22 - Diviser pour régner
L'an dernier, nous avons vu deux moyens de résoudre un problème compliqué :
Moyen n°1 : le premier moyen est la force brute.

- Principe : on y va franchement, on calcule tout, quitte à calculer les choses plusieurs fois, voire à calculer des choses qui ne servent en rien pour trouver la solution.
- Type de problème : tous les problèmes à priori.
Moyen n°2 : le deuxième moyen est de passer par la stratégie gloutonne.
- Principe : on ne regarde pas le problème dans sa totalité. On prend une décision purement locale, de façon définitive et sans se soucier de ce que va devenir le problème restant à traiter. On obtient alors un problème un peu plus petit. On prend une deuxième décision purement locale, qui va encore réduire la taille du problème restant à traiter. Et on continue, en prenant une autre décision locale jusqu'à obtenir une solution à notre grand problème initial.
- Type de problème : ceux pour lesquels on peut trouver plusieurs solutions, optimales ou pas.
Un exemple avec Mr Glouton dont l'objectif est d'aller vers la case en bas à droite en mangeant mal (il préfère la malbouffe salée, sinon la sucrée ça va aussi, et s'il doit vraiment manger des carottes ou de la salade, pourquoi pas...).
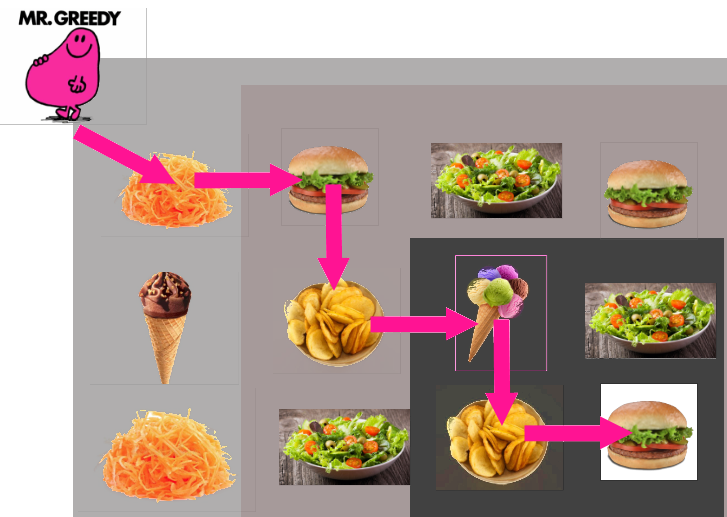
Comme on le voit, la taille du problème à traiter diminue à chaque décision.
Moyen n°3 : aujourd'hui, nous allons voir la stratégie diviser pour régner.
Evaluation ✎ :
Documents de cours : open document ou pdf
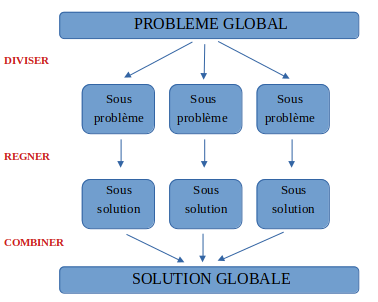
1 - Principe du diviser pour régner
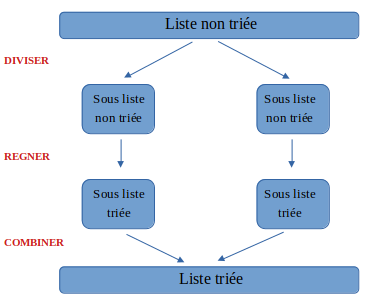
Le principe de cette stratégie est de résoudre le problème selon cette structure :
Diviser pour régner
- Phase DIVISER : on divise le problème global en plusieurs sous-problèmes indépendants les uns des autres ;
- Phase REGNER : on règne sur chaque petit sous-problème, plus petit donc plus facilement gérable ;
- Phase COMBINER : on combine les sous-solutions pour obtenir la solution globale du problème initial.
Différence avec la stratégie gloutonne ?
Deux différences principales :
- Le sens de déroulement
- La stratégie gloutonne réduit définitivement la taille du problème à chaque étape. C'est une méthode HAUT vers BAS.
- La stratégie diviser pour régner réduit la taille du problème puis combine les sous-solutions. C'est une méthode HAUT vers BAS vers HAUT, à cause de la phase COMBINER.
- Le type du problème qu'on tente de résoudre
- La stratégie gloutonne vise à résoudre des problèmes particuliers : ceux pour lesquels il existe beaucoup de solutions dont la qualité est variable : certaines sont optimales, d'autres acceptables et les dernières de "mauvaise qualité". Le problème du voyageur de commerce peut être résolu avec une stratégie gloutonne puisqu'on peut trouver plusieurs chemins entre les différentes villes.
- La stratégie diviser pour régner vise à résoudre des problèmes pour lequel il n'existe qu'une solution. Le problème de la présence d'un élément dans un tableau peut être résolu par une stratégie diviser pour régner puisqu'il n'existe qu'une bonne réponse possible : là ou pas là.
01° Pourquoi la recherche dichotomique fait partie des stratégies diviser pour régner plutôt que des stratégies gloutonnes alors qu'on fait bien un choix local à chaque étape ?
On rappelle ci-dessous le principe de la recherche dichotomique dans un tableau trié si vous avez oublié.
...CORRECTION...
