1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
400
401
402
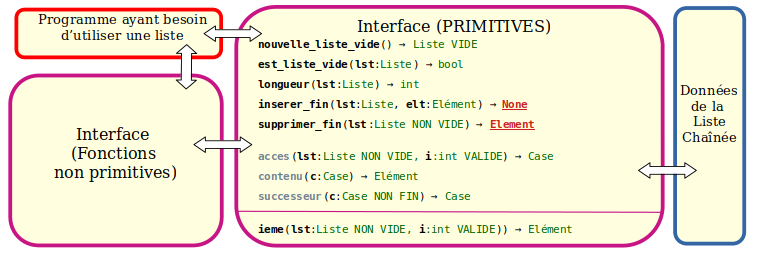
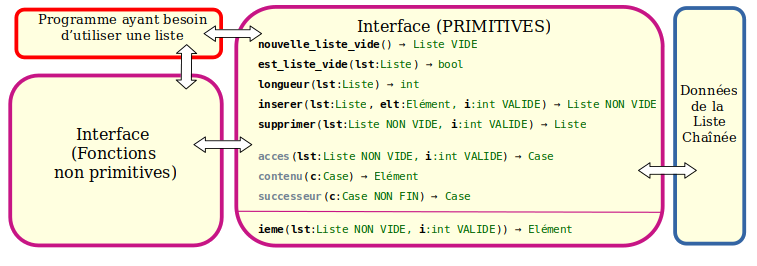
| """INTERFACE d'une structure de données IMMUABLE Liste Contiguë
Description des types non natifs utilisés dans les fonctions
+ Element : le type des éléments disponibles dans votre Liste si elle est homogène.
+ Case : la référence d'une case : un tuple (Liste, indice)
+ Liste : la référence d'un tableau statique
Opérations primitives de la Liste contiguë
------------------------------------------
+ CST O(1) nouvelle_liste_vide() -> Liste VIDE
+ CST O(1) est_liste_vide(lst:Liste) -> bool
+ CST O(1) longueur(lst:Liste) -> int
+ CST O(1) ieme(lst:Liste NON VIDE, i:int VALIDE) -> Elément
+ LIN θ(n) inserer(lst:Liste, elt:Element, i:int) -> Liste NON VIDE
+ LIN θ(n) supprimer(lst:Liste NON VIDE, i:int) -> Liste
+ CST O(1) acces(lst:Liste NON VIDE, i:int VALIDE) -> Case
+ CST O(1) contenu(c:Case) -> Element
+ CST O(1) successeur(c:Case NON FIN) -> Case
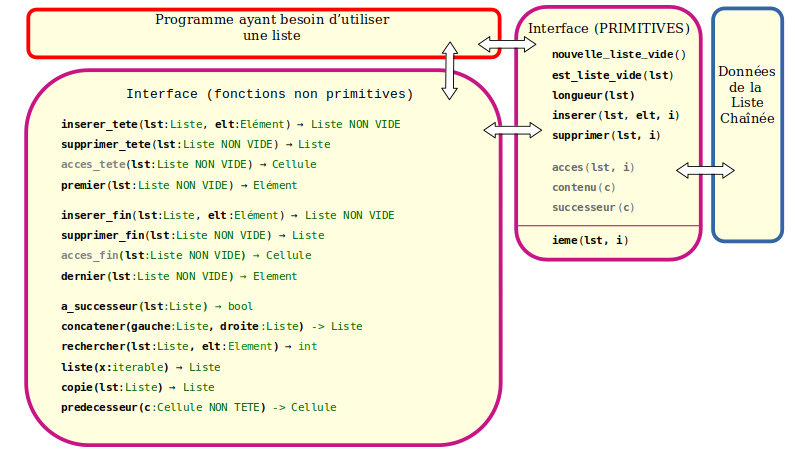
Fonctions d'interface supplémentaires
-------------------------------------
+ LIN θ(n) inserer_tete(lst:Liste, elt:Element) -> Liste NON VIDE
+ LIN θ(n) supprimer_tete(lst:Liste NON VIDE) -> Liste
+ CST O(1) acces_tete(lst:Liste NON VIDE) -> Case
+ CST O(1) premier(lst:Liste NON VIDE) -> Element
+ LIN θ(n) inserer_fin(lst:Liste, elt:Element) -> Liste NON VIDE
+ LIN θ(n) supprimer_fin(lst:Liste NON VIDE) -> Liste
+ CST O(1) acces_fin(lst:Liste NON VIDE) -> Case
+ CST O(1) dernier(lst:Liste NON VIDE) -> Element
+ LI θ(ng+nd) concatener(gauche:Liste, droite:Liste) -> Liste
+ LIN O(n) rechercher(lst:Liste, elt:Element) -> int
+ representer_liste(lst:Liste) -> str
+ LIN θ(n) liste(x:list|tuple|int|float|str) -> Liste
+ LIN θ(n) copier(lst:Liste) -> Liste
