur que nous allons réaliser n'est pas un serveur réel : il ne faudra pas l'utiliser en production. Que veut dire production ? Cela veut dire que le serveur et le site sont réellement disponibles sur Internet.
Le serveur primitif que nous allons utiliser n'est pas suffisamment sécurisé pour supporter la dure existence d'un serveur réel !
Si vous voulez apprendre, à réaliser un vrai site dynamique en Python, il faudra vous renseigner sur deux modules très efficaces :
- Flask qui permet de faire rapidement un site correct.
- Django qui est un très bon engin, puissant et efficace mais plus délicat à prendre en main : sa puissance vient de sa modularité.
Des fiches sur ces deux modules sont en cours de réalisation sur ce site.
Bon, commençons par le commencement. Allons chercher le code du petit serveur que je vous ai réalisé.
01° Placer les fichiers configuration.py et code_serveur.py dans un dossier de l’ordinateur qui doit servir de serveur Web.
Vous pouvez les télécharger avec un clic-droit - enregistrer sous pour les placer à l'endroit voulu.
Le fichier code_serveur.py n’aura pas à être ouvert ou modifié. Vous n’aurez à agir que sur le fichier configuration.py.
02° Ouvrir configuration.py dans Thonny et lancer le programme.
Vous devriez voir ce message s'ouvrir dans la console de Thonny
::: START ::: Démarrage d'un serveur d'adresse 127.0.0.1:9000. CTRL-C pour stopper
Questions :
- Quelle est l'adresse IP du serveur ?
- Quel est son PORT d'identification ?
...CORRECTION...
Non, mais oh ! Vous avez cherché ou pas ?
Bref, il suffit de lire le message affiché.
- Adresse IP : 127.0.0.1
- PORT : 9000
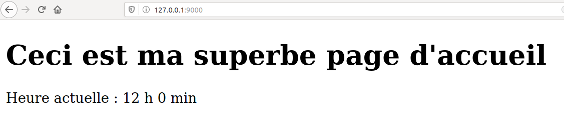
03° Ouvrir un nouvel onglet de votre navigateur et taper l'adresse dans la barre ... d'adresses.
http://127.0.0.1:9000/
Vous devriez obtenir ceci :
04° Taper maintenant localhost plutôt que l'adresse numérique dans la barre d'adresses.
http://localhost:9000/
Vous devriez obtenir ceci :
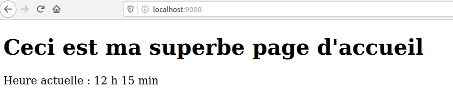
Adresse IP v4 Localhost
Nous verrons les adresses IP dans la prochaine activité, mais vous avez dû les rencontrer de nombreuses fois déjà.
Cette adresse 127.0.0.1 caractérise ce qu'on nomme l'hôte local, le localhost. Votre ordinateur en gros. Quelle que soit l'adresse IP réelle de votre ordinateur, avec 127.0.0.1 , il comprend qu'on parle de lui.
En gros, comprenez 127.0.0.1 comme C'est moi !.
05° Cette page aurait-elle été réalisable avec un site statique tel que vous en avez déjà réalisé ? Pourquoi ?
...CORRECTION...
Cette page est dynamique car on voit qu'elle change à change fois qu'on met à jour : l'heure change.
C'est bien une page proposée par un site dynamique puisque le site envoie un code HTML différent en fonction des moments.
06° Modifier le PORT dans la barre d'adresses. Demandez par exemple d'accéder au PORT 7000.
http://localhost:7000/
Vous devriez obtenir ceci :
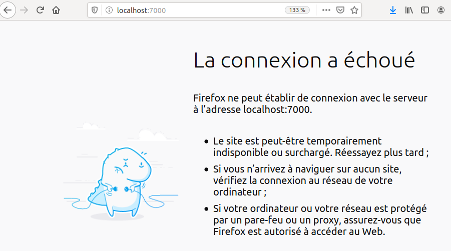
Comme vous pouvez le voir, il ne s'agit pas d'une erreur 404.
Une erreur 404, c'est quand vous atteignez bien le serveur mais que le serveur vous répond qu'il ne comprend pas la demande car la ressource demandée n'existe pas (ou plus).
Ici, c'est tout simplement que la requête n'obtient AUCUNE réponse. C'est normal : le serveur écoute le PORT 9000.
Et on peut voir cette superbe page sur son smartphone ?
Techniquement, votre site n'est pas accessible sur le Web : vous avez juste créé un serveur pour votre ordinateur. Néanmoins, si votre ordinateur est relié à votre Box par Wifi et que votre smartphone est également relié à votre Box en Wifi, les deux appareils sont sur le même réseau local.
Il est donc possible de voir les pages fournies par le serveur sur votre smartphone sous deux conditions :
- les deux appareils passent sont sur le réseau de la Box
- vous modifiez l'adresse IP dans le programme-serveur pour y placer l'adresse locale de votre ordinateur (voir la ligne 20 de configuration.py).
✎ 07° Ouvrir une invite de commande sur votre ordinateur.
