Le protocole HTTP fait communiquer deux programmes :
Un programme client HTTP qui se connecte à
un programme serveur HTTP.
Le protocole HTTP est basé sur une communication en 3 étapes :
Requête - Traitement - Réponse
Le client envoie sa requête (à l'aide d'une URL).
Le serveur reçoit et analyse la requête
Le serveur renvoie sa réponse (elle contient souvent un texte nommé code-source HTML)
B - Code de réponse
La réponse HTTP contient notamment un code de réponse. Vous connaissez certainement le 404.
Voici quelques codes courants :
Code 200 : le serveur dit que tout s'est bien passé.
Code 404 : le serveur ne trouve aucune ressource correspondant à la requête.
Code 300 : le serveur dit que la ressource n'a pas été modifiée depuis la dernière fois que le client lui a demandé. Le client doit juste aller voir dans sa mémoire-cache.
Code 500 : le serveur rencontre une erreur de programmation en tentant de résoudre la requête....
C - Le programme client usuel : le navigateur Web
Nous avons déjà défini ce programme comme un interpréteur de code HTML dans les activités précédentes.
Donons maintenant une définition plus précise :
Un navigateur Web est un programme capable de réaliser plusieurs tâches, notamment :
Communiquer en HTTP avec un serveur distant ;
Interpréter le code HTML pour produire un affichage ;
Générer un historique des documents Web déjà visités ;
...
Quelques exemples de navigateur Webs :
Firefox de la fondation Mozilla,
le moteur libre Chromium, produit par Google
Chrome, une surcouche propriétaire de Chromium, produit par Google.
Brave, une surcouche libre de Chromium, produit par Brave Software.
Safari pour Apple
...
Attention, tous les navigateurs n'ont pas le même degré de sécurité.
Le code-source d'un navigateur libre est accessible et lisible par tous. Il ne peut pas, à priori, pas contenir d'instructions malveillantes.
Dans le cas d'un navigateur propriétaire, vous ne voyez que les effets apparents du programme. Vous ne pouvez pas savoir exactement ce que fait ce programme sur votre propre système.
(Rappel) 1.2 La couche APPLICATION
graph LR
subgraph Programme A
I(("Code interne")) <-. communication .-> D["APPLICATION formatage ou extraction"]
end
subgraph Programme B
A["APPLICATION formatage ou extraction"] <-. communication .-> S(("Code interne"))
end
D <--> Mystere["..."] <--> A
style A fill:#6ff,stroke:#880,stroke-width:2px
style D fill:#6ff,stroke:#880,stroke-width:2px
style Mystere fill:#99f,stroke:#333,stroke-width:2px
Qu'est que la couche APPLICATION ?
C'est un programme chargé de mettre en forme les informations sous un format précis connus de tous.
Deux cas se présentent :
Envoi : mise en forme codifié des informations que veut transmettre un programme.
Réception : extraction des informations contenus dans le message codifié reçu.
Cette couche fait donc office d'INTERFACE entre un programme et le monde extérieur.
Exemple : le format HTTP
On commence par écrire l'en-tête HTTP qui est composé de deux parties :
une première ligne contenant 3 informations : la méthode d'envoi, la ressource voulue et le protocole utilisé. L'espace (octet de valeur 32) est le caractère délimiteur.
plusieurs autres lignes constituant une sorte de dictionnaire : la clé (nom de l'information), le caractère : et la valeur de cette information.
On finit par le message en lui-même. Lorsque le serveur HTTP répond, c'est là qu'il place les octets d'un code HTML ou les octets d'une image par exemple.
Exemple de requête POST
Voici une requête POST qu'envoie un client (Firefox tournant sous Linux) pour tenter de connecter l'utilisateur bob dont le mot de passe est 1234! :
De nombreux protocoles ont été élaborés en fonction des besoins de données à transmettre :
Pourquoi pas un seul et unique protocole ?
Selon le type de l'application, on aura besoin d'optimiser certains aspects, de parler beaucoup ou pas, de transmettre certaines informations à propos de l'ordinateur ou pas... D'où un grand choix.
Quelques protocoles APPLICATION
Protocole HTTP pour le Web (entre le programme-navigateur et le programme-serveur par exemple)
Protocole FTP pour les téléchargements et les téléversements (entre votre programme et le programme-serveur qui stocke les fichiers)
Protocole POP pour lire ou envoyer les emails (entre le programme d'emails et le programme-serveur email)
Protocole IMAP pour lire ou envoyer les emails (un peu plus fourni que POP)
...