On réduit bien définitivement la taille du problème à chaque étape (on dit oui ou on supprime la partie gauche ou droite) et il n'y a pas vraiment de phase COMBINER. Cela ressemble à du glouton.
Pourquoi est-ce du diviser pour régner ? Simplement car il n'y a qu'une réponse possible et pas plusieurs réponses plus ou moins pertinente.
La recherche par dichotomie est donc bien un algorithme basé sur la stratégie diviser pour régner. C'est même un cas très simple car la phase COMBINER ne combine rien : on peut répondre sans avoir à recombiner les différences réponses.
Algorithme de recherche dichotomique
But : Dans un tableau trié et pour un élément donné, fournir l'indice de la première occurrence trouvée, ou une réponse vide.
Principe : le tableau étant trié, on regarde la valeur centrale dans les indices encore disponibles. S'il ne s'agit pas de la bonne valeur, on peut supprimer de l'intervalle de recherche les indices situés à gauche ou à droite qui ne peuvent pas contenir la valeur.
Description des entrées / sortie
- ENTREES :
- t : un tableau trié contenant un ensemble d'éléments.
- x : l'élément recherché
- SORTIE : vide ou un indice correspondant à x.
Algorithme commenté
Dans l'algorithme ci-dessous, l'opérateur // désigne une division entière.
g ← 0
d ← longueur - 1
TANT QUE g <= d
m ← (g + d) // 2
SI t[m] < x
g ← (m + 1) (* on déplace g pour "supprimer" la partie à gauche *)
SINON SI t[m] > x
d ← (m - 1) (* on déplace d pour "supprimer" la partie à droite *)
SINON
Si on arrive ici, c'est que x est bien à l'indice m
Renvoyer m
Fin du Si
Fin Tant que
Si on arrive ici, c'est que l'intervalle de recherche est vide
Renvoyer VIDE
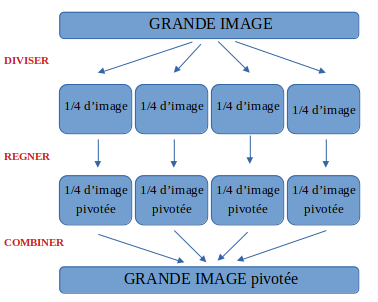
Un exemple de cette stratégie appliquée à la rotation d'une image : on considère qu'on ne sait pas faire de rotation mais uniquement des translations.
- Phase (récursive) DIVISER : on divise l'image en 4 parties jusqu'à obtenir un pixel unique.
- Phase (récursive) REGNER : on sait faire tourner un pixel : il suffit de ne rien faire !
- Phase (récursive) COMBINER : on déplace dans le sens horaire les 4 sous-images et on les combine pour obtenir une nouvelle image plus grande.

Le plus rigolo, c'est qu'on peut placer la translation horaire des 4 sous-images pendant la phase DIVISER. C'est un cas particulier et on perd un peu le principe de ne combiner que pendant la phase COMBINER mais on retrouve un peu le positionnement de l'exploration de la racine lors des trois parcours en profondeur.
- Phase (récursive) DIVISER : on divise l'image en 4 parties et on déplace les 4 parties dans le sens horaire. On effectue cela jusqu'à obtenir un pixel unique.
- Phase (récursive) REGNER : on sait faire tourner un pixel : il suffit de ne rien faire !
- Phase (récursive) COMBINER : on combine 4 sous-images pour obtenir une nouvelle image plus grande.

Diviser pour régner pour faire tourner une image revient donc à se dire qu'on ne sait faire tourner qu'un pixel unique. On parvient donc à régner en divisant l'image en pixels.
Pas de problème pour faire tourner ce pixel bleu de 90° !
Si on doit résumer cela sur un schéma de principe :
Un dernier exemple sur une image réelle on veut faire pivoter Tux, la mascotte de Linux. J'ai utilisé la méthode où la permutation des 4 sous-images en faite dès la phase DIVISER :

On peut
- calculer les nouvelles positions des pixels en faisant un peu de mathématiques, ou
- utiliser la méthode diviser pour régner. Regardez le résultat ci-dessous.
On divise Tux en quatre zones et on les décale simplement dans le sens horaire :
![]()

On divise à nouveau chacune des 4 zones en 16 sous-zones. Et dans chaque zone, on décale les sous-zones dans le sens horaire :
![]()
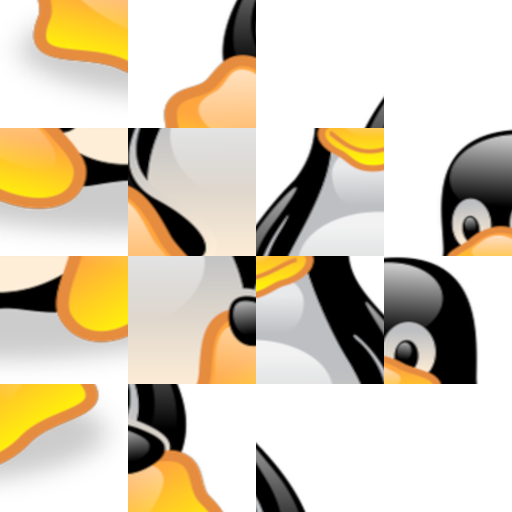
On divise à nouveau chacune des 16 sous-zones en 4, soit 64 sous-sous-zones. Et dans chaque sous-zone, on décale les sous-sous-zones dans le sens horaire :
![]()

Et on continue :
![]()

Et on continue :
![]()

Et on continue :
![]()

Et encore et encore jusqu'à arriver à des sous-zones qui sont constitués uniquement de ... 1 pixel. Du coup, pas plus besoin de faire de rotation. On continue donc :
![]()

Animation finale :

On notera que c'est un exemple très visuel et donc assez pratique pour comprendre la méthode, mais que ce n'est pas efficace en terme de coût ici. On déplace et stocke chaque pixel plusieurs fois avant de lui trouver sa place définitive.
