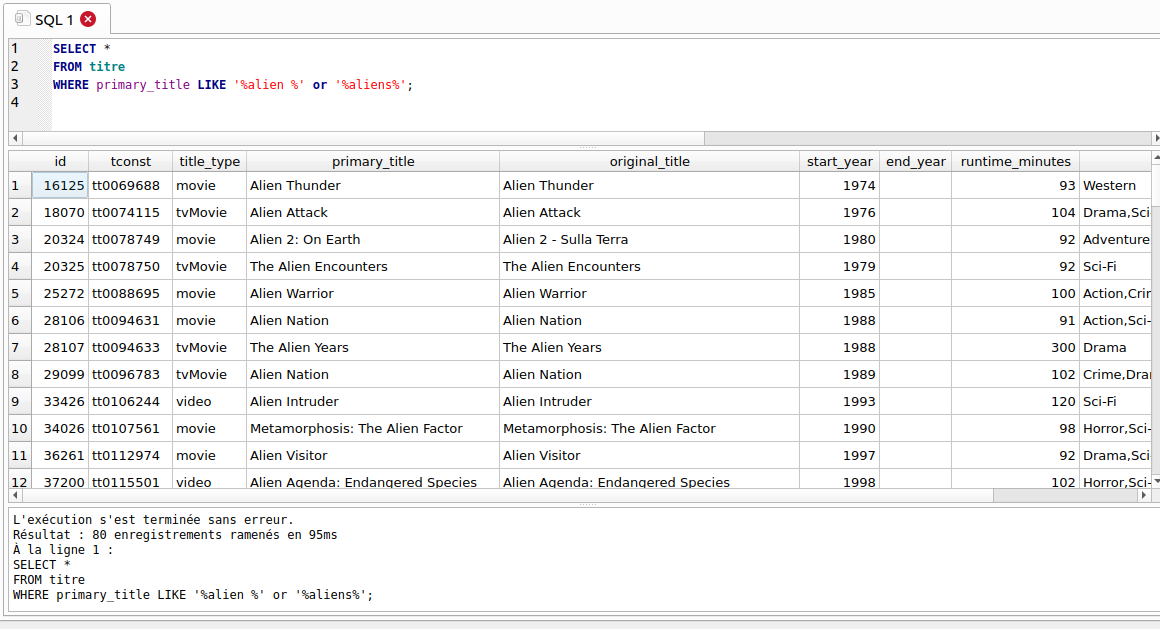
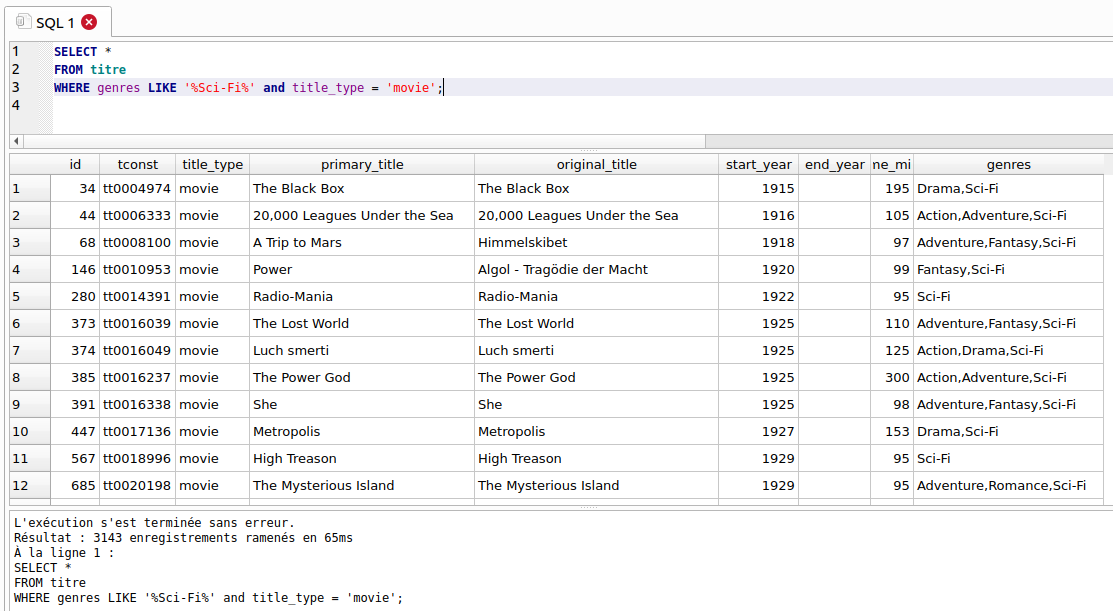
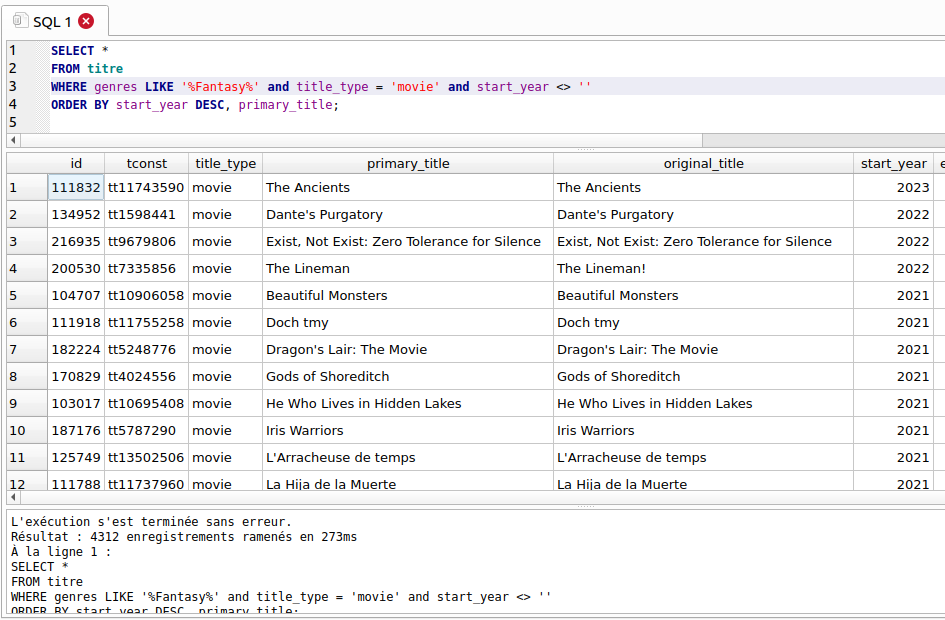
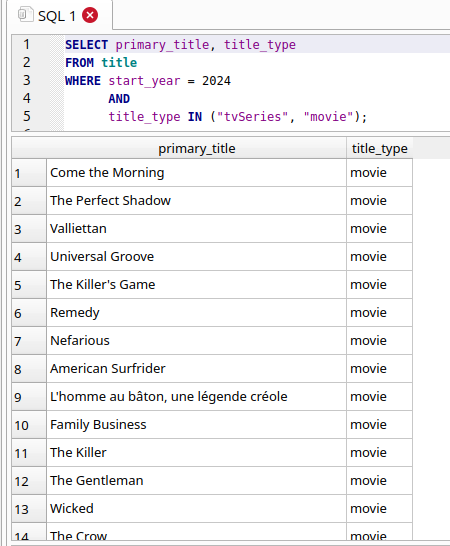
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| # Déclaration des fonctions
def projeter(table:list[dict], attributs_voulus:list[str]) -> list[dict]:
"""Projette les attributs voulus dans la table fournie"""
projection = [] # Création d'un tableau dynamique
for nuplet in table: # pour chaque n-uplet de la table
copie_nuplet = {} # nouveau n-uplet nommé qui va stocker la réponse partielle
for cle, valeur in nuplet.items(): # pour chaque clé et valeur associée dans le n-uplet de la table
if cle in attributs_voulus: # si le nom de la clé apparait dans le tableau des attribus voulus
copie_nuplet[cle] = valeur # on rajoute cette association clé-valeur dans la projection
projection.append(copie_nuplet) # on rajoute le nouveau n-uplet dans la projection
return projection # on renvoie le tableau contenant les copies tronquées des n-uplets
def uniquement_plateformes(table:list[dict]) -> list[dict]:
"""Filtre les n-uplets de la table en ne renvoyant que ceux dont le genre est bien plateformes"""
reponse = [] # Création d'un tableau dynamique
for nuplet in table: # pour chaque n-uplet de la table
if nuplet['genre'] == 'Plate-formes': # si le genre de ce n-uplet est un jeu de plate-formes
copie_nuplet = {} # va permettre de copier les dictionnaires (qui sont fortement muables)
for cle, valeur in nuplet.items(): # pour chaque cle-valeur associée dans le n-uplet à garder
copie_nuplet[cle] = valeur # on copie la même chose dans le dictionnaire de copie