Quel est le type de données envoyées par votre navigateur lorsqu'il fait une requête HTTP ? Du texte. Ou plutôt une suite d'octets encodant une chaîne de caractères en ASCII.
Pour transmettre un A, l'octet vaut 6510 ou 4116.
Pour transmettre un B, l'octet vaut 6610 ou 4216...
Votre programme-navigateur a alors compris où vous vouliez aller et à codifier votre demande en utilisant la couche APPLICATION selon le protocole HTTP. Vous allez voir ci-dessous le texte que votre navigateur a réellement envoyé lorsque vous avez lancé votre requête le mar 23 Jui 2026 à 07:09 (heure serveur) pour afficher cette page.
Texte réel de la requête envoyée par le navigateur, conçu à partir de la barre d'adresses :
.............................DEBUT DE LA REQUETE HTTP
.............................FIN DE LA REQUETE HTTP
J'ai rajouté un visuel ↲ pour les passages à la ligne (line feed) car il s'agit d'un vrai octet (code ASCII 1010 ou 0A16). Normalement le caractère n'est pas visible car il n'est pas un caractère d'imprimerie mais un caractère de contrôle : il provoque...le passage à la ligne. Il s'agit du caractère encodé par \n dans un string Python.
Comme vous le voyez, la requête HTTP est donc un texte codifié, les informations sont placées à certains endroits précis pour que le programme-serveur puisse les retrouver.
01 Dans cette requête HTTP, quelles sont les informations transmises
Sur la première ligne (3 informations différentes)?
Sur la deuxième ligne ? (une information)
Sur la troisième ligne ? (une information)
...CORRECTION...
Sur la première ligne ? Méthode utilisée espace ressource demandée espace version de HTTP utilisée.
Sur la deuxième ligne ? Le nom de domaine du serveur qu'on veut joindre
Sur la troisième ligne ? Ca dépend des systèmes. Par exemple, c'est parfois la longueur en octet du message interne transmis avec la requête : ici 0 car c'est un GET : toutes les informations sont transmises via l'URL, il n'y a pas de message sous l'en-tête fournissant différentes informations.
Un exemple de réponse HTTP possible, envoyée par le programme-serveur après qu'il ai traité la requête HTTP :
.............................DEBUT DE LA REPONSE HTTP
HTTP/1.1 200 OK↲ Content-Type: text/html; charset=utf-8↲
Content-Length: 36435↲
Vary: Cookie↲
Via: 1.1 alproxy↲
Date: Thu, 19 Mar 2020 12:54:47 GMT↲ ↲ <!DOCTYPE html>↲
<html lang="fr">↲
<head>↲
...
: la suite, c'est donc le reste du fichier html !
...
</html lang="fr">↲
.............................FIN DE LA REPONSE HTTP
Encore une fois, il s'agit d'un texte codifié par le serveur de façon à ce que le navigateur puisse facilement retrouver les informations dont il a besoin.
02 Dans cette réponse HTTP, quelles sont les informations transmises
Sur la première ligne (3 informations différentes)?
Sur la deuxième ligne ? (une information principale et ici une info complémentaire)
Sur la troisième ligne ? (une information)
...CORRECTION...
Sur la première ligne ? version de HTTP utilisée pour répondre espace code de la réponse espace texte complémentaire liée au traitement de la requête initiale
Sur la deuxième ligne ? Le type des données contenu dans le message sous l'en-tête : ici les octets d'un code HTML qu'il faudra décoder en utilisant UTF-8.
Sur la troisième ligne ? La longueur en octet du message interne transmis avec la requête : ici 36435 octets, soit 36ko environ.
Protocole HTTP de la couche Application (2) : la Communication HTTP
Le protocole HTTP est l'un des protocoles de la couche APPLICATION. HTTP est basé sur le principe client-serveur.
HTTP veut dire Hyper Text Transfert Protocol.
Le programme-client fait une requête HTTP composée de plusieurs parties :
Une première ligne d'informations (méthode - ressource demandée - protocole utilisé)
Les lignes de l'en-tête sous la forme clé: valeur
Une ligne vide
Le contenu du message lui-même
Le programme-serveur reçoit la requête, la traite et renvoie une réponse HTTP composée de plusieurs parties :
Une première ligne d'informations (protocole utilisé - code réponse - texte descriptif complémentaire)
Les lignes de l'en-tête sous la forme clé: valeur
Une ligne vide
Le contenu du message lui-même
Sous l'en-tête de la réponse HTTP, le message du serveur contient donc soit :
le code HTML de la page à afficher si le client demande un fichier HTML (une suite d'octets donc)
le code CSS si le client demande un fichier CSS (une suite d'octets donc)
le code JS si le client demande un fichier JS (une suite d'octets donc)
le code de l'image à afficher si le client demande une image (une suite d'octets donc)
...