- Le coût en temps n'est pas bon
- Le coût en espace mémoire n'est pas bon non plus.
Il s'agit donc bien d'un exemple pédagogique. Il n'est pas rentable de faire tourner les images comme cela. Dans la réalité, on gère juste cela avec un peu de maths.
2 - Tri fusion, un tri en diviser pour régner
Nous avions vu l'an dernier :
- Le tri par sélection
- un tri à coût quadratique, dont la complexité est 𝞗(n2)
- principe on cherche le minimum dans [0; n-1] et on l'inverse avec la case 0. On cherche ensuite le second minimum dans [1; n-1] et on l'inverse avec la case 1. On continue jusqu'à obtenir un tableau entièrement trié. On peut faire pareil en prenant le maximum et en le plaçant en fin de tableau.
- Le tri par insertion
- un tri à coût quadratique, dont la complexité est 𝓞(n2)
- principe : on crée un tableau d'un seul élément, puis on ramène et place correctement un deuxième élément. On continue jusqu'à ramener tous les éléments, un par un.
Introduction - Principe du tri fusion
Nous allons donc voir le tri fusion qui consiste à
- Phase DIVISER : on divise en deux notre tableau.
- Phase REGNER : on règne sur les deux sous-tableaux en les triant (récursivement au besoin, le cas de base étant un tableau de une case : il est trié !)
- Phase COMBINER : on fusionne alors facilement nos deux tableaux triés : le plus petit élément de chaque tableau est au début du tableau. Trier les éléments des deux tableaux revient à lire deux valeurs à chaque étape, et faire leur comparaison.

Si n et m sont les longueurs des deux tableaux triés, l'étape COMBINER est à coût linéaire (en 𝞗(n+m)).
Si on résume ceci sous forme de schéma de principe :
Passons à un exemple concret :

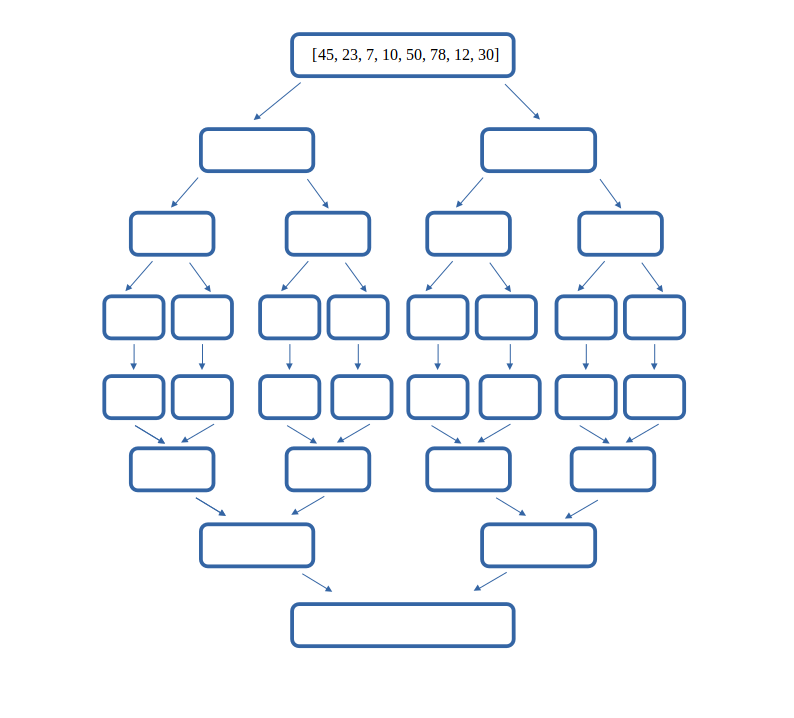
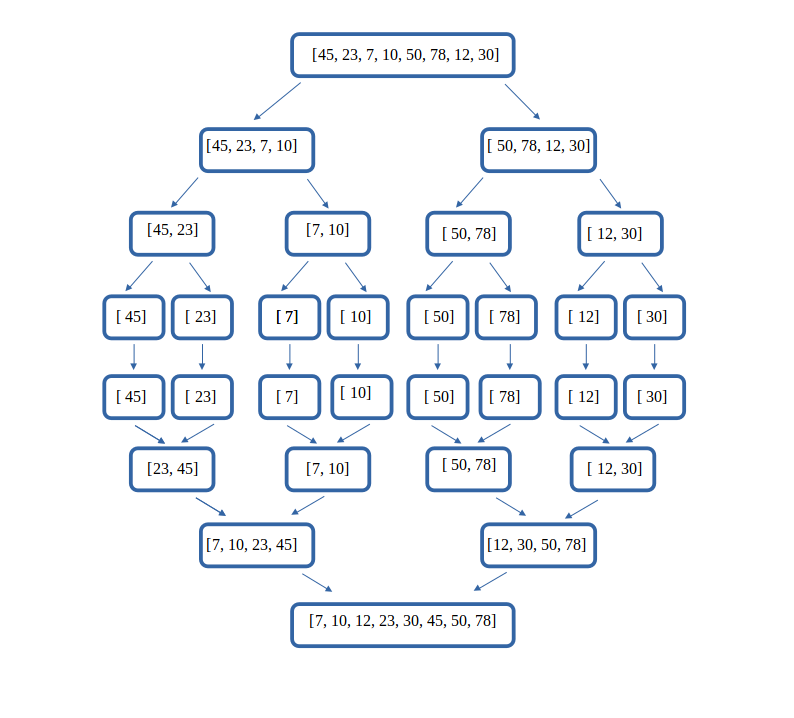
02° Réaliser sur papier le tri fusion du tableau suivant :
[45, 23, 7, 10, 50, 78, 12, 30]
Pour pouvez vous baser sur un schéma de ce type :
...CORRECTION...
