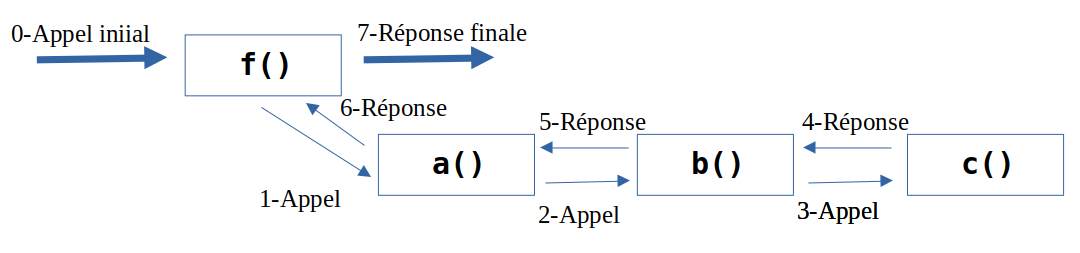
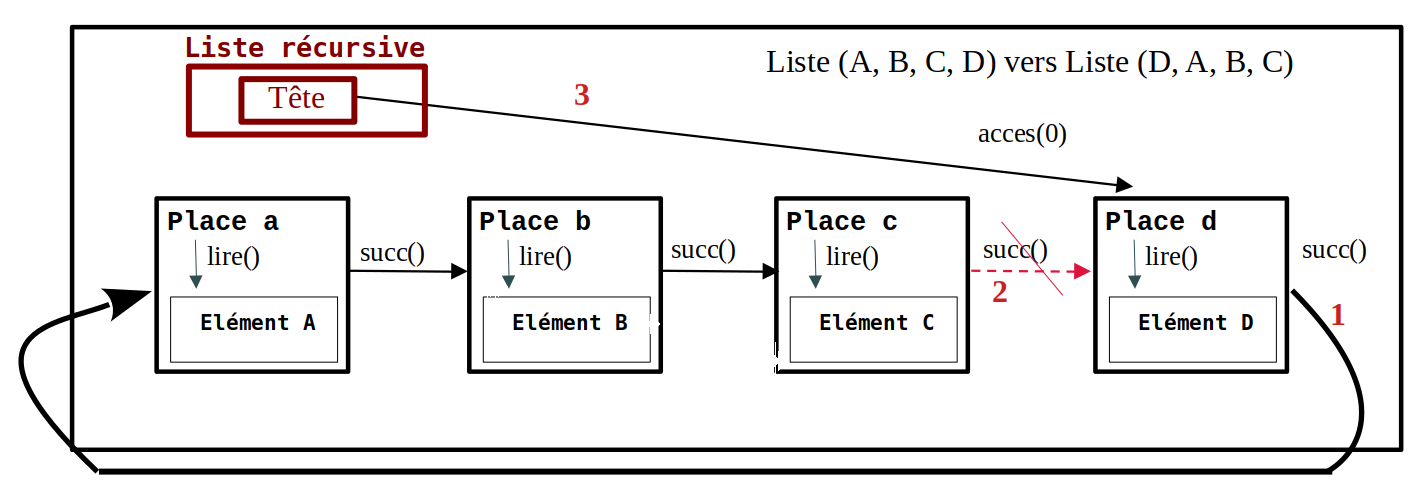
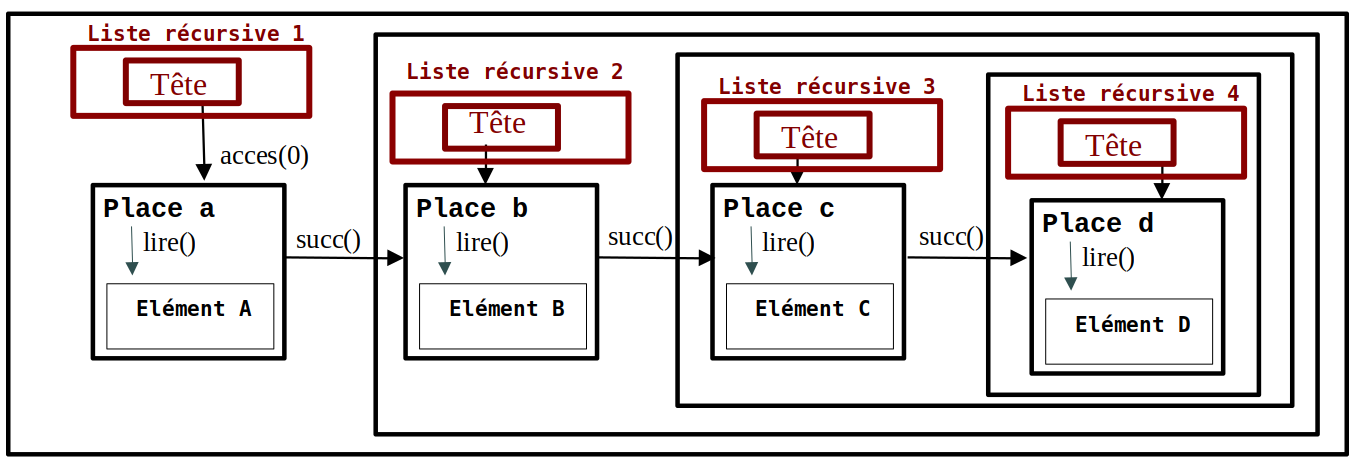
- nLV() ou nouvelleListeVide() → Liste VIDE
Renvoie une nouvelle Liste VIDE initialement.
- estLV() ou estListeVide(lst:Liste) → Booléen
Prédicat qui renvoie VRAI si la liste lst fournie est vide, FAUX sinon.
- ins() ou inserer(lst:Liste, elt:Elément, ...) → Liste NON VIDE
Renvoie une nouvelle Liste comportant le nouvel élément à une position choisie. Certaines valeurs seront donc décalées par rapport à la Liste initiale.
POSTCONDITIONS : la Liste renvoyée est NON VIDE et possède un emplacement en plus mais lst est inchangée.
Voici plusieurs versions qui pourraient convenir, la première étant la plus générique :
ins() ou inserer(lst:Liste, elt:Elément, i:Entier Naturel VALIDE) → Liste NON VIDE
Renvoie une nouvelle Liste comportant le nouvel élément à la position indiquée par l'indice fourni.
insT() ou insererTete(lst:Liste, elt:Elément) → Liste NON VIDE