Vous aller voir qu'on peut trouver assez facilement
- son adresse IP préférée (pour identifier l'ordinateur) et
- son adresse MAC (pour identifier la carte réseau de l'ordinateur).
Taper ceci :
Windows : utiliser ipconfig/all
h:\>ipconfig/all
Configuration IP de Windows
Nom de l'hôte : e301-poste12
Carte Ethernet Connexion au réseau local :
Suffixe DNS propre à la connexion : lycee.home
Description : Broadcom NetXtreme Gigabit Ethernet
Adresse physique : 25-CE-55-XX-XX-XX
DHCP activé : Oui
Configuration automatique activée : Oui
Adresse IPv6 de liaison locale : ad41::fe80:b1b1:fe80:fe80%13(préféré)
Adresse IPv4 : 192.168.2.78(préféré)
Masque de sous-réseau : 255.255.0.0
Bail obtenu : jeudi 4 mai 2017 10:58:30
Bail expirant : vendredi 5 mai 2017 10:58:29
Passerelle par défaut : 192.168.0.250
Serveur DHCP : 192.168.0.250
IAID DHCPv6 : 270843397
DUID de client DHCPv6 : 00-01-00-01-17-BD-7B-ED-24-BE-05-10-C2-C2
Serveurs DNS : 192.168.0.253
Serveur WINS principal : 192.168.0.253
NetBIOS sur Tcpip : Activé
Linux ou MAC (systèmes Unix) : utiliser ifconfig
rv@rv-HP2:~$ ifconfig
enp2s0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 30:e1:71:XXX:XX:XX txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Boucle locale)
RX packets 11492 bytes 4538277 (4.5 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11492 bytes 4538277 (4.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlo1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.11 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::bed3:c7ad:XXXX:XXXX prefixlen 64 scopeid 0x20<link>
inet6 2a01:cb0c:96c:d400:f995:XXXX:XXXX:XXXX prefixlen 64 scopeid 0x0<global>
inet6 2a01:cb0c:96c:d400:a38b:XXXX:XXXX:XXXX prefixlen 64 scopeid 0x0<global>
ether 3c:a0:67:XX:XX:XX txqueuelen 1000 (Ethernet)
RX packets 219822 bytes 225401269 (225.4 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 160066 bytes 32570855 (32.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Question : Quelle est votre adresse IP locale ? Notez la bien, elle vous servira pour la question suivante.
08° Modifier la ligne 20 de configuration.py en y plaçant l'adresse IP trouvée à la question précédente. Attention : il faut stopper le serveur et le remettre en route pour que les modifications soient faites.
Sur un autre ordinateur de la salle du lycée (ou votre smartphone si vous êtes chez vous et qu'il est connecté en Wifi avec votre Box), tapez ceci dans la barre d'adresses
http://x.x.x.x:9000/, en remplaçant x.x.x.x par votre adresse bien entendu.
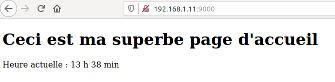
Et voilà : vous devriez pouvoir afficher votre page sur n'importe quel appareil de votre réseau local, tant que vous passez par une liaison interne.
09° Modifier la ligne 19 pour qu'on puisse identifier facilement votre page (en y mettant votre prénom par exemple).
Mettre votre nom et votre adresse IP au tableau : à partir de là, les autres personnes de la salle peuvent venir voir votre site.
Bon, comme ça fonctionne Regardons le fichier configuration.py.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48 | """
Script qui permet de gérer un serveur dynamique minimaliste
-- Choisir votre IP
-- Choisir la valeur du PORT associé à votre serveur (8000, 8080, 9000 ...)
-- Compléter la fonction reponse_a_GET pour qu'il gère de nouvelles requêtes GET si vous le voulez
-- Compléter la fonction reponse_a_POST pour qu'il gère de nouvelles requêtes POST si vous le voulez
-- Créer les pages HTML correspondantes
-- Vérifier que code_serveur.py est bien présent dans votre dossier
-- Lancer le script configuration.py
"""
# 1 - Importation
from http.server import HTTPServer
from code_serveur import Gestionnaire
from datetime import datetime
# 2 - Déclarations des constantes
IP = '192.168.1.11'
PORT = 9000
# 3 - Déclaration des fonctions
def reponse_a_GET(requete):
"""Instructions à effectuer si la requête est de type GET. requete contient les infos sur la requête"""
def reponse_a_POST(requete):
"""Instructions à effectuer si la requête est de type POST. requete contient les infos sur la requête"""
def activer_serveur():
"""Création et mise en route du serveur qui surveille ensuite les requêtes qu'on lui communique"""
# 1 - Création de l'objet-serveur httpd
Gestionnaire.GET = reponse_a_GET # on définit la fonction à exécuter sur un GET
Gestionnaire.POST = reponse_a_POST # on définit la fonction à exécuter sur un POST
adresse = (IP, PORT)
httpd = HTTPServer(adresse, Gestionnaire) # HTTP Daemon, le gestionnaire de requêtes du serveur
# 2 - Tentative de mise en route et surveillance des requêtes
print(f"::: START ::: Démarrage d'un serveur d'adresse {IP}:{PORT}. CTRL-C pour stopper")
httpd.serve_forever() # Démarrage et surveillance en boucle des messages arrivant au serveur
print('::: STOP ::: Arrêt du serveur')
httpd.server_close() # Arrêt du serveur
if __name__ == '__main__':
activer_serveur()
|
Le code Python est structuré comme d'habitude :
D'abord les importations :
14
15
16 | from http.server import HTTPServer
from code_serveur import Gestionnaire
from datetime import datetime
|
Ici, on importe la classe HTTPServer du module de base de Python nommé http.server.