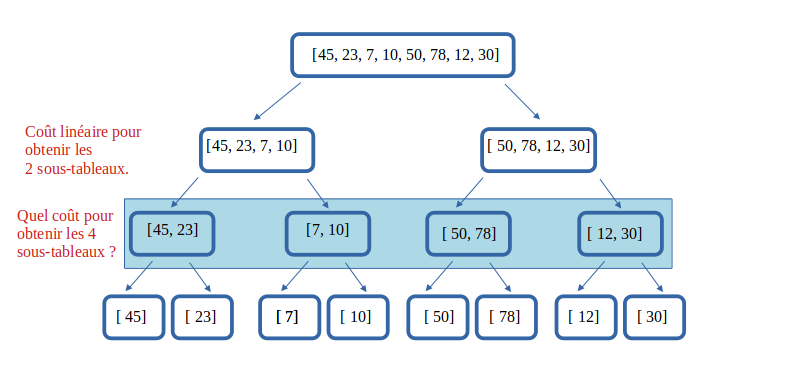
2.1 Coût de la phase DIVISER avec un tableau
03° Quel devrait-être le coût T1 pour obtenir les deux tableaux de l'étage 1 à partir du tableau de l'étage 0, en imaginant le prototype d'une fonction scinder() de ce type :
scinder (t:tableau) -> (tableau, tableau):
On notera n le nombre de cases du tableau initial.
- Constant
- Logarithmique
- Linéaire
- Quadratique
...CORRECTION...
Il va falloir créer deux tableaux à partir du tableau initial.
Il faut donc copier les cases une par une du tableau de taille n vers le bon sous-tableau. D'où un coût linéaire pour T1.
En équation : T1 = 𝞗(n)
04° Quel devrait-être
- le nombre d'opérations nécessaires pour scinder le sous-tableau de gauche comportant n/2 éléments ?
- le nombre d'opérations nécessaires pour scinder le sous-tableau de droite comportant n/2 ?
- le coût T2 de l'opération totale sur cet étage ?
...CORRECTION...
On considére que n est divisible par deux pour simplifier l'explication.
Sur la partie gauche, scinder() demande n//2 opérations.
Sur la partie droite, scinder() demande n//2 opérations.
Sur cet étage, on obtient donc n opérations : coût linéaire par rapport aux n cases du tableau initial.
En équation : T2 = 2*𝞗(n//2) = 𝞗(n)
05° Quel va être le coût T3 des opérations permettant d'obtenir le dernier étage à partir des tableaux de l'avant-dernier étage ?
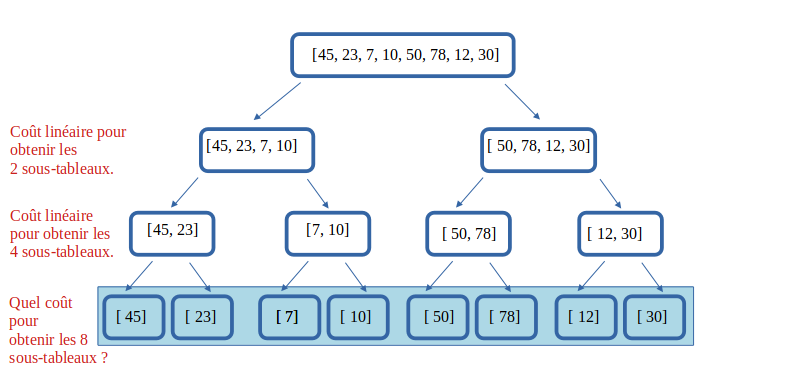
...CORRECTION...
On a 4 tableaux à scinder qui contiennent chacun n//4 éléments.
Scinder chaque tableau est linéaire par rapport à n//4.
On le fait 4 fois, le coût total de cet étage est donc linéaire par rapport à n.
En équation : T3 = 4*𝞗(n//4) = 𝞗(n)
06° Avec notre méthode de scinder en deux, quel est le nombre Ttotal d'opérations nécessaires pour scinder un tableau de 8 cases en 8 tableaux d'une case ?
