24 - Système sur puce (Soc)
Nous allons revoir rapidement ce que nous avons découvert l'an dernier sur l'architecture matérielle des ordinateurs puis voir la différence interne entre un ordinateur classique et un smartphone par exemple.
Evaluation ✎ : -
Documents de cours : open document ou pdf
1 - Architecture matérielle (rappels de 1er)
Voici le schéma de principe d'une machine de von Neumann :
Machine de von Neumann
On a donc :
- Le processeur également nommé UDT (Unité de Traitement) ou CPU (central processing unit) en anglais. Il est composé de l'UDC (unité de contrôle) et l'UAL (unité arithmétique et logique, qui contient au moins un registre nommé accumulateur)
- Quelques registres si on le désire
- Des bus permettant de transférer des informations. Un bus de 64 bits est constitué de 64 "fils électriques" qui permettent de faire transiter 64 bits simultanément. Si on doit transporter 128 bits avec des bus de 64 bits, il faudra donc faire 2 opérations de transport, là où un seul transport suffit avec un bus de 128 bits. On dispose d'ailleurs de 3 types de bus :
- Les bus d'adresses dont le nombre de bits permet de trouver le nombre de cases mémoires adressables
- Les bus de données dont le nombre de bits permet de savoir combien d'octets de données on peut transférer en une opération à partir de l'adresse fournie via le bus d'adresses
- Les bus de contrôle qui permettent de transférer les ordres et les informations permettant leurs exécutions
- Entrée peut correspondre à des capteurs (on envoie des données vers l'ordinateur depuis la souris, le clavier...)
- Sortie peut correspondre à des actionneurs (on agit sur l'environnement à l'aide de l'écran, d'un buzzer...)
- Une mémoire permettant de stocker les programmes et les données.
Il reste bien entendu encore bien des composants importants. Par exemple :
- l'horloge : c'est le composant qui envoie un signal permettant à tous les composants d'agir en cadence. Plus l'horloge est rapide, plus on peut faire d'instructions par seconde.
- les processeurs annexes comme le processeur grahique ou GPU (Graphics processing unit ): c'est un processeur esclave du processeur principal et qui est optimisé pour faire du calcul sur les objets 3D par exemple. Le processeur lui sous-traite une partie des calculs lors de l'utilisation de 3D par exemple
- Même principe pour la carte son
- La carte réseau qui se charge des interactions de type communication
- ...
Imaginons qu'on dispose d'un processeur disposant d'un jeu d'instructions très réduit :
01° Exécuter le programme suivant en utilisant la mémoire initiale représentée ci-dessous. Que contiennent les mémoires à la fin ?

SUB @0 @1
STR @1
ADD @0 @1
STR @2
...CORRECTION...
On commence pour soustraire 5 et 1. On obtient 4 qui se charge dans le seul registre de l'UAL.
On stocke sur 4 à l'adresse @1, ce qui remplace le 1.
On additionne ensuite 5 et 4, ce qui donne 9 dans le registre de l'UAL.
On place alors ce 9 dans la mémoire @2.
Mémoire : registre et RAM
Qu'est-ce qu'un registre ?
Il s'agit d'une zone-mémoire interne au processeur. L'accés à cette mémoire est donc très rapide puisqu'elle est au sommet de la hierarchie des mémoires. Il s'agit d'une zone-mémoire qui est réellement physiquement très proche du processeur.
Dans les architectures qualifiées de load-store, les programmes transfèrent d'abord des données de la mémoire centrale (grand stockage mais peu rapide) vers des registres (faible stockage mais rapide), puis effectuent des opérations sur ces registres, et enfin transfèrent le résultat en mémoire centrale.

On voit donc apparaître plusieurs zones de stockage différentes
- Registres : les fameuses mémoires proches du processeur
- Caches on-chip : des zones mémoires assez rapides situées directement sur la carte à puce (chip) du microprocesseur. On y stocke les résultats précédents de façon à pouvoir les retrouver sans avoir à tout recalculer.