Renvoie une nouvelle Liste où l'élément est placé en tête de liste, provoquant le décalage de tous les autres élements.
Equivalent à un appel à ins() en lui envoyant i=0.
insF() ou insererFin(lst:Liste, elt:Elément) → Liste NON VIDE
Renvoie une nouvelle Liste où l'élément est placé en fin de liste.
Equivalent à un appel à ins() en lui envoyant i=longueur puisque les indices possibles de la liste vont de 0 à longueur-1 avant insertion.
Un appel à ins() en lui envoyant i=longueur-1 veut dire qu'on veut placer l'élément en avant dernière position, l'ancienne fin est toujours la même.
Exemples d'utilisation
lstA = nouvelleListeVide()
lstB = inserer(lstA, 5, 0)
lstB contient alors (5, () ) qu'on pourrait noter (5, VIDE).
lstC = inserer(lstB, 15, 0)
lstC contient alors (15, (5, () )) qu'on pourrait noter (15, 5, VIDE).
lstD = inserer(lstC, 25, 1)
lstD contient alors (15, (25, (5, () ))) qu'on pourrait noter (15, 25, 5, VIDE).
lstE = inserer(lstD, 50, 3)
lstE contient alors (15, (25, (5, (50, () )))) qu'on pourrait noter (15, 25, 5, 50, VIDE).