Notez bien la présence d'une ligne vide entre l'en-tête et le message transporté par la communication : imposée par le protocole HTTP, elle permet à celui qui reçoit la communication de détecter facilement la fin de l'en-tête et le début du message en lui-même : il suffit de détecter deux octets 10 (passages à la ligne) successifs.
Protocole HTTP de la couche Application (3) : les méthodes GET et POST
La requête HTTP peut se faire de plusieurs façons. En voici deux :
La méthode GET :
on transmet les informations supplémentaires dans l'URL : le message de la requête est donc vide.
utile pour transmettre un nombre limité de données
jamais pour transmettre un mot de passe : l'url étant visible dans la barre de navigation, en regardant l'écran de quelqu'un on pourrait facilement voir le mot de passe !
la méthode POST :
on transmet les informations supplémentaires dans le message : c'est que vous faites lorsque vous envoyez vos copies numériques : votre texte n'apparait pas dans l'URL.
utile pour transmettre un nombre important de données
utile pour transmettre des données sensibles : elles n'apparaissent pas dans l'URL affichée.
Culture générale : sachez qu'il existe aussi des requêtes :
HEAD : permet de ne recevoir que l'en-tête d'une page, pas le corps du message en lui-même : ça permet de savoir si une page existe, a été mise à jour ...
DELETE : permet de supprimer une ressource sur le serveur
PUT : permet de placer une ressource sur le serveur
✎ 03 QCM : La requête que vous avez effectué pour visualiser cette page est-elle une requête
A : GET
B : POST
C : HEAD
D : PUT
✎ 04 QCM : Sur la fin de la première ligne de la requête se trouve la version du protocole HTTP utilisé pour formaliser la requête. Quelle version HTTP le serveur distant devra-t-il utiliser pour décoder correctement votre requête ?
A : 0.9
B : 1.0
C : 1.1
D : 2.0
✎ 05 Quel est le nom du serveur distant (Host) qu'on tente de joindre ?
✎ 06 En regardant les lignes sous la ligne du GET, on trouve l'ensemble des en-têtes que votre navigateur a envoyé au serveur ou que le serveur a récupéré d'une manière ou d'une autre. Est-ce une communication utilisant http ou https ? Trouvez la ligne comportant une indication sur la nature HTTP ou HTTPS dans la demande. Fournir la ligne et le protocole utilisé.
On notera que le serveur récupère également des informations qui seront rajoutées ensuite. Notamment votre adresse IP : ce que j'affiche sur cette page est une partie de l'en-tête reçu par le serveur. On y trouve surtout X-Real-Ip qui contient l'IP ayant à priori fait la requête HTTP initiale.
Regardons maintenant la vraie réponse que vous a fourni le serveur du site.
Cette partie vous montrera comment utiliser certains menus de Firefox pour visualiser une partie de HTTP.
07° Dans Firefox, activer le menu, choisir Développement Web puis réseau :
08° Actualiser la page https://www.infoforall.fr/act/archi/communication-tcp-ip/ sur laquelle vous êtes actuellement.
Remonter en haut des fichiers que vous venez de télécharger : vous devriez tomber sur un fichier HTML : il s'agit du code HTML de la page. C'est bien la première chose que vous transmet le serveur.
Quel est le code obtenu sur la plupart des fichiers ?
200 pour dire que la réponse s'est bien passée
304 pour signaler que le fichier demandé n'a pas été modifié depuis la dernière demande et que vous pouvez donc juste utiliser celui que vous avez en mémoire cache.
404 pour signaler que la requête n'a pas pu aboutir : le serveur fonctionne bien mais il ne sait pas quoi vous répondre.
500 pour signaler que le serveur rencontre un problème : la demande a créé un problème bloquant l'exécution
Parvenez-vous à reconnaitre d'autres types de fichiers parmi les fichiers affichés ?
...CORRECTION...
Sur le visuel ci-dessous, on voit que le premier document est un document de type HTML.
Le code 200 permet d'indiquer que la requête et la réponse se sont bien déroulées. Tout est ok.
On voit que le navigateur a fait plusieurs demandes :
D'abord le fichier HTML et ensuite
des fichiers CSS
des fichiers images
des fichiers JS
Voici un visuel des choses qu'on peut obtenir avec https://www.infoforall.fr :
Pourquoi cet ordre dans les demandes ?