- Caches off-chip : des zones mémoires assez rapides situées en dehors de la carte du processeur lui-même.
- Mémoire centrale : une mémoire bien plus grande mais également beaucoup plus longue en terme d'accés.
- . . .
La RAM est une mémoire volatile (qui disparait lorsqu'on éteint le système) dans laquelle on va stocker les données que l'ordinateur compte utiliser.
Pourquoi ?
Car le temps d'accès à cette machine est plus rapide que le temps d'accès à la mémoire de masse non volatile que représente le disque dur, la carte SD ou la clé USB.
Pourquoi ne pas tout charger dans cette mémoire ?
Car elle est de taille limitée par rapport à celle d'un stockage de masse.
02° Que doit faire votre ordinateur si vous avez besoin de 4 Go de mémoire vive (RAM) mais que vous en avez uniquement 3 ? Quel est la conséquence pour l'exécution des programmes ?
...CORRECTION...
Il doit régulierement placer une partie de la mémoire RAM en mémoire de masse et transférer les informations voulues en mémoire vive en RAM. Comme les accès sont longs, l'ordinateur va "ramer", tout simplement car il doit faire jongler les données entre les deux emplacements mémoire.
03° Si on part du principe que le système doit pouvoir transporter en une seule opération une adresse via son bus d'adresses, combien d'adresses-mémoires RAM différentes peut-on avoir dans un ordinateur dont le bus d'adresse est un bus 16 bits ? Si on considère que chaque case mémoire correspond à un octet, quelle est la mémoire vive maximale disponible sur ce système s'il ne disposant pas d'autres manières d'adresser sa mémoire ?
...CORRECTION...
Il faut calculer à chaque fois 216 pour avoir le nombre d'adresses différentes.
216 = 65536.
On dispose donc de 65536 adresses différentes uniquement.
Si le bus de données est un bus de 8 bits, cela veut dire qu'on ne peut stocker qu'un octet par case mémoire : on dispose donc de 65536 octets, soit un peu plus de 65 ko de mémoire vive.
04° Faire de même pour un ordinateur muni d'un processeur 32 bits, et de bus d'adresses de 32 bits.
...CORRECTION...
Il faut calculer à chaque fois 232 pour avoir le nombre d'adresses différentes.
232 = 4294967296.
On dispose donc de 4294967296 adresses différentes.
En prenant des cases de 1 octet, on aura donc au maximum un peu plus de 4 Go de mémoire vive disponible.
05° Votre disque dur ou votre carte SD correspondent-t-ils à la mémoire vive ?
...CORRECTION...
Non, ils correspondent à une mémoire de masse non volatile : la capacité mémoire est beaucoup plus grande mais le temps d'accès également.
06° Combien d'opérations pour stocker ou lire un grand entier stocké sur 4 octets avec un bus de données de 8 bits connaissant l'adresse mémoire du premier octet ?
...CORRECTION...
On va devoir transférer les 4 octets en quatre étapes : 8 bits à la fois !
07° Combien d'opérations pour stocker ou lire un grand entier stocké sur 4 octets avec un bus de données de 32 bits connaissant l'adresse mémoire du premier octet ?
...CORRECTION...
Cette fois, on peut ramener 4 octets à la fois directement (4 octets = 32 bits). On va donc parvenir à lire l'entier en une seule opération à l'aide de l'adresse-mémoire du premier octet.
08° La même lecture d'un entier sur 4 octets va-t-elle être plus rapide avec un bus de données 64 bits ?
...CORRECTION...
Non : cette fois, nous n'allons en réalité utiliser que 32 bits sur les 64 bits. On ne gagne donc pas de temps par rapport à un bus de 32 bus.
09° Dans quel cas le bus de données 64 bits va-t-il alors être plus efficace ?
...CORRECTION...
Lorsqu'on aura besoin de ramener des données stockées sur 5 octets ou plus.
Culture générale : Assembleur et langage machine
Assembleur ?