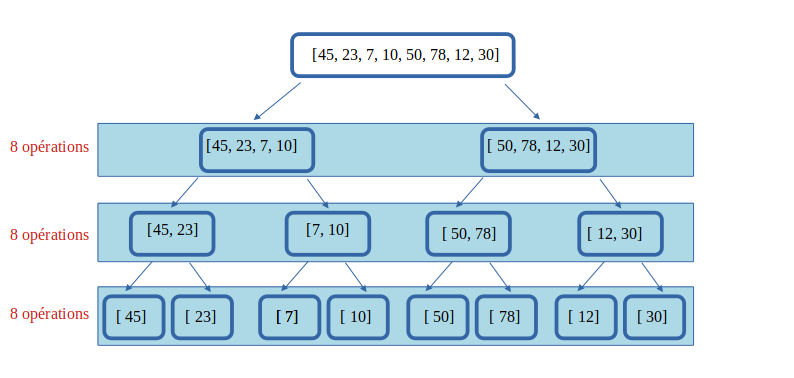
Quel pourraît alors être le coût de cette opération ?
- Logarithmique (avec une complexité en log2(n))
- Linéaire (avec une complexité en n)
- Quasi-linéaire (avec une complexité en n log2(n))
- Quadratique (avec une complexité en n2)
...CORRECTION...
On voit qu'il faut 3*8 soit 24 opérations.
Or, on sait que log2(8) = log2(23) = 3 !
Dans la mesure où on peut écrire que 24 peut être obtenu avec 8*log2(8), la complexité de l'opération de division du tableau en tableaux d'une seule case est quasi-linéaire.
07° Avec notre méthode de scinder en deux, quel est le nombre Ttotal d'opérations nécessaires pour scinder un tableau de 16 cases en 16 tableaux d'une case ?
...CORRECTION...
Il faut 16 opérations par étage et il y aura 4 étages : 64 opérations.
- Etage 1 : on passe de 16 éléments à 8 éléments par tableau.
- Etage 2 : on passe de 8 éléments à 4 éléments par tableau.
- Etage 3 : on passe de 4 éléments à 2 éléments par tableau.
- Etage 4 : on passe de 2 éléments à 1 élément par tableau.
Or, on sait que log2(16) = log2(24) = 4 !
Dans la mesure où on peut écrire que 64 peut être obtenu avec 16*log2(16), la complexité de l'opération de division du tableau en tableaux d'une seule case est quasi-linéaire.
Conclusion sur la phase DIVISER
- chaque appel à la phase DIVISER du tri fusion est à coût linéaire mais
- l'ensemble des appels récursifs à DIVISER provoque un coût quasi-linéaire (en n log2(n)).
2.2 Coût de la phase REGNER
Le coût de la phase REGNER inclut les appels récursifs précédents.
Si on ne s'intéresse qu'au cas de base (case unique), le coût est nul puisqu'on ne fait rien. On peut donc dire que le cas de base est à coût constant.
2.3 Coût de la phase COMBINER
- Phase COMBINER : on fusionne facilement nos deux tableaux triés : le plus petit élément de chaque tableau est au début du tableau. Trier les éléments des deux tableaux revient à lire deux valeurs à chaque étape et faire leur comparaison.
Si n1 et n2 sont les longueurs des deux tableaux triés, une étape COMBINER est à coût linéaire (en 𝞗(n1+n2)).
08° Quel va être le coût T3 de la fusion des deux derniers sous-tableaux en un tableau trié en fonction de n , le nombre de cases du tableau initial ?
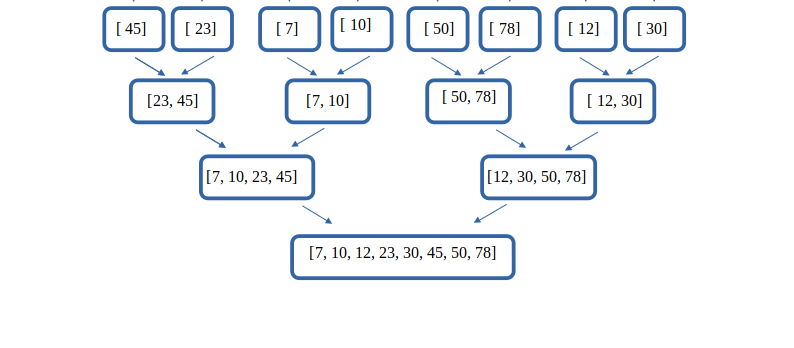
...CORRECTION...
- Chaque sous-tableau contient n//2 éléments.
- On obtient donc T
3 = 𝞗(n1+n2) = 𝞗(n//2 + n//2) = 𝞗(n) si on considère que n est un multiple de 2 pour simplifier l'étude. - Cet étage de fusion est donc effectué à coût linéaire.
09° Quel va être le coût T2 de la fusion des quatre derniers sous-tableaux en deux tableaux triés en fonction de n , le nombre de cases du tableau initial ?
...CORRECTION...
- Nous avons quatre sous-tableaux de n//4.
- On obtient donc T2 = 2 * 𝞗(n//4 + n//4) = 2 * 𝞗(n//2) = 𝞗(n) si on considère que n est un multiple de 4 pour simplifier l'étude.
- Cet étage de fusion est donc effectué à coût linéaire.
10° Combien d'opérations au total pour fusionner les 8 sous-tableaux en un seul tableau trié ?