Comment le client sait-il quels fichiers demandés en plus du code HTML reçu ? C'est simple : Firefox reçoit le code HTML, il le lit !
Si vous voulez savoir dans quel ordre vous devriez recevoir les fichiers, vous pouvez faire un clic-droit et utiliser AFFICHER CODE SOURCE. On part de la ligne 1 et on descend séquentiellement.. Si la ligne 13 contient la référence d'un fichier CSS, il le demande en envoyant une nouvelle requête HTTP.
Votre navigateur lit donc le HTML séquentiellement et fait les demandes de fichiers annexes au fur et à mesure qu'il détecte qu'il va en avoir besoin : CSS. JS, images apparaissent lors de la lecture du HTML.
09° Cliquer sur la première ligne : celle du fichier HTML. Vous devriez obtenir un affichage proche de celui présenté ci-dessous.
10° En regardant le détail de la demande, répondre aux questions suivantes :
Avez-vous effectué une requête de type GET ou de type POST ?
Quelle est l'adresse IP (adresse numérique internet) du site joignable par le nom www.infoforall.fr ?
Le port 443 est-il bien compatible avec une liaison à un serveur HTTPS ou un serveur HTTP ?
...CORRECTION...
Nous avons fait une requête de type GET : on veut juste recevoir des informations (et au pire en fournir quelques unes peu nombreuses)
L'adresse IP du site est notée [2a00:b6e0:1:20:2::1]:443 sur l'image.
Vous avez peut-être déjà vu que le port 80 est le port des serveurs HTTP et 443 le port des serveurs HTTPS. Plus de détails dans la partie suivante.
11° Cliquer sur le bouton En-têtes brutes de la REPONSE de façon à voir le contenu de l'en-tête telle que le navigateur l'a reçu avant de vous le remettre en forme. Vous devriez constater qu'il s'agit bien d'un simple contenu texte.
ATTENTION : il s'agit juste de l'en-tête. On n'affiche pas le message interne qui se trouve normalement après l'en-tête HTTP. Mais il y a un onglet REPONSE si vous voulez le voir, et on y trouve un bouton code brut.
Un exemple de réception possible (j'ai rajouté l'endroit où se trouve le message interne renvoyé) :
<!DOCTYPE html>... : la suite, c'est le fichier html au complet !
12° Descendre encore un peu plus bas : activer également En-têtes brutes mais cette fois sur l'en-tête de la REQUETE que votre navigateur a réellement envoyé. Comme vous pourrez le voir, nulle trace à ce moment de votre adresse IP : elle apparaît sur l'en-tête reçu par le site, c'est bien qu'on a rajouté l'information à un moment.
13° Faire cette demande inconnue https://www.infoforall.fr/ast/snt/historique-du-webeeux/. Comment le navigateur va-t-il savoir que quelque chose s'est mal passé ? Quelle est le numéro de la réponse cette fois ?
...CORRECTION...
Il s'agit de la fameuse erreur 404 !
Lorsque le navigateur reçoit une réponse http de ce type du serveur, il sait que le serveur lui dit que sa requête n'a pas pu aboutir pour une raison simple : la ressource demandée n'existe pas ! La plupart du temps, il s'agit d'une ressource qui a existé mais qu'on a supprimé du serveur.
La plupart des sites proposent des pages 404 personnalisées.
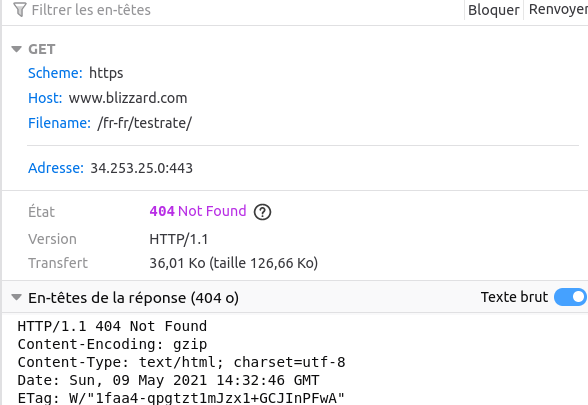
14° Faire la requête inconnue suivante sur le site de blizzard (bloqué au lycée):
https://www.blizzard.com/fr-fr/testrate/.
Répondre ensuite aux questions suivantes :
Quel protocole a été utilisé ?
Quel est le nom du serveur à contacter ?
...CORRECTION...