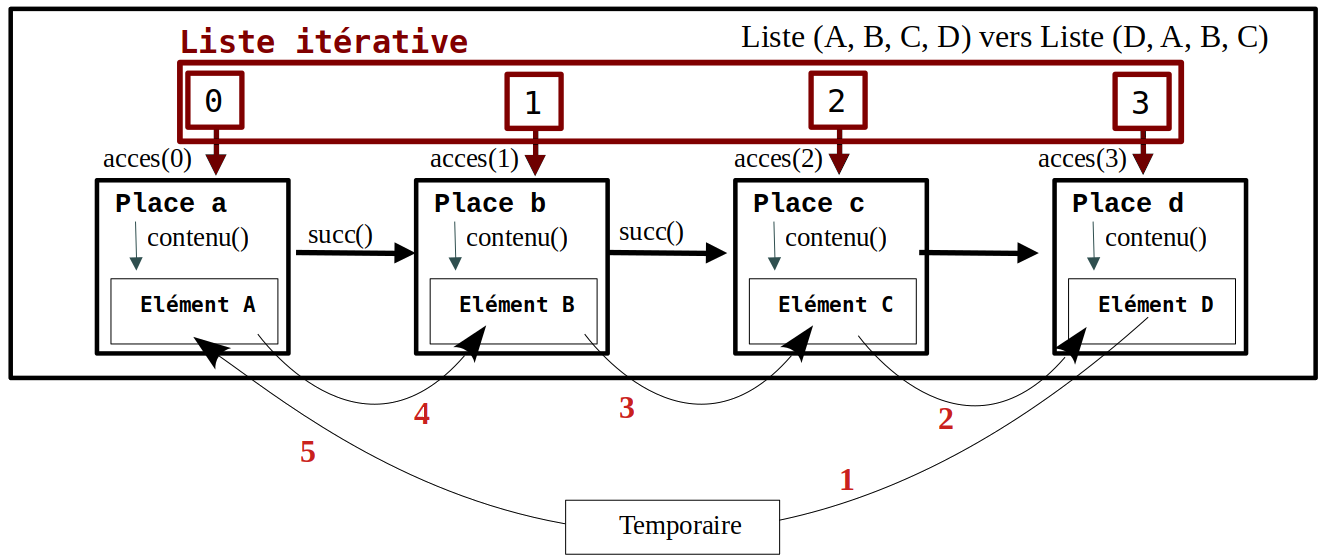
- sup() ou supprimer(lst:Liste NON VIDE, ...) → Liste
Renvoie une nouvelle Liste dans laquelle on a supprimé un emplacement prédéfini dans la Liste NON VIDE reçue. Certains emplacements sont donc décalés d'une position par rapport à la Liste initiale.
PRECONDITION : la Liste reçue est NON VIDE.
POSTCONDITION : la Liste renvoyée possède un emplacement en moins mais lst est inchangée.
Voici plusieurs versions qui pourraient convenir, la première étant la plus générique :
supprimer(lst:Liste NON VIDE, i:Entier Naturel vALIDE) → Liste
Renvoie une nouvelle Liste dans laquelle on a supprimé l'ancien emplacement ayant cet indice.
supT() ou supprimerTete(lst:Liste NON VIDE) → Liste
Renvoie une nouvelle Liste dans laquelle on a supprimé l'ancien emplacement en tête de liste.
Equivalent à un appel à sup() en lui envoyant i=0.
supF() ou supprimerFin(lst:Liste NON VIDE) → Liste
Renvoie une nouvelle Liste dans laquelle on a supprimé l'ancien emplacement en fin de liste.
Equivalent à un appel à sup() en lui envoyant i=longueur-1.
Exemple d'utilisation
Partons de lstE contenant (15, (25, (5, (50, () )))) ou (15, 25, 5, 50, VIDE).
lstF = sup(lstE, 1)
lstF contient alors (15, (5, (50, () ))) ou (15, 5, 50, VIDE).
lstG = sup(lstF, 2)
lstG contient alors (15, (5, () )) ou (15, 5, VIDE).