L'assembleur est le nom usuel donné aux programmes ci-dessus. Il s'agit de jeux d'instructions qui communique directement avec le processeur. Chaque processeur a donc son propre langage d'assemblage.
Un programme réalisé pour un processeur particulier ne peut donc pas être exécuté par un autre processeur. Il s'agit donc d'un langage de très bas niveau ! Par contre, il est très rapide.
Langage machine
En réalité, le langage machine est constitué uniquemnet des octets reçus par le processeur qui ne sait lire que des bits bien entendu.
La différence est mince avec l'assembleur en réalité. Pourquoi ?
Simplement car l'assembleur est une sorte de traduction directe du langage machine en utilisant des symboles textuels.
Imaginons que le processeur comprenne que lorsqu'il reçoit l'octet 0000 1111 , on désire lui faire faire l'addition des contenus des registres dont les adresses sont fournis à la suite, comme 0000 0001 et 0000 0010 .
Le processeur reçoit donc :
0000 1111 0000 0001 0000 0010
Ceci est du langage machine.
Et comme c'est compliqué à comprendre par un humain, les humains ont inventé l'assembleur qui est juste une sorte de traduction entre octet et chaînes de caractères.
Plutôt que de noter
- 0000 1111 , on note alors ADD
- 0000 0001 , on note alors @1
- 0000 0010 , on note alors @2
On obtient alors les instructions du langage d'assemblage qu'on va pouvoir transmettre à un programme nommé... l'assembleur. Et c'est lui qui va transformer le langage d'assemblage en langae machine.
| ⇒ | Assembleur | ⇒ | ||
| String "ADD @1 @2" | 0000 1111 0000 0001 0000 0010 | |||
Comme cela, tout le monde est content.
Bref, normalement :
- Le langage machine est la suite d'octets
- Le langage d'assemblage où on transforme juste certaines suites d'octets en bouts de texte
- L'assembleur est le nom du programme qui traduit le langage d'assemblage en langage machine
- Mais, tout le monde parle d'assembleur plutôt que de langage d'assemblage.
2 - Microprocesseur
A quoi ressemble l'intérieur d'un ordinateur de bureau ou l'intérieur d'un ordinateur portable ?
Dans les premiers ordinateurs, on pouvait clairement voir les différentes parties du processeurs, les composants étant de grande taille.
Puis vint l'époque de la miniaturisation. En 1971, la société américaine Intel parvient à insérer tous les composants qui constituent un processeur sur un seul circuit intégré, une puce. C'est à partir de ce moment qu'on a nommé le processeur le microprocesseur : un processeur sur puce.

Que contient ce microprocesseur ?
- Un ou plusieurs UDC
- Un ou plusieurs UAL
- Un ou plusieurs registres dont au moins
- Un accumulateur au moins
- Un compteur de programme (PC, Program Counter) qui contient l'adresse de la prochaine instruction à exécuter
Cette miniaturisation a permis
- De réduire la consommation (moins de perte car composants plus petits)
- D'augmenter la vitesse de communication entre les composants du processeur (moins de distance entre eux)
- De diminuer le prix
- Et du coup de créer des ... micro-ordinateurs.
Au fil du temps, la taille des microprocesseurs a continué à diminuer et la puissance a augmenté : puisqu'on peut placer de plus en plus de transistors dans un espace restreint, on obtient un système de plus en plus puissant.
La loi empirique de Moore, du nom de l'ingénieur Gordon E. Moore prédit que tous les deux ans, le nombre de transistors présents dans un microprocesseur puisse doubler.
Cette loi empirique atteint ses limites aujourd'hui car on a atteint des transistors de quelques atomes. Difficile de faire des transistors de moins d'un atome ! Par contre, on pourrait passer à des processeurs 3D plutôt que 2D.
Actuellement, les deux leaders du marché sont Intel et AMD. Les différences entre les deux constructeurs sont assez subtils car on ne peut pas dire qu'une marque est meilleure que l'autre : elles ont toutes deux des puces de bonne qualité. Globalement, Intel crée des processeurs assez chers car ils possèdent des jeux d'isntructions complexes alors qu'AMD produit des processeurs aveec un jeu d'instructions plus réduit.