+ CST O(1) predecesseur(c:Case NON TETE) -> Case
"""
# Importation : aucune
# Déclaration des CONSTANTES : aucune
# Déclaration des opérations primitives
def nouvelle_liste_vide() -> 'Liste VIDE':
"""Renvoie une liste vide"""
return []
def est_liste_vide(lst:'Liste') -> bool:
"""Prédicat qui renvoie True si la liste est vide"""
return lst == []
def longueur(lst:'Liste') -> int:
"""Renvoie le nombre d'éléments stockés dans lst"""
return len(lst)
def ieme(lst:'Liste NON VIDE', i:'int VALIDE') -> 'Element':
"""Renvoie le contenu de la Case de position i VALIDE dans la liste NON VIDE lst"""
return lst[i]
def inserer(lst:'Liste', elt:'Elément', i:'int VALIDE') -> 'Liste NON VIDE':
"""Renvoie une Liste basée sur lst où elt est en position VALIDE i"""
nb = len(lst) + 1
nouveau = [None for _ in range(nb)] # 1 - nouveau tableau avec une case en plus
for k in range(0, i): # 2 - copie les éléments des indices 0 à i-1 sans décalage
nouveau[k] = lst[k]
for k in range(i, len(lst)): # 3 - décalage à droite des éléments d'indice i et plus
nouveau[k+1] = lst[k]
nouveau[i] = elt # 4 - elt à la position i
return nouveau
def supprimer(lst:'Liste NON VIDE', i:'int VALIDE') -> 'Liste':
"""Renvoie une Liste basée sur lst NON VIDE en supprimant la case i"""
nb = len(lst) - 1
nouveau = [None for _ in range(nb)] # 1 - nouveau tableau avec une case en moins
for k in range(0, i): # 2 - copie les éléments des indices 0 à i-1 sans décalage
nouveau[k] = lst[k]
for k in range(i+1, len(lst)): # 3 - décalage à gauche des éléments d'indice i+1 et plus
nouveau[k-1] = lst[k]
return nouveau
def acces(lst:'Liste NON VIDE', i:'int VALIDE') -> 'Case':
"""Renvoie la référence de la case d'indice i dans la liste lst NON VIDE"""
return (lst, i) # on crée un tuple-case (quelle liste ?, quel indice ?)