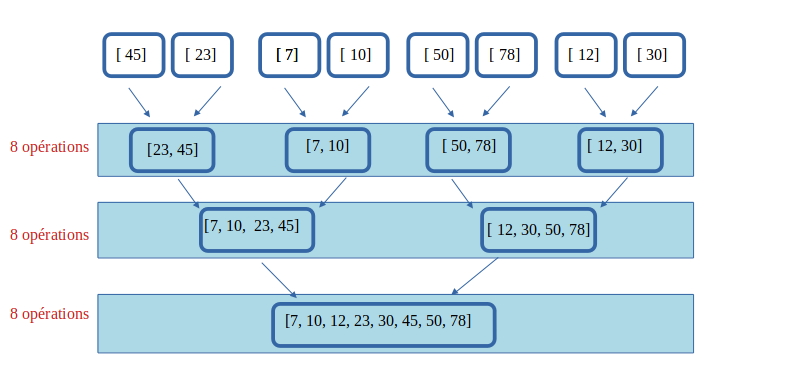
Quel pourraît alors être le coût de cette opération ?
- Logarithmique (avec une complexité en log2(n))
- Linéaire (avec une complexité en n)
- Quasi-linéaire (avec une complexité en n log2(n))
- Quadratique (avec une complexité en n2)
...CORRECTION...
Il faut 8 opérations par étage et il y aura 3 étages. Il faut donc 24 opérations.
Or, on sait que log2(8) = log2(23) = 3
On peut don écrire qu'il faut 8*log2(8) opérations.
La complexité de l'opération de fusion des tableaus en un tableau unique est certainement encore quasi-linéaire.
11° Combien d'opérations au total pour fusionner 16 sous-tableaux en un seul tableau trié ?
...CORRECTION...
16 opérations par étage et 4 étages.
On calcule
- soit 16 * 4 = 64 opérations ;
- soit 16 * log2(16) = log2(24) = 64 opérations.
2.4 Coût du tri fusion sur un tableau
Coût du tri fusion sur un tableau
Lors de l'évaluation des trois phases DIVISER - REGNER - COMBINER, nous avons vu que le coût le plus important est un coût quasi-linéaire.
Le tri fusion est donc à coût quasi-linéaire, en 𝞗(n log2(n))
3 - Tri fusion avec Python
Nous allons travailler avec deux implémentations en tableaux.
Le premier tri fonctionnera en renvoyant un nouveau tableau trié.
Le deuxième tri en modifiant le tableau en place.
Tri fusion renvoyant une copie triée du tableau initial
12° Compléter la fonction fusionner() de façon à implémenter l'algorithme de fusion de deux tableaux statiques triés. Il doit fournir en sortie un nouveau tableau statique trié comportant les éléments des deux précédents.
| t1 = [13, 18, 89, 100] | ⇒ | FUSIONNER | ⇒ | |
| et | t = [3, 8, 13, 18, 50, 80, 89, 100] | |||
| t2 = [3, 8, 50, 80] |
Le fonctionnement global par étape :
- Etape 1 : Création d'un tableau t_fusion ayant la bonne taille pour récupérer la fusion
- Etape 2 : Initialisation des indices permettant de connaitre la case qu'on va remplir dans t_fusion et des indices de début, de fin et de la case à lire dans les deux sous-tableaux
- Etape 3 : Remplissage de t_fusion jusqu'à ce que l'un des deux sous-tableaux soit entièrement lu
- Etape 4 : Remplissage de t_fusion avec le sous-tableau restant
- Etape 5 : On renvoie le tableau t_fusion
Voici le prototype :
def fusionner(t1:list, t2:list) -> list:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51 | |
...CORRECTION...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51 | |
13° Compléter la fonction scinder() de façon à implémenter l'algorithme de division d'un tableau statique en deux tableaux. Il doit fournir en sortie un couple (tuple à 2 éléments) comportant deux tableaux issus des parties gauche et droite du tableau de base.
| ⇒ | SCINDER | ⇒ | ||
| t = [30, 8, 100, 50, 55] | ([30, 8], [100, 50, 55]) | |||
Le fonctionnement global par étape :
- Etape 1 : On récupère les 3 indices importants du tableau t : l'indice de la première case, de la dernière case et de la case du milieu.
- Etape 2 : On crée les deux sous-tableaux gauche et droite par compréhension (ou Slicing mais hors programme de NSI)
- Etape 3 : On renvoie les deux tableaux à l'intérieur d'un tuple puisqu'une fonction ne peut renvoyer qu'une unique réponse.
Voici le prototype :
def scinder(t:list) -> tuple(list, list):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | |
...CORRECTION...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 | |
14° Compléter la fonction trier() de façon à implémenter l'algorithme du tri fusion d'un tableau statique.
| ⇒ | TRIER | ⇒ | ||
| t = [30, 8, 100, 50, 55] | [8, 30, 50, 55, 100] | |||
Le fonctionnement global :
- Etape DIVISER : on utilise la fonction scinder() pour obtenir deux sous-tableaux plus petits.
- Etape REGNER : lorsqu'on obtient un sous-tableau de moins de 2 cases, on sait que le sous-tableau est trié.
- Etape COMBINER : on utilise la fonction fusionner() pour fusionner deux sous-tableaux plus petits.
Dans le cadre d'une fonction récursive, cela donne donc :
- CAS DE BASE : si le tableau reçu comporte 1 élément ou moins, on renvoie une copie exacte.