Mais la miniaturisation n'est pas encore totale : le microprocesseur est de plus en plus petit mais il doit encore communiquer avec les autres composants (la mémoire vive, le disque dur, les cartes filles (graphique, son, réseau...)...)
On relie donc le microprocesseur et les autres composants sur une carte nommée carte mère.

3 - M999
Reste que pour l'instant, nous avons dit que le programme et les données étaient dans la même mémoire mais nous ne l'avons pas montré.
Voyons maintenant une machine un peu plus complexe que M10, à savoir M999.
Nous allons passer à une activité débranchée qui va vous permettre de comprendre comment fonctionne in fine un processeur.
Cette fois, nous allons directement placer les instructions (le programme en mémoire) et allons visualiser son exécution progressive. Le jeu d'instructions fera moins d'opérations complexes et nous allons devoir réellement manipuler directement la mémoire.
Nous considérons donc que nous avons 100 cases mémoires identifiées par des adresses allant de @0 à @99.
On considère que chaque case mémoire peut contenir une valeur dans l'intervalle [0;999]. Ce sera plus simple que de considérer juste un octet.

Notre processeur possède un registre accumulateur R (comme résultat), et deux registres généraux A et B qui peuvent servir, notamment, à stocker les opérandes.
Avec M10, nous avions une instruction du type ADD @50 @60 qui signifiait d'additionner le contenu des adresses @50 et @60.
Avec M999, nous ne pourrons additionner que le contenu des registes A et B : il va donc falloir copier le contenu de @50 dans A et le contenu de @60 dans B.
Voici donc le jeu d'instructions que nous pourrons placer en mémoire :
- Une instruction LDA (load to A) de valeur (0+adr) : copie le contenu de l'adresse adr dans le registre Ar.
Exemple : lorsqu'on exécute 045, la machine sait qu'elle doit placer dans A une copie du contenu de @45.
Particularité de 099 : l'instruction 099 veut dire de copier le contenu de @99 vers A. Or, on considère que si quelqu'un tape quelque chose sur le clavier, la donnée se retrouve dans @99 justement. - Une instruction LDB (load to B) de valeur (1+adr) : copie le contenu de l'adresse donnée dans le registre B.
Lorsqu'on exécute 145, la machine copie le contenu de @45 dans le registre B.
Particularité de 199 : l'instruction 199 veut dire de copier le contenu de @99 vers B. Or, on considère que si quelqu'un tape quelque chose sur le clavier, la donnée se retrouve dans @99 justement. - Une instruction STR (store from R) de valeur (2+adr) : copie le contenu R vers l'adresse fournie.
L'instruction 245 veut dire de copier le contenu de R vers @45.
Particularité de 299 : l'instruction 299 veut dire de copier le contenu de R vers @99 et cela provoque l'affichage du contenu transféré sur l'écran de la console. Si on lance 299 avec R contenant 5, 5 va donc s'afficher à l'écran. - Une instruction MOV (move from rs to rd) de valeur (4 + code rs + code rd): copie le contenu d'un registre source (rs) vers un registre destination (rd). On considèrera au moins les codes suivants pour les registres :
- Code 0 pour le registre A.
- Code 1 pour le registre B.
- Code 2 pour le registre R.
- Une instruction ADD de valeur 300 : place le réultat du calcul de (contenu de A + contenu de B) dans R.
- Une instruction SUB de valeur 301 : place le réultat du calcul de (contenu de A - contenu de B) dans R.
- Une instruction NOP de valeur 399
Opérations de copie
L'instruction 402 veut dire de copier le contenu de A dans le registre R.
Opérations arithmétiques
Comment l'unité de commande (UDC) parvient-elle à savoir ce qu'elle doit faire au démarrage ?