reponse.append(copie_nuplet) # on rajoute la copie dans notre tableau de réponse
return reponse # on renvoie le tableau contenant les copies des n-uplets voulus
# PROGRAMME DE TEST
if __name__ == '__main__':
jeu = [
{'id':7, 'jeu':'Flight Simulator',
'description':"Simulation d'avion", 'sortie':1980,
'éditeur':'subLOGIC', 'genre':'Simulateur', 'id_support':1},
{'id':8, 'jeu':'DONKEY KONG',
'description':"Un méchant singe géant", 'sortie':1981,
'éditeur':'Nintendo', 'genre':'Plate-formes', 'id_support':None},
{'id':9, 'jeu':'PIFALL!',
'description':"Pitfall Harry, un explorateur", 'sortie':1982,
'éditeur':'Activision', 'genre':'Plate-formes', 'id_support':2},
{'id':10, 'jeu':'PIFALL!',
'description':"Pitfall Harry, un explorateur", 'sortie':1983,
'éditeur':'Nintendo', 'genre':'Plate-formes', 'id_support':3},
{'id':11, 'jeu':'Boulder Dash',
'description':"Rockford, mineur téméraire", 'sortie':1983,
'éditeur':'First Star Software', 'genre':'Plate-formes', 'id_support':3}
]
console = [
{'c_id':1, 'c_nom':'Apple II', 'c_RAM':'4 ko', 'c_date_sortie':'1977-06-10'},
{'c_id':2, 'c_nom':'Atari 2600', 'c_RAM':'4 ko', 'c_date_sortie':'1977-10-14'},
{'c_id':3, 'c_nom':'C64', 'RAM':'c_64 ko', 'c_date_sortie':'1982-08-01'}
]
print("Exemple de projection")
nouvelle_table = projeter(jeu, ['jeu', 'description'])
for nuplet in nouvelle_table: # pour chaque n-uplet de la jointure
print(nuplet) # affiche ce n-uplet
print("\n\nExemple de filtrage")
nouvelle_table = uniquement_plateformes(jeu)
for nuplet in nouvelle_table: # pour chaque n-uplet de la jointure
print(nuplet) # affiche ce n-uplet
|