- CAS RECURSIF : on divise le tableau en deux et on renvoie la fusion de la partie gauche triée avec trier() et la partie droite triée avec trier()
Voici le prototype :
def trier(t:list) -> list:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101 | |
...CORRECTION...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101 | |
Tri fusion modifiant le tableau statique en place
15° Compléter la fonction fusionner() de façon à implémenter l'algorithme de fusion de deux sous-tableaux triés à l'intérieur d'un tableau t. Il ne fournir rien en sortie puisqu'il modifie le tableau en place.
On doit fournir en entrée :
- la référence du tableau t
- L'indice d1 et f1 du début et de la fin du sous-tableau 1 (indices inclus)
- L'indice f2 de la fin du sous-tableau 2 (indices inclus). On ne donne pas d2 car cet indice vaut nécessairement f1 + 1
| t = [3, 8, 13, 18, 50, 100, 80, 89] | ⇒ | FUSIONNER | ⇒ | |
| d1 = 4, f1 = 5 | VIDE | |||
| f2 = 7 |
Le tableau est alors devenu t = [3, 8, 13, 18, 50, 80, 89, 100]
Le fonctionnement global par étape :
- Etape 1 : Création d'un tableau t_fusion ayant la bonne taille pour récupérer temporairement la fusion
- Etape 2 : Initialisation des indices permettant de connaitre la case qu'on va remplir dans t_fusion et des indices de début, de fin et de la case à lire dans les deux sous-tableaux
- Etape 3 : Remplissage de t_fusion jusqu'à ce que l'un des deux sous-tableaux soit entièrement lu
- Etape 4 : Remplissage de t_fusion avec le sous-tableau restant
- Etape 5 : On modifiant maintenant les cases correspondantes du tableau t à l'aide des cases du tableau t_fusion
Voici le prototype :
def fusionner(t:list, d1:int, f1:int, f2:int) -> None:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57 | |
...CORRECTION...
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57 | |
Il existe plusieurs façons différentes de réaliser la fusion. Le but n'est pas ici de les étudier une par une.
16° Expliquer en quelques phrases comment fonctionne la fonction lancer_tri_fusion() puis la fonction trier() dans cette version mutable.
Ecrire ensuite la pile d'appels lorsqu'on lance lancer_tri_fusion() sur le tableau [10, 30, 20, 40, 15, 60].
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105 | |
Conclusion
Nous obtenons donc un tri de bien meilleure qualité que le tri par insertion.
Le tri fusion est à coût quasi-linéaire mais son défaut vient du fait qu'il nécessite d'utiliser un ensemble de tableaux temporaires de même taille que le tableau d'entrée.
L'algorithme de tri de Python est basé lui sur la méthode de tri rapide, également quasi-linéaire mais ne nécessitant un espace mémoire constant.
4 - FAQ
On peut démontrer que le coût est quasi-linéaire sur le tri fusion ?
Oui, mais c'est hors programme car on utilise la démonstration par récurrence, vue en spé Maths en 1er.
Vous pouvez néanmoins la comprendre assez facilement si vous avez suivi la 1er NSI puisque cette démonstration est très proche de la preuve de correction des algorithmes.
Preuve de correction et invariant
Définitions
La preuve de correction d'un algorithme permet d'affirmer
- qu'il fournit toujours une réponse correcte
- sur toutes les entrées valides qu'on lui fournit.
Pour faire la preuve de correction d'un algorithme, il faut trouver un INVARIANT : une propriété P vérifiable qui reste vraie lors des différentes étapes de l'algorithme.
Un INVARIANT DE BOUCLE est
- une propriété vrai avant la première itération ;
- qui reste vraie à chaque itération de la boucle ;
- elle est donc vraie après avoir effectué le dernier tour de boucle.
Cet invariant permettra de prouver que le résultat final après exécution est bien le résultat attendu.
Malheureusement, il n'y a pas de méthodologie automatique miraculeuse pour trouver cet invariant. Il faut réfléchir et tenter des choses, comme avec toute démonstration.
Démonstration en 3 phases
Une fois qu'on dispose d'un INVARIANT P, la démonstration se fait en trois temps.
- Phase d'initialisation : P0 est VRAI
- Phase de conservation : Pk ➡ Pk+1
- Hypothèse de départ :
- Déroulement d'un nouveau tour de boucle
- On peut donc résumer cela par l'équation
Pk ➡ Pk+1 qui veut dire
SI Pk est vraie alors Pk+1 sera encore vraie après un tour supplémentaire. - Phase de terminaison
On doit prouver que l'INVARIANT est VRAI avant le premier tour de boucle. On a donc fait 0 tour en entier.
Le plus souvent, cette partie est triviale.
On fait l'hypothèse que la propriété Pk est vraie après un certain nombre de tours de boucle.
On doit montrer qu'en réalisant un tour supplémentaire, l'invariant P reste vrai à la fin de cette boucle. Pk+1 sera donc vérifiée.
On doit prouver qu'après le dernier tour, l'algorithme termine exactement sur la situation voulue. Ni trop, ni trop peu.
C'est pour cela qu'on nomme cet étape "la phase de terminaison", à ne pas confondre avec la preuve de terminaison / preuve d'arrêt.
On utilisant (1) + (2), on montre ceci :
P0 ➡ P1 ➡ P2 ➡ P3... >
On utilisant (3), on montre en plus que l'algorithme s'arrête au bon moment.