Pour cela, nous avons besoin d'un registre supplémentaire. Ce registre devra contenir l'adresse de la prochaine instruction à réaliser. Nommons ce registre PC comme pointeur de commande : le mot pointeur en informatique fait référence au fait de pointer vers une zone mémoire spécifique.
Que contient PC au démarrage ? Il contiendra 0 : l'UDT saura donc que la prochaine instruction à réaliser (la première au démarrage) si trouve dans la case mémoire @0.
C'est donc là qu'il faudra placer la première instruction de votre programme.
Comment l'unité de commande (UDC) parvient-elle à savoir ce qu'elle doit faire ensuite ?
A chaque fois que l'unité de commande (UDC) doit travailler, on considère qu'on suit la procédure suivante, en boucle :
TANT QUE la machine n'est pas à l'arrêt :
- L'UDC copie l'instruction pointée par le pointeur PC dans un registre interne spécifique à cela.
- On incrémente PC de 1 (on signale donc que la prochaine instruction est sur la ligne du dessous).
- l'UDC decode l'instruction qu'elle a stocké : que faire ? avec quelles opérandes ?
- l'UDC lance l'exécution de l'instruction.
10° Utiliser le premier programme fourni pour voir ce qu'il fait.
- Contenu de @00 : 399
- Contenu de @01 : 006
- Contenu de @02 : 402
- Contenu de @03 : 299
- Contenu de @04 : -
- Contenu de @05 : -
- Contenu de @06 : 123
...CORRECTION...
Démarrage.
On commence avec PC = 0.
On lit PC valant 0, on transmet le contenu de @0 à l'UDC : 399.
On incrémente PC à 1.
On exécute 399 : on ne fait rien.
Etape suivante.
On lit PC valant 1, on transmet le contenu de @1 à l'UDC : 006.
On incrémente PC à 2.
On exécute 006 : on copie le contenu de @6 dans A : A contient donc 123.
Etape suivante.
On lit PC valant 2, on transmet le contenu de @2 à l'UDC : 402.
On incrémente PC à 3.
On exécute 402 : on copie le contenu de A dans R : R contient donc 123.
Etape suivante.
On lit PC valant 3, on transmet le contenu de @3 à l'UDC : 299.
On incrémente PC à 4.
On exécute 299 : on copie le contenu de R vers @99 : l'adresse 99 servant d'adresse d'entrée/sortie, on affiche 123 sur l'écran.
Comment l'unité de commande (UDC) parvient-elle à savoir qu'elle doit cesser de fonctionner ?
Nous considérerons ici que la machine M999 stoppe lorsqu'elle passe à l'instruction suivante avec PC pointant vers @99, quelque soit le contenu réelle de cette case mémoire.
Du coup, on fait comment pour dire à la machine de stopper alors que PC pointe encore sur une autre adresse que @99 ?
Bonne question !
Dans l'exercice précédent, PC pointait vers @4, pas vers @99.
Il nous manque donc encore quelques instructions élémentaires.Pour l'instant nous n'avons que des déroulements purement séquentiels possibles.
Nous allons donc rajouter des opérations de branchement : des opérations permettant de modifier la prochaine valeur contenue dans le registre PC.
- Une instruction JPM (Jump to ou Go to) de valeur 5+adr : on place l'adresse fournie dans le registre PC, modifant du même coup la prochaine instruction à réaliser.
De cette façon 599 veut dire de placer @99 dans PC et ainsi la prochaine instruction réaliser pointera vers @99 et signifie donc l'arrêt de la machine. On pourrait ainsi créer une instruction assembleur HLT qui ne serait que l'instruction JPM @99, autrement dit 599 en mémoire. - Une instruction JPP (jump if positive) de valeur 6+adr : on modifie la valeur PC par l'adresse fournie SI le registre R contient une valeur strictement positive. Sinon, on ne modifie pas PC. Comment obtenir du négatif avec un contenu 0-999 ? Comme avec l'octet. On pourrait dire que de pour x dans [0;499], c'est positif et que pour x dans [500;999] c'est négatif et que cela vaut 1000 - la valeur. Juste une décision à prendre au niveau de l'encodage.