def contenu(c:'Case') -> 'Elément':
"""Renvoie le contenu de la case valide fournie"""
lst = c[0] # on récupère la liste contenant notre case
i = c[1] # on récupère l'indice de notre case
return lst[i] # on renvoie l'élément stocké à cet endroit
def successeur(c:'Case NON FIN') -> 'Case':
"""Renvoie le case qui succède à la case fournie (qui ne doit pas être la dernière)"""
lst = c[0] # on récupère la liste contenant notre case
i = c[1] # on récupère l'indice de notre case
return (lst, i+1) # on crée un tuple-case correspond à la case suivante
# Déclaration des fonctions d'interface supplémentaires
def inserer_tete(lst:'Liste', elt:'Elément') -> 'Liste NON VIDE':
"""Renvoie une Liste basée sur lst où elt est en Tête"""
return inserer(lst, elt, 0)
def supprimer_tete(lst:'Liste NON VIDE') -> 'Liste':
"""Renvoie une Liste basée sur lst NON VIDE en supprimant la Tête"""
return supprimer(lst, 0)
def acces_tete(lst:'Liste NON VIDE') -> 'Case':
"""Renvoie la référence de la case de tête dans lst NON VIDE"""
return acces(lst, 0)
def insererFin(lst:'Liste', elt:'Elément') -> 'Liste NON VIDE':
"""Renvoie une Liste basée sur lst où elt est en Fin"""
return inserer(lst, elt, longueur(lst))
def supprimerFin(lst:'Liste NON VIDE') -> 'Liste':
"""Renvoie une Liste basée sur lst NON VIDE en supprimant la fin"""
return supprimer(lst, longueur(lst) - 1)
def accesFin(lst:'Liste NON VIDE') -> 'Case':
"""Renvoie la référence de la case de fin dans lst NON VIDE"""
return acces(lst, longueur(lst) - 1)
def premier(lst:'Liste NON VIDE') -> 'Element':
"""Renvoie la valeur de tête de lst NON VIDE"""
return ieme(lst, 0)
def dernier(lst:'Liste NON VIDE') -> 'Element':
"""Renvoie la valeur de fin de lst NON VIDE"""
return ieme(lst, longueur(lst) - 1)
def representer_liste(lst:'Liste') -> str:
"""Renvoie une représentation de la Liste sous forme d'une séquence commençant par la tête"""
return str(lst).replace(',',' -> ').replace('[','').replace(']','')
def concatener(gauche:'Liste', droite:'Liste') -> 'Liste':
"""Renvoie une nouvelle liste commençant par la tête de gauche vers la fin de droite"""
nouveau = nouvelle_liste_vide() # 1 - nouvelle liste pour la concaténation
ng = longueur(gauche)
for i in range(ng): # 2 - on copie les éléments de gauche
nouveau = inserer(nouveau, ieme(gauche, i), i)
nd = longueur(droite)
for i in range(nd): # 3 - on copie les éléments de droite
nouveau = inserer(nouveau, ieme(droite, i), ng + i)
return nouveau