P0 ➡ P1 ➡ P2 ➡ P3... ➡ Pfinal
La démonstration par récurrence est assez proche puisqu'on fait la même chose sans vérifier la dernière étape : il ne s'agit pas de vérifier qu'on s'arrête au bon endroit comme un algorithme mais juste qu'une propriété est vraie.
- Etape d'initialisation
- On montre que notre propriété P est vraie au départ : P0 est VRAI.
- Etape d'hérédité (qui se nomme étape de conservation lors d'une preuve de correction)
- On fait l'hypothèse que P est vraie à l'étape k.
- On doit démontrer que dans ce cas, P est nécessairement vraie à l'étape k+1
- On peut donc écrire Pk ➡ Pk+1
- Conclusion (qui se nomme terminaison lors d'une preuve de correction)
- Il suffit d'énoncer que puisque la propriété est vraie au départ et que le fait qu'elle soit vraie à une étape implique qu'elle est vraie à l'étape suivante alors elle est nécessairement vraie à n'importe quelle étape k, k étant un entier naturel.
Sur le cas du tri fusion, montrons que le coût est bien quasi-linéaire.
Notre propriété P est donc que la complexité de l'algoritmhe est n log2(n).
Etape d'initialisation
Si le tableau ne contient qu'un élément (n=1=20), il ne faut aucune comparaison pour résoudre le problème.
Or 1 log2(1) = 1 log2(20) = 0.
P0 est donc VRAI.
Etape d'hérédité (qui se nomme étape de conservation lors d'une preuve de correction)
On considère par hypothèse que la formule est vraie pour n= 2k éléments.
Pk est donc VRAI par hypothèse.
On considère maintenant que nous avons 2k+1 éléments.
Le nouveau nombre d'éléments est donc égal à 2*2k puisque
2*2k = 21*2k = 2k+1
Trier un tableau de 2k+1 éléments revient donc à trier deux tableaux de 2k élements puis à rajouter 2k+1 opérations pour fusionner les deux tableaux en un seul tableau (nous avons montrer que le coût de la fusion était linéaire).
Le nombre d'opérations estimées est donc :
2 * 2k * log2(2k) + 2k+1
2k+1 * log2(2k) + 2k+1 * 1
2k+1 * (log2(2k) + 1)
2k+1 * (k + 1)
2k+1 * (log2(2k+1))
Ce qui est exactement la propriété Pk+1.
On vient donc de montrer que si Pk est vraie, alors Pk+1 est vraie également.
Conclusion
Puisque l'intialisation est vraie et que l'hérédité est vraie, alors la propriété P est vraie quelque soit la valeur de k.
P est donc vraie : le coût de l'algorithme de tri fusion est bien quasi-linéaire.
C'est quoi le slicing ?
Déjà, ce n'est pas au programme de NSI. Juste une facilité d'écriture, bien pratique, présente dans pas mal de langages mais qui rajoute une couche de connaissances inutiles puisqu'on vous demande de savoir manipuler la création par compréhension.
Une facilté de Python et d'autres langages pour récupérer des bouts de tableaux par exemple.
Voici plusieurs exemples où je montre d'abord comment faire avec compréhension puis en utilisant le slicing (le "tranchage" en anglais).
>>> t = [10, 50, 30, 20, 60]
>>> g = [t[i] for i in range(0, 4)]
>>> g
[10, 50, 30, 20]
>>> g = [t[i] for i in range(4)]
>>> g
[10, 50, 30, 20]
>>> g = t[0:4]
>>> g
[10, 50, 30, 20]
>>> g = t[:4]
>>> g
[10, 50, 30, 20]
Comme vous pouvez le voir, on obtient une notation plus légère qu'avec le compréhension pour le même effet. On peut se passer de donner la valeur initiale s'il s'agit de la valeur 0 et la valeur finale est exclue comme avec range.
Là où c'est pratique, c'est qu'on peut également se passer de la valeur finale. Du coup, on peut faire des copies facilement. Mais on peut faire des copies aussi avec de la compréhension, avec la fonction native list() ou avec la méthode copy() :
>>> t = [10, 50, 30, 20, 60]
>>> c = t[:]
>>> c
[10, 50, 30, 20, 60]
>>> c = t[0:4]
>>> c
[10, 50, 30, 20]
>>> c = [v for v in t]
>>> c
[10, 50, 30, 20, 60]
>>> c = list(t)
>>> c
[10, 50, 30, 20, 60]
>>> c = t.copy()
>>> c
[10, 50, 30, 20, 60]
Pour récupérer les côtés gauche et droite d'un tableau, on peut donc juste faire ceci une fois qu'on a l'habitude :
Pour finir, nous pouvons les utiliser pour diviser facilement un tableau en deux, même si c'est le côté droit qui récupère l'élément supplémentaire éventuel :
>>> t = [10, 50, 30, 20, 60]
>>> g = t[:len(t)//2]
>>> g
[10, 30]
>>> d = t[len(t)//2:]
>>> d
[20, 40, 15]
En conclusion, le slicing est pratique mais totalement dispensable. Ne l'utilisez pas dans vos programmes, préférez les constructions par compréhension, plus explicites et surtout officiellement au programme.
Activité publiée le 30 03 2021
Dernière modification : 30 03 2021
Auteur : ows. h.