Opérations de branchement
11° Utiliser ce second programme pour voir ce qu'il fait.

...CORRECTION...
Pas eu le temps encore.
12° A quel moment va-t-on bifurquer si initialement les contenus mémoire de @11 et @12 sont inversés.
...CORRECTION...
Pas eu le temps encore.
13° Utiliser ce troisième programme pour voir ce qu'il fait.

...CORRECTION...
Pas eu le temps encore.
Cette fois, vous devriez avoir bien compris qu'on place dans le même espace mémoire à la fois le code des instructions et le code des données.
Il y a encore beaucoup de choses à dire bien entendu :
- Comment créer des boucles ?
- Comment créer des procédures non paramètrées ?
- Comment créer des procédures paramètrées ?
- Comment créer des fonctions qui renvoient le résultat ?
Mais on ne peut pas non plus tout découvrir aujourd'hui. Le but n'est pas ici de faire un cours d'assembleur.
Retenons donc :
Microprocesseur
Nous venons de voir qu'on peut concevoir des ordinateurs comportant :
- Une mémoire centrale (rapide ou non, volatile ou non) contenant à la fois les données et les programmes. Le tout sous forme d'octets.
- D'un microprocesseur (CPU) composé principalement d'une unité de commande (UDC, gérant les instructions lues en mémoire), d'une unité arithmétique et logique (UAL), de plusieurs registres (un accumulateur de réponse, un pointeur de commande...)
- et les bus permettant de faire communiquer tout cela.
Chaque microprocesseur dispose de son propre jeu d'instructions et donc dispose de son propre langage !
En première approche, sachez qu'il existe deux façons de gérer ce jeu d'instructions :
- Un microprocesseur à jeu d'instructions réduit (en anglais RISC pour Reduced Instruction Set Computer) est un type d'architecture de processeur qui se caractérise par des d'instructions de base "simples" et donc rapides à décoder.
- Un microprocesseur à jeu d'instruction étendu (en anglais CISC pour Complex Instruction Set Computer), désigne un un type d'architecture de processeur possédant un jeu d'instructions comprenant de très nombreuses instructions mixées à des modes d'adressages complexes. On peut donc lui demander de faire des choses complexes qui auront été optimisé à l'interne. Pour un même dimensionnement en puissance de calculs, il comporte donc plus de transistors qu'un RISC mais coûte plus cher.
A l'heure actuelle (cette activité a été écrite en 2021), les deux principaux constructeurs de microprocesseurs sont INTEL (société américaine, côtée 254 milliards de dollars en 2018, le fabricant des microprocesseur dits "Pentium") et AMD (une autre société américaine, le fabricant des microprocesseur dits "Athlon").
Pour relier le microprocesseur à la mémoire et aux différents périphériques, on utilise un support nommé carte mère. On notera que la carte mère dispose elle-même parfois d'un certain nombre de petits circuits permettant de jouer le rôle d'une mini carte graphique... au cas où l'ordinateur ne posséderait pas de cartes filles spécialisées dans telle ou telle tâche. A l'heure actuelle, la carte-mère elle-même a plutôt la dimension d'une puce que d'une vraie carte.
Langage compilé et langage interprété
Un langage interprété est un langage comme Python : le code n'est qu'un fichier texte au final et on demande à un programme installé sur l'ordinateur de l'interpréter (c'est pour cela que le nomme l'interpréteur !) pour fournir du langage machine.

En réalité, l'interpréteur n'est pas en contact direct avec le processeur mais passe par l'intermédiaire du système d'exploitation.
C'est pour cela que le même programme Python pourra fonctionner sur un ordinateur tourant sous Linux ou sur un ordinateur tourant sur Windows : si vous installez Python sur Windows, vous avez téléchargé la version permettant justement de tourner et discuter avec cet OS. Et votre OS est également la version capable de discuter avec votre processeur.