def concatener_version_primitive(gauche:'Liste', droite:'Liste') -> 'Liste':
"""Renvoie une nouvelle liste commençant par la tête de gauche vers la fin de droite"""
nb = len(gauche) + len(droite)
nouveau = [None for _ in range(nb)] # 1 - nouveau tableau avec autant de cases que les deux autres
for i in range(0, len(gauche)): # 2 - on copie les éléments de gauche
nouveau[i] = gauche[i]
ng = len(gauche) # on récupère le nb d'élémnets à gauche
for i in range(0, len(droite)): # 3 - on copie les éléments de droite
nouveau[ng+i] = droite[i]
return nouveau
def rechercher(lst:'Liste', elt:'Element') -> int:
"""Renvoie la position éventuelle de elt dans lst, -1 si non trouvé"""
for i in range(longueur(lst)): # Pour chaque indice valide de la liste lst
if ieme(lst, i) == elt: # si la case i contient l'élément cherché
return i # répondre en renvoyant l'indice de la case
return -1 # si on arrive ici, c'est qu'on a pas trouvé
def liste(x) -> 'Liste':
"""Renvoie une liste générée à partir de x"""
nouvelle = nouvelle_liste_vide()
if type(x) == list or type(x) == tuple:
for i in range(len(x)-1, -1, -1):
nouvelle = [v for v in x]
elif type(x) == dict:
for couple in dict.items():
nouvelle = inserer_tete(nouvelle, couple)
elif type(x) == int or type(x) == float or type(x) == str or type(x) == bool:
nouvelle = inserer_tete(nouvelle, x)
return nouvelle
def copie(lst:'Liste') -> 'Liste':
"""Renvoie une copie peu profonde de la liste lst envoyée"""
return [v for v in lst]
def predecesseur(c:'Case NON TETE') -> 'Case':
"""Renvoie le case qui précède la case fournie (qui ne doit pas être la première)"""
lst = c[0] # on récupère la liste contenant notre case
i = c[1] # on récupère l'indice de notre case
return (lst, i-1) # on crée un tuple-case correspond à la case précédente
# Instructions du programme principal
if __name__ == '__main__':
# Ces fonctions ne seront en mémoire qu'en lancement direct
def tester_inserer_tete():
a = nouvelle_liste_vide()
a = inserer_tete(a, 5)
assert a == [5]
a = inserer_tete(a, 2)
assert a == [2, 5]
b = inserer_tete(a, 20)
assert a == [2, 5]
assert b == [20, 2, 5]
print('Test OK pour inserer_tete()')
def tester_supprimer_tete():
a = nouvelle_liste_vide()
a = inserer_tete(a, 5)
a = inserer_tete(a, 2)
b = supprimer_tete(a)
assert a == [2, 5]
assert b == [5]
c = supprimer_tete(b)
assert est_liste_vide(c)
print('Test OK pour supprimer_tete()')
def tester_acces_tete():
a = nouvelle_liste_vide()
a = inserer_tete(a, 5)