La classe Gestionnaire provient de notre module maison code_serveur.
La fonction datetime provient du module basique datetime : elle permet de récupérer date et heure.
Ensuite les déclarations des constantes, les variables qu'on ne doit pas modifier une fois le programme en route.
20
21 | IP = '192.168.1.11'
PORT = 9000
|
Puis les déclarations de fonctions, ici au nombre de trois :
25
26
27
28
29
30
31
32 | def reponse_a_GET(requete):
"""Instructions à effectuer si la requête est de type GET. requete contient les infos sur la requête"""
def reponse_a_POST(requete):
"""Instructions à effectuer si la requête est de type POST. requete contient les infos sur la requête"""
def activer_serveur():
"""Création et mise en route du serveur qui surveille ensuite les requêtes qu'on lui communique"""
|
La fonction reponse_a_GET va nous permettre à gérer les requêtes GET. On voit qu'elle possède un paramètre requete qui contiendra plein d'informations sur la requête du client justement.
La fonction reponse_a_POST va pareil avec les requêtes POST.
La fonction activer_serveur lance le programme-serveur.
Enfin, le programme principal. On voit en ligne 58 que la seule action est de lancer la fonction activer_serveur. Regardons ce qu'elle fait.
✎ 10° Répondre aux questions suivantes :
- Sur quelle ligne signale-t-on d'activer la fonction reponse_a_GET lorsque le gestionnaire détecte une requête HTTP de type GET ?
- Comment se nomme le type de la variable adresse ? Un tableau, une liste, un tuple ou un dictionnaire ?
- Le f devant le string de la ligne 41 permet de signaler qu'il s'agit d'un fString. En regardant l'affichage obtenu dans la console et les accolades dans le fString, comment expliqueriez-vous ce qui s'est passé à quelqu'un qui ne connaît pas ces fameux fString ?
31
32
33
34
35
36
37
38
39
40
41
42
43
44 | def activer_serveur():
"""Création et mise en route du serveur qui surveille ensuite les requêtes qu'on lui communique"""
# 1 - Création de l'objet-serveur httpd
Gestionnaire.GET = reponse_a_GET # on définit la fonction à exécuter sur un GET
Gestionnaire.POST = reponse_a_POST # on définit la fonction à exécuter sur un POST
adresse = (IP, PORT)
httpd = HTTPServer(adresse, Gestionnaire) # HTTP Daemon, le gestionnaire de requêtes du serveur
# 2 - Tentative de mise en route et surveillance des requêtes
print(f"::: START ::: Démarrage d'un serveur d'adresse {IP}:{PORT}. CTRL-C pour stopper")
httpd.serve_forever() # Démarrage et surveillance en boucle des messages arrivant au serveur
print('::: STOP ::: Arrêt du serveur')
httpd.server_close() # Arrêt du serveur
|
On voit qu'on crée le daemon HTTP en lui fournissant :
- Ligne 37 : le p-uplet (IP, PORT) qu'il doit surveiller et
- Ligne 38 : le Gestionnaire qu'il doit utiliser pour gérer les requêtes.
✎ 11° En analysant le code de la fonction ci-dessus, quelle est à votre avis la ligne qui permet de mettre le serveur en route en laissant le daemon travailler en boucle infinie ? Comment arrêter le serveur du coup ?
A partir de là, on passe en programmation événementielle : on ne sait pas quelles requêtes vont arriver, ni quand elles vont arriver. Ni même SI elles vont arriver. Bref, le httpd surveille et travaille dès qu'une requête arrive.
2 - Gestion des requêtes GET
Regardons comme on gère les requêtes GET. Vous allez voir, c'est assez simple avec ce petit module.
Voici le code, les explications et questions sont juste derrière.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54 | def reponse_a_GET(requete):
"""Instructions à effectuer si la requête est de type GET. requete contient les infos sur la requête"""
print("::: SERVEUR ::: Reception d'une requête GET")
# 1 - Récupération optionnelle des sous-informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
# 2 - Traitement de la requête
if chemin == '/':
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Ceci est ma superbe page d'accueil</h1>")
requete.repondre(f"<p>Heure actuelle : {datetime.now().hour} h {datetime.now().minute} min</p>")
requete.repondre("</body>")
requete.repondre("</html>")
elif chemin == '/info':
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Page d'information</h1>")
requete.repondre(f"<p>Requete GET reçue par le serveur : {chaine_requete}</p>")
requete.repondre(f"<p>Chemin détecté : {chemin}</p>")
requete.repondre(f"<p>Paramètres détectés : {parametres}</p>")
requete.repondre(f"<p>Votre adresse IP : {adresse_client}</p>")
requete.repondre(f"<p>Le PORT correspondant à votre navigateur : {port_client}</p>")
requete.repondre("</body>")
requete.repondre("</html>")
elif chemin == '/add':
x = int(parametres['a'])
y = int(parametres['b'])
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Page d'information</h1>")
requete.repondre(f"<p>{x} + {y} = {x+y}</p>")
requete.repondre("</body>")
requete.repondre("</html>")
else :
requete.creer_entete(404) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Mise en place de l'en-tête HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>404 ! Je ne comprends pas votre requête !</h1>")
requete.repondre("</body>")
requete.repondre("</html>")
|
Les premières lignes servent simplement à vous montrer qu'on peut stocker par mal de choses en provenance de la requête. Vous pourrez ainsi les utiliser pour créer vos pages dynamiques si vous avez envie.
6
7
8
9
10
11 | # 1 - Récupération optionnelle des sous-informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
|
La première variable, chaine_requete, vous permet par exemple de récupérer dans Python le texte de la requête.
12° Que va contenir à votre avis la variable chemin si on utilise une URL http://127.0.0.1:9000/info ?
...CORRECTION...
Dur dur. Surtout avec l'indice en rouge.
On aura donc un contenu string valant "/info". Attention à bien prendre en compte le SLASH initial qui indique qu'on a une demande à partir de la "racine" du site.
13° Plus dur : que va contenir la variable chemin si on utilise une URL http://127.0.0.1:9000/ ou même juste http://127.0.0.1:9000 ?
...CORRECTION...
Dans les deux cas, on aura juste / pour indiquer que l'utilisateur n'a fourni aucun chemin. Nous allons donc aller à la racine du site.
Et ensuite, c'est facile : on va tester chemin et en fonction de la ressource demandée, on va générer une page HTML à la volée !
Regardons la structure de la gestion des requêtes :
13
14
15
16
17
18
19
20
21
22
23
35
47
48
| # 2 - Traitement de la requête
if chemin == '/':
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Ceci est ma superbe page d'accueil</h1>")
requete.repondre(f"<p>Heure actuelle : {datetime.now().hour} h {datetime.now().minute} min</p>")
requete.repondre("</body>")
requete.repondre("</html>")
elif chemin == '/info':
elif chemin == '/add':
else :
requete.creer_entete(404) # Mise en place de l'en-tête HTML
|
Si on ne détecte aucun chemin dans l'URL ('/'), on va créer la page d'accueil.
- Ligne 15 : on commence par régler le code http à renvoyer (200) avec la méthode creer_entete.
- Lignes suivantes : on crée simplement la page HTML à fournir, ligne par ligne ! Pour cela, on utilise la méthode repondre à laquelle on fournit la ligne à rajouter sous forme d'un string ou d'un fString.
14° Lancer les requêtes suivantes.
http://127.0.0.1:9000/info
http://127.0.0.1:9000/info?user=toto
Question A : dans quel type de structure de données sont stockés les paramètres affichés ?
Question B : Expliquer étape par étape si l'affichage obtenu correspond bien ou non à ce qui est demandé sur les lignes 24 à 35.
...CORRECTION...
Affichage pour la requête n°2
Page d'information
Requete GET reçue par le serveur : GET /info?user=toto HTTP/1.1
Chemin détecté : /info
Paramètres détectés : {'user': 'toto'}
Votre adresse IP : 192.168.1.13
Le PORT correspondant à votre navigateur : 34208
Les paramètres sont transférés dans un dictionnaire. Ce sont les accolades {} qui nous permettent d'affirmer cela.
Et pour comprendre pourquoi on obtient cet affichage, il suffit de dérouler le code à partir de la ligne 25.
23
24
25
26
27
28
29
30
31
32
33
34
35 | elif chemin == '/info':
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Page d'information</h1>")
requete.repondre(f"<p>Requete GET reçue par le serveur : {chaine_requete}</p>")
requete.repondre(f"<p>Chemin détecté : {chemin}</p>")
requete.repondre(f"<p>Paramètres détectés : {parametres}</p>")
requete.repondre(f"<p>Votre adresse IP : {adresse_client}</p>")
requete.repondre(f"<p>Le PORT correspondant à votre navigateur : {port_client}</p>")
requete.repondre("</body>")
requete.repondre("</html>")
|
Comme vous avez pu le constater, les fStrings sont très pratiques ici.
Ainsi pour la date et l'heure, il suffit de taper ceci :
f"<p>Heure actuelle : {datetime.now().hour} h {datetime.now().minute} min</p>"
15° Pas si facile : la page HTML va-t-elle être créée avec l’heure et les minutes de l’ordinateur-serveur ou de l’ordinateur-client ?
...CORRECTION...
Le code que vous avez sous les yeux est du code qui s'exécute sur l'ordinateur-serveur.
L'heure affichée est donc celle de l'ordinateur-serveur.
Le client va juste recevoir du code HTML "en dur". Il est donc possible que l'heure affichée ne corresponde pas à celle de l'ordinateur client.
Il est temps de créer une première page paramétrée : une page où l'affichage va dépendre de ce que l'utilisateur envoie.
Et vous avez un exemple dans le test suivant
36
37
38
39
40
41
42
43
44
45
46 | elif chemin == '/add':
x = int(parametres['a'])
y = int(parametres['b'])
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<body>")
requete.repondre("<h1>Page d'information</h1>")
requete.repondre(f"<p>{x} + {y} = {x+y}</p>")
requete.repondre("</body>")
requete.repondre("</html>")
|
Comme parametres est un dictionnaire qui contient les paramètres que le client a fourni, il suffit d'en récupérer les valeurs en utilisant la clé.
Pour récupérer la valeur associée à la clé 'a', il suffit donc d'utiliser parametres['a'].
Et pourquoi le int en lignes 36 et 37 ? Simplement car toute la requête n'est qu'une suite d'octets qu'on interprète ensuite en chaînes de caractères. Si on transmet le nombre 5, on reçoit donc en réalité le string '5'. Il faudra convertir si on veut faire des calculs.
16° Lancer la requête suivante :
http://192.168.1.11:9000/add?a=45&b=10
17° Et c'est maintenant que le drame arrive : l'utilisateur confond le zéro 0 et la lettre O !
http://192.168.1.11:9000/add?a=45&b=1O
Vous devriez obtenir un affichage de ce type :

Vérification et validation des données transmises
Avant d'appliquer le moindre traitement aux paramètres et données-utilisateur, il faut leur faire passer des tests de validation. Sinon, votre beau serveur va finir par terre assez vite !
Nous verrons dans quelques temps une activité Python qui vous montrera rapidement différentes techniques permettant de sécuriser les fonctions de plusieurs façons.
Si vous connaissez, vous pouvez utiliser les blocs try - except pour rendre cette page plus solide.
✎ 18° Répondre alors aux questions suivantes :
- Lors de l’envoi de la requête, le paramètre a est-il associé à la chaine '10' ou à l'entier 10 ?
- Quelle est l’instruction permettant de récupérer la valeur du paramètre a stockée dans le dictionnaire parametres ?
- A quoi sert la fonction native int qui contient l’instruction précédente ?
Si vous trouvez lourd de devoir envoyer les lignes une par une, par de problèmes : vous n'avez absolument pas obligation de le faire. On peut créer le code HTML par concaténation et ne l'envoyer qu'à la fin.
Strings et fStrings sur plusieurs lignes
Voici le même fichier mais avec cette fois une création du code avant envoi.
Le principe est d'associer à la fois les fString ET les strings définis avec trois ''' qui permettent ainsi d'inclure des " ou des ' dans les strings sans aucun problème. Et sur plusieurs lignes.
Un exemple pour vous montrer que ça devient plus clair :
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65 | elif chemin == '/info':
codeHTML = f'''
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<p>Requete GET reçue par le serveur : {chaine_requete}</p>
<p>Chemin détecté : {chemin}</p>
<p>Paramètres détectés : {parametres}</p>
<p>Votre adresse IP : {adresse_client}</p>
<p>Le PORT correspondant à votre navigateur : {port_client}</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
|
On pourrait faire mieux encore en chargeant les codes dans des fichiers HTML à part et les lire en utilisant la méthode readlines() vu dans l'activité Python sur les fichiers.
Vous pouvez télécharger le fichier Python suivant : il vous présente cette autre façon de fournir le code HTML.
📄 configuration_plusieurs_lignes.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132 | """
Script qui permet de gérer un serveur dynamique minimaliste
-- Choisir votre IP
-- Choisir la valeur du PORT associé à votre serveur (8000, 8080, 9000 ...)
-- Compléter la fonction reponse_a_GET pour qu'il gère de nouvelles requêtes GET si vous le voulez
-- Compléter la fonction reponse_a_POST pour qu'il gère de nouvelles requêtes POST si vous le voulez
-- Créer les pages HTML correspondantes
-- Vérifier que code_serveur.py est bien présent dans votre dossier
-- Lancer le script configuration.py
Ce code fait référence à une activité se trouvant ici : www.infoforall.fr/act/archi/communication-client-serveur/
"""
# 1 - Importation
from http.server import HTTPServer
from code_serveur import Gestionnaire
from datetime import datetime
# 2 - Déclarations des constantes
IP = '127.1.1.0'
PORT = 9000
# 3 - Déclaration des fonctions
def reponse_a_GET(requete):
"""Instructions à effectuer si la requête est de type GET. requete contient les infos sur la requête"""
print("::: SERVEUR ::: Reception d'une requête GET")
# 1 - Récupération optionnelle des sous-informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
# 2 - Traitement de la requête
if chemin == '/':
codeHTML = f"""
<!DOCTYPE html>
<html>
<body>
<h1>Ceci est ma superbe page d'accueil</h1>
<p>Heure actuelle : {datetime.now().hour} h {datetime.now().minute} min</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
elif chemin == '/info':
codeHTML = f'''
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<p>Requete GET reçue par le serveur : {chaine_requete}</p>
<p>Chemin détecté : {chemin}</p>
<p>Paramètres détectés : {parametres}</p>
<p>Votre adresse IP : {adresse_client}</p>
<p>Le PORT correspondant à votre navigateur : {port_client}</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
elif chemin == '/add':
x = int(parametres['a'])
y = int(parametres['b'])
codeHTML = f'''
<!DOCTYPE html>
<html>
<body>
<h1>Page d'addition</h1>
<p>{x} + {y} = {x+y}</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
else :
codeHTML = f"""
<!DOCTYPE html>
<html>
<body>
<h1>404 ! Je ne comprends pas votre requête !</h1>
</body>
</html>"""
requete.creer_entete(404) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
def reponse_a_POST(requete):
"""Instructions à effectuer si la requête est de type POST. requete contient les infos sur la requête"""
print("::: SERVEUR ::: Reception d'une requête POST")
# 1 - Récupération optionnelle des informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
# 2 - Traitement de la requête
codeHTML = f'''
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<p>Requete POST reçue par le serveur : {chaine_requete}</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
def activer_serveur():
"""Création et mise en route du serveur qui surveille ensuite les requêtes qu'on lui communique"""
# 1 - Création de l'objet-serveur httpd
Gestionnaire.GET = reponse_a_GET # on définit la fonction à exécuter sur un GET
Gestionnaire.POST = reponse_a_POST # on définit la fonction à exécuter sur un POST
adresse = (IP, PORT)
httpd = HTTPServer(adresse, Gestionnaire) # HTTP Daemon, le gestionnaire de requêtes du serveur
# 2 - Tentative de mise en route et surveillance des requêtes
print(f"::: START ::: Démarrage d'un serveur d'adresse {IP}:{PORT}. CTRL-C pour stopper")
httpd.serve_forever() # Démarrage et surveillance en boucle des messages arrivant au serveur
print('::: STOP ::: Arrêt du serveur')
httpd.server_close() # Arrêt du serveur
if __name__ == '__main__':
activer_serveur()
|
✎ 19° Réaliser (et fournir le code) d'une nouvelle page qui attend un paramètre nom. Elle doit :
- afficher le nombre de caractères contenus dans le nom (avec la fonction native len)
- afficher Gentil si le nom du personnage correspond à un gentil (Luke ou Yoda dans Star Wars par exemple)
- afficher Méchant si le nom correspond à un méchant (Darkvador, Empereur...)
- afficher Je ne sais pas, je ne suis pas une IA ! sinon
Vous pouvez créer le code ligne par ligne ou en version tout d'un coup.
Pensez juste à générer le code (200) avant d'envoyer le texte avec repondre.
Voici la structure de ce que devrait être cette page :
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64 | # 2 - Traitement de la requête
if chemin == '/':
n = parametres['nom']
if n == 'Yoda':
codeHTML = f"""
<!DOCTYPE html>
<html>
<body>
<h1>Gentil !</h1>
</body>
</html>"""
elif n == 'Empereur':
codeHTML = f"""
<!DOCTYPE html>
<html>
...
else:
codeHTML = f"""
<!DOCTYPE html>
<html>
...
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
|
Option : les plus à l'aise peuvent utiliser la méthode des strings lower() pour faire le test en tout minuscule. Sinon, il suffit de se tromper sur une majuscule - minuscule et Python pensera que les deux chaînes de caractères ne représentent pas le même personnage.
Tout le monde est gentil sur ma page !
Dans ce cas, allez voir la FAQ en bas de cette activité. Ca devrait vous aider...
3 - Méthode POST
Si vous regardez le code de la fonction reponse_a_POST, vous pourrez constater que la gestion Python de la requête est identique à celle du GET en fait : c'est le module qui va le travail de trouver les paramètres dans la requête HTTP et qui les stocke dans le dictionnaire parametres.
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114 | def reponse_a_POST(requete):
"""Instructions à effectuer si la requête est de type POST. requete contient les infos sur la requête"""
print("::: SERVEUR ::: Reception d'une requête POST")
# 1 - Récupération optionnelle des informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
# 2 - Traitement de la requête
codeHTML = f'''
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<p>Requete POST reçue par le serveur : {chaine_requete}</p>
</body>
</html>"""
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre(codeHTML)
|
Le seul truc, c'est qu'il faut réussir à créer une requête POST. Et pour cela, il va falloir créer une page HTML classique (qu'on obtiendra avec un GET) et y insérer un formulaire qui va nous permettre d'envoyer des données.
Et pour être autonome là dessus, il va falloir faire l'activité Javascript et HTML qui traite des formulaires.
En attendant, voici un fichier configuration_avec_formulaire.py qui va pour permettre d'envoyer un formulaire et d'afficher son contenu.
20° Télécharger le nouveau fichier Python (toujours avec un clic-droit) puis lancer ce nouveau serveur plutôt que l'ancien.
21° Choisir les éléments que vous voulez dans le formulaire. Ouvrir les outils de développement puis Réseau. Une fois tout cela activé, lancer la requête suivante qui vous permettra d'arriver sur la page du formulaire :
http://127.0.0.1:9000/formulaire
Vous devriez aboutir à ceci :

Il ne reste qu'à appuyer sur le bouton Submit.
Et le résultat en image :

Comme vous pouvez le voir sur l'image précédente qui visualise le résultat via les outils d'observation-réseau de Firefox, c'était une requête POST.
Comment avons-nous fait ? Nous avons utilisé ici une interface-utilisateur particulière qui permet de créer des zones dans lesquelles les utilisateurs pourront rentrer leurs données qui seront passées en paramètres : des formulaires
✎ 22° Les paramètres que vous avez fourni ont-ils été transporté via l'URL ? D'après l'activité sur le protocole HTTP, dans quelle partie de la requête HTTP l'information sur les paramètres est-elle placée en POST ? Le but de cette activité n'est pas la gestion des formulaires, nous ferons ça dans une autre activité propre à HTML et Javascript. Regardons juste le code HTML de la page où le formulaire apparaît. On voit qu'on a donc crée une balise de type <form>, comme formulaire. Il s'agit d'une structure qui permet Nous allons voir dans l'activité javascript qu'on doit remplir ce formulaire <form> avec d'autres balises spécifiques, des balises qui vont automatiquement créer une interface homme-machine intéressante. Tout çà en quelques lignes de code. Ce qui m'intéresse aujourd'hui, c'est le nom des paramètres qui vont être générés. On leur définit à l'aide des attributs name. ✎ 23° Donner le nom des 3 paramètres qui seront envoyés dans la requête POST : chercher les attributs name présents dans le formulaire. Analysons maintenant le code Python de la page créée pour récupérer cette requête POST. Comme vous le voyez, nous retrouvons encore un dictionnaire. Cette fois, j'ai décidé de lire ces clés et ses valeurs associées en même temps. A l'aide de la méthode des dictionnaires items . Et j'ai créé le code HTML en trois temps : haut de la page, concaténation des clés-valeurs puis fin de la page. Une dernière manipulation pour la route : réalisons la table de 10 en addition ou en multiplication en fonction de ce que l'utilisateur a rentré. On estimera que les données reçues sont correctes, sans vérifier le type ou les valeurs (c'est mal !). La puissance des sites dynamiques ? La possibilité de ne pas à avoir à créer toutes les possibilités ! Un élève un peu trop confiant et rapide propose ceci : ✎ 24° Lancer le programme. Vous allez vous rendre compte qu'il a été un peu trop rapide effectivement. Modifier alors le code pour qu'il gère correctement 25° Option : vous voulez également rajouter des images, des fichiers CSS ? Aller voir dans la FAQ pour les explications mais il suffit de placer les fichiers statiques que vous voulez fournir dans un répertoire nommé www que vous placerez de cette façon : 📁 votre_dossier_par_exemple_site_dynamique 📄 code_serveur.py 📄 configuration.py 📁 www 📄 turing.jpg 📄 monstyle.css 📄 monscript.js 📄 mapage.html Si vous voulez fournir l'image turing.jpg, il suffit alors de taper ceci : requete.repondre("<p><img src='turing.jpg'></p>") Comme vous le voyez, pas d'adresse absolue : le serveur est configuré pour aller chercher de base dans ce répertoire. Il suffit donc de donner le nom des fichiers. 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 elif chemin == '/formulaire':
codeHTML = f"""
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<form action ="/voir_post" method ="post">
<p>
<select name="question">
<option value="addition">table addition</option>
<option value="multiplication">table multiplication</option>
</select>
</p>
<p><input type="number" name="numero" value=0 min="0" max="10" step="1" ></p>
<p><input type="text" name="remarque" textholder="A remplir si vous avez une question à me poser !">
<p><input type ="submit" value="Submit" ></p>
</form>
</body>
</html>'''
requete.creer_entete(200)
requete.repondre(codeHTML)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 elif chemin == '/formulaire':
codeHTML = f"""
<!DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<form action ="/voir_post" method ="post">
<p>
<select name="question">
<option value="addition">table addition</option>
<option value="multiplication">table multiplication</option>
</select>
</p>
<p><input type="number" name="numero" value=0 min="0" max="10" step="1" ></p>