Quel protocole a été utilisé ? https
Quel est le nom du serveur a contacté ? www.blizzard.com
Quelle est la requête demandée à ce serveur ? /fr-fr/testrate/
Quel est son IP ? 34.253.25.0:443 au moment où moi j'ai fait le test
Quel est le numéro de sa réponse ? 404 !
✎ 15° Choisir et fournir une URL. A l'aide de code source de la page, donner les 3 premières requêtes qui vont être demandées après lecture de la première réponse HTTP contenant le code HTML de la page.
17° La boîte ci-dessus vous permet de voir la valeur des paramètres éventuels question et numero envoyés sur cette page. Avez-vous transféré de tels paramètres ou sont-ils inexistants dans votre URL pour l'instant ?
Valeur du paramètre question :
Valeur du paramètre numero :
Ce ne sont pas les bonnes valeurs de paramètres !
Deuxième partie : restez sur la page où vous êtes et :
transférez (via l'URL de la barre d'adresses) le paramètre question à la valeur corrige et le paramètre numero à la valeur 2.
appuyez sur Entrée dans la barre d'adresses puis revenez ici.
label
Vous devriez voir un affichage BRAVO ! juste au dessus.
Magie !
Noter sur la copie numérique l'URL que vous avez dû taper pour obtenir BRAVO.
SI VOUS BLOQUEZ : voir le bout de cours juste au dessus, celui nommé Méthode GET : paramètres dans l'URL.
✎ 18° Un serveur reçoit une requête GET de ce type :
A-t-on transmis des paramètres ? Lesquels ? Quelles sont leurs valeurs ?
✎ 19° Puisque taper des variables directement dans l'URL n'est pas très pratique pour un utilisateur, on utilise plutôt des formulaires sur le Web : l'utilisateur rentre ses valeurs, appuie sur le bouton ENVOYER ou SUBMIT et c'est le navigateur qui se charge de formuler correctement la demande en respectant les normes HTTP d'une méthode GET.
Utiliser le formulaire ci-dessous pour observer comment la demande a été reçu par le site.
Voyons maintenant la méthode POST. Cette fois, le client va transmettre les données fournies dans le corps de la requête HTTP.
✎ 20° Utiliser le formulaire ci-dessous en choisissant des valeurs pour les paramètres question et numero. En appuyant sur SUBMIT, vous allez envoyer les données vers une page acceptant la requête en POST. On y affiche le contenu de la requête.
Deux réponses à fournir sur la copie :
En lisant la requête, où voit-on qu'il s'agit d'une requête POST ?
Où se trouvent cette fois les informations liées aux paramètres envoyés : dans le corps (body) de la requête ou dans l'URL ?
Attention, il a donc deux façons de modifier une page en fonction des données fournies par le client :
Script côté CLIENT
Vous avez appliqué cette méthode lors de votre découverte de Javascript.
On peut utiliser un code côté client : un code Javascript a été envoyé par le serveur.
Le code tourne actuellement sur l'ordinateur-client.
C'est ce que vous avez fait lorsque vous avez découvert JS.
On utilise donc les ressources du client pour réaliser le traitement des données : on peut lire le contenu dans le formulaire et modifier les balises en cherchant les références à l'aide des attributs. Le code HTML est donc modifié sur la machine client APRES l'envoi par le serveur.
Modification côté CLIENT
Langage de script usuel : Javascript.
Avantage : on utilise les ressources du client et on peut réagir à ses actions en temps réel.
Désavantage : un client sachant lire le code source peut lire votre code très facilement. Ce n'est pas utilisable pour gérer un mot de passe.
Programme côté SERVEUR
Cela, vous ne savez pas encore le faire.
On a utilisé un code côté serveur : le programme tourne sur l'ordinateur-serveur.
Ce programme analyse la requête GET ou POST pour récupérer les paramètres. Le serveur envoie alors un code HTML en fonction du résultat du test : bonne correspondance alias - mot de passe ou pas.
Modification côté SERVEUR
Ca, vous ne l'avez pas encore fait. Nous allons le faire aujourd'hui.
Plein de langages disponibles :
PHP est certainement le plus connu car le premier a avoir permis de faire cela facilement. Wordpress fonctionne en PHP.
on peut utiliser Python
on peut utiliser Javascript (mais côté serveur attention !)
... et plein d'autres encore.
Avantage : le client ne peut aucunement avoir accès à ce code. Et ça, c'est fondamental dès que vous voulez gérer des mots de passe.
Désavantage : c'est l'ordinateur-serveur qui travaille. Il doit donc être assez puissant pour gérer toutes les demandes des clients.