a = inserer_tete(a, 2)
assert acces_tete(a) == ([2, 5], 0)
print('Test OK pour acces_tete()')
def tester_contenu():
a = nouvelle_liste_vide()
a = inserer_tete(a, 5)
b = inserer_tete(a, 2)
assert contenu(acces_tete(a)) == 5
assert contenu(acces_tete(b)) == 2
print('Test OK pour contenu()')
def tester_successeur():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
d = inserer_tete(c, 20)
assert successeur(acces_tete(d)) == ([20, 2, 5], 1)
assert successeur(acces_tete(c)) == ([2, 5], 1)
print('Test OK pour successeur()')
def tester_longueur():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
assert longueur(a) == 0
assert longueur(b) == 1
assert longueur(c) == 2
print('Test OK pour longueur()')
def tester_acces():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
assert acces(b, 0) == ([5], 0)
assert acces(c, 0) == ([2, 5], 0)
assert acces(c, 1) == ([2, 5], 1)
print('Test OK pour acces()')
def tester_ieme():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
assert ieme(b, 0) == 5
assert ieme(c, 0) == 2
assert ieme(c, 1) == 5
print('Test OK pour lire()')
def tester_inserer():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
d = inserer(c, 20, 1)
assert d == [2, 20, 5]
print('Test OK pour inserer()')
def tester_supprimer():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
d = inserer(c, 20, 1)
e = supprimer(d, 2)
assert d == [2, 20, 5]
assert e == [2, 20]
print('Test OK pour supprimer()')
def tester_concatener():
a = nouvelle_liste_vide()
b1 = inserer_tete(a, 5)
b2 = inserer_tete(b1, 2)
b3 = inserer_tete(b2, 50)
c1 = inserer_tete(a, 20)
c2 = inserer_tete(c1, 200)
d = concatener(b3, c2)
assert d == [50, 2, 5, 200, 20]
print('Test OK pour concatener()')
def tester_rechercher():
a = nouvelle_liste_vide()
b = inserer_tete(a, 5)
c = inserer_tete(b, 2)
d = inserer(c, 20, 1)
assert rechercher(d, 30) == -1
assert rechercher(d, 20) == 1
assert rechercher(d, 2) == 0
assert rechercher(d, 5) == 2
print('Test OK pour rechercher()')
def tester(): # Tous les tests
tester_inserer_tete()
tester_supprimer_tete()
tester_acces_tete()
tester_contenu()
tester_successeur()
tester_longueur()
tester_acces()
tester_ieme()
tester_inserer()
tester_supprimer()
tester_concatener()
tester_rechercher()
print("Module lancé directement, il ne s'agit pas d'une importation")
tester()
|
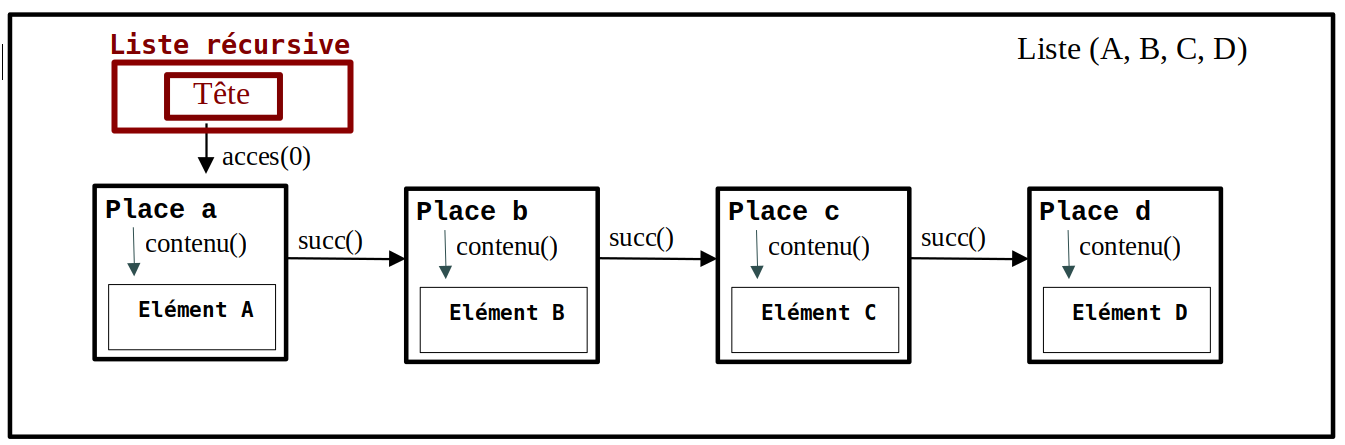
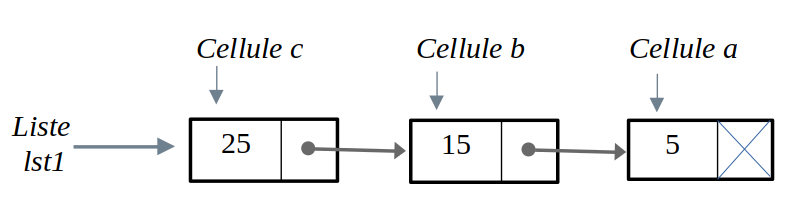
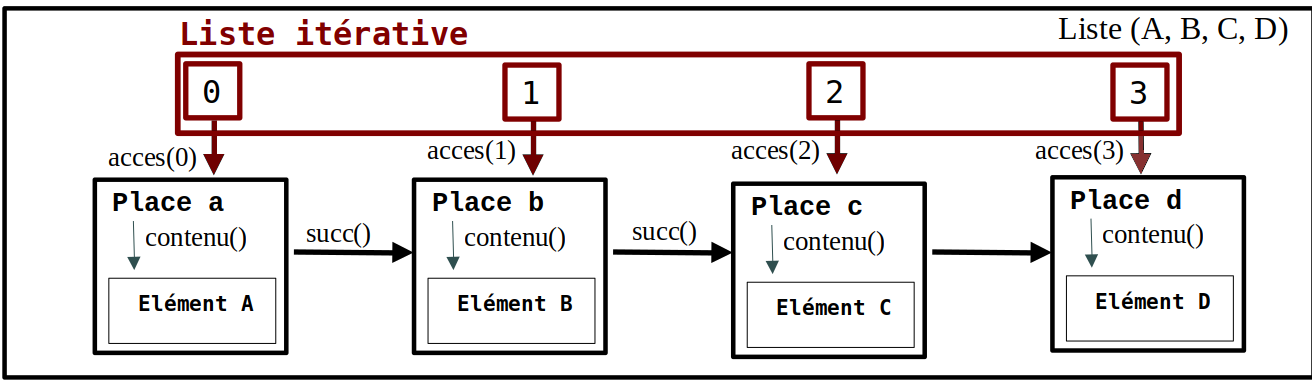













 formule 1'
formule 1'