<p><input type="text" name="remarque" textholder="A remplir si vous avez une question à me poser !">
<p><input type ="submit" value="Submit" ></p>
</form>
</body>
</html>'''
requete.creer_entete(200)
requete.repondre(codeHTML)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 codeHTML = f"""
<DOCTYPE html>
<html>
<body>
<h1>Page d'information</h1>
<p>Requete POST reçue par le serveur : {chaine_requete}</p>
<p>Voici le contenu des paramètres</p>"""
for cle, valeur in parametres.items():
codeHTML = codeHTML + f'<p>{cle} valant {valeur}</p>'
codeHTML = codeHTML + """
</body>
</html>
"""
requete.creer_entete(200)
requete.repondre(codeHTML)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def reponse_a_POST(requete):
"""Instructions à effectuer si la requête est de type POST. requete contient les infos sur la requête"""
print("::: SERVEUR ::: Reception d'une requête POST")
# 1 - Récupération optionnelle des informations issues de la requête
chaine_requete = requete.requestline
adresse_client = requete.obtenir_IP_client
port_client = requete.obtenir_PORT_client
chemin = requete.obtenir_chemin
parametres = requete.obtenir_parametres
# 2 - Traitement de la requête
valeur = parametres['numero']
codeHTML = f"""
<DOCTYPE html>
<html>
<body>
<h1>Page des {parametres['question']}</h1>
<p>Requete POST reçue par le serveur : {chaine_requete}</p>
<p>Voici la table voulue</p>"""
if parametres['question'] == 'multiplication':
for x in range(1,11,1):
codeHTML = codeHTML + f'<p>{x} x {valeur} = {x*valeur}</p>'
elif parametres['question'] == 'addition':
pass
codeHTML = codeHTML + """
</body>
</html>
"""
requete.creer_entete(200)
requete.repondre(codeHTML)
4 - FAQ
Pourquoi tout le monde est gentil ?
Vous avez peut-être eu un problème sur la question où il faut détecter les gentils et les méchants.
Beaucoup de gens écrivent ceci :
1 | if parametres['nom'] == 'luke' or 'yoda':
|
Or, ça, c'est toujours vrai. Pourquoi ?
On teste deux conditions avec un OU. Si l'une est vraie au moins, on répond VRAI. Ok
Quels sont les deux tests :
parametres['nom'] == 'luke'- OU
'yoda'
Le problème vient de la deuxième partie : ça veut dire quoi évaluer l'expression 'yoda', juste 'yoda' ?
Et bien, ça revient à tester ceci :
1 | if parametres['nom'] == 'luke' or 'yoda' == True:
|
Or, en Python, False est codé par un contenu vide ou égal à 0. Du coup, comme le string 'yoda' n'est pas vide, l'expression de droite sera toujours évaluée à True.
Et comme c'est un OU, l'expression totale sera également TOUJOURS True.
La bonne façon d'écrire le test est donc :
1 | if parametres['nom'] == 'luke' or parametres['nom'] == 'yoda':
|
Et on peut fournir des fichiers css, js ect... ?
Oui. Vous pouvez demander à notre serveur primitif de délivrer des fichiers statiques. Ils doivent alors se trouver dans un dossier nommé www, pour exprimer le fait que les utilisateurs peuvent accéder en lecture librement à ce qu'on y place.
📁 votre_dossier_par_exemple_site_dynamique
📁 www
📄 turing.jpg
📄 monstyle.css
📄 monscript.js
📄 mapage.html
Attention, lorsque vous donnez l'adresse des documents à télécharger, il ne faut pas préciser le www dans l'adresse : le serveur va aller chercher tout seul comme un grand dans ce dossier. Exemple ci-dessous :
13
14
15
16
17
18
19
20
21
22
23
24 | # 2 - Traitement de la requête
if chemin == '/':
requete.creer_entete(200) # Mise en place de l'en-tête HTML
requete.repondre("<!DOCTYPE html>") # Création de la réponse HTML
requete.repondre("<html>")
requete.repondre("<head><script src='test.js'></script></head>")
requete.repondre("<body>")
requete.repondre("<h1>Ceci est ma superbe page d'accueil</h1>")
requete.repondre("<p><img src='turing.jpg'></p>")
requete.repondre(f"<p>Heure actuelle : {datetime.now().hour} h {datetime.now().minute} min</p>")
requete.repondre("</body>")
requete.repondre("</html>")
|
Voici un exemple de page dynamique intégrant des demandes de ce type :
Mais vous pouvez aussi fournir des pages HTML purement statiques du coup;:
Voici le contenu d'une page HTML statique qu'on pourra obtenir en tapant l'URL http://localhost:9000/mapage.html. Encore une fois, attention : on ne précise pas le WWW : c'est juste qu'il faut placer vos fichiers statiques dans ce dossier.
📁 votre_dossier_par_exemple_site_dynamique
📁 www
📄 turing.jpg
📄 monstyle.css
📄 monscript.js
📄 mapage.html
1
2
3
4
5
6
7
8
9
10
11 | <!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href='monstyle.css' />
<script scr="test.js"></script>
</head>
<body>
<p>Une page statique directement transmise par le serveur, sans traitement particulier.</p>
<p><img src="turing.jpg"></p>
</body>
</html>
|
5 - QCM de fin de première
Activité publiée le 25 03 2020
Dernière modification : 25 03 2020
Auteur : ows. h.