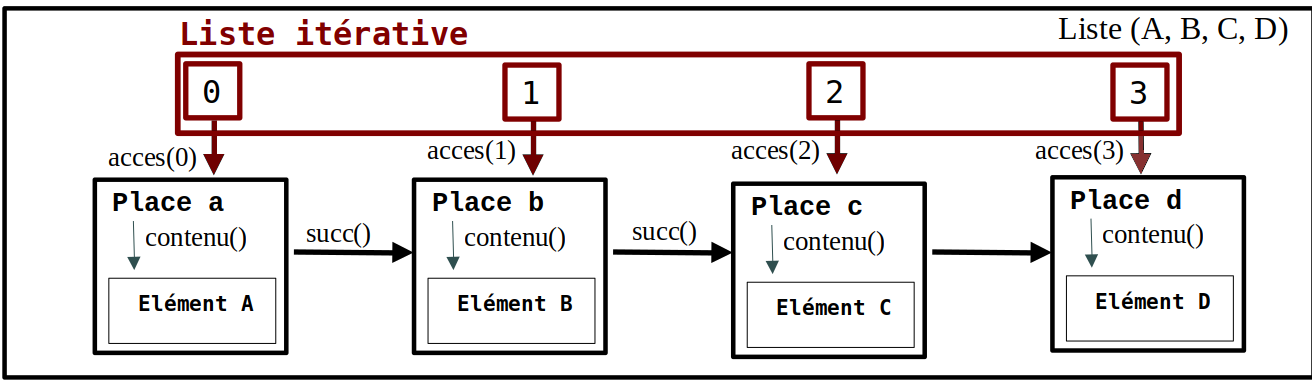
- acc() ou acces(lst:Liste NON VIDE, ...) → Place
Renvoie la Place correspondant à une position définie.
POSTCONDITION : la Liste est inchangée.
Voici plusieurs versions qui pourraient convenir, la première étant la plus générique :
acc() ou acces(lst:Liste NON VIDE, i:Entier Naturel) → Place
Renvoie la Place correspondant à l'indice i fourni.
accT() ou accesTete(lst:Liste NON VIDE) → Place
Renvoie la Place correspondant à la tête.
Equivalent à un appel à acc() en lui envoyant i=0.
accF() ou accesFin(lst:Liste NON VIDE) → Place
Renvoie la Place correspondant à la fin.
Equivalent à un appel à acc() en lui envoyant i=longueur-1.
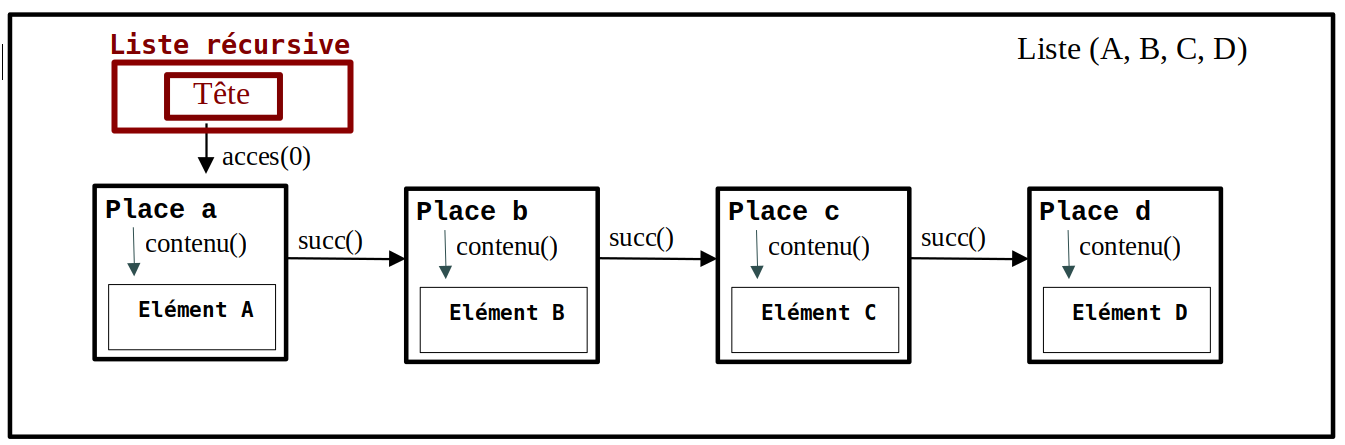
Les deux dernières primitives (numérotées 7 et 8 ici) interagissent directement avec une Place : la connaissance d'une Place doit venir de l'utilisation de acces().
- contenu(plc:Place) → Elément
Renvoie l'Elément référencé par plc.
POSTCONDITION : si la Liste est homogène le type de l'Elément est compatible avec ceux de la Liste.
- succ() ou successeur(plc:Place) → Place|Vide
Renvoie la Place qui succède à plc, ou l'information Vide si elle est la dernière.
Toutes les structures de données qui collent à la définition et qui possèdent ces primitives sont donc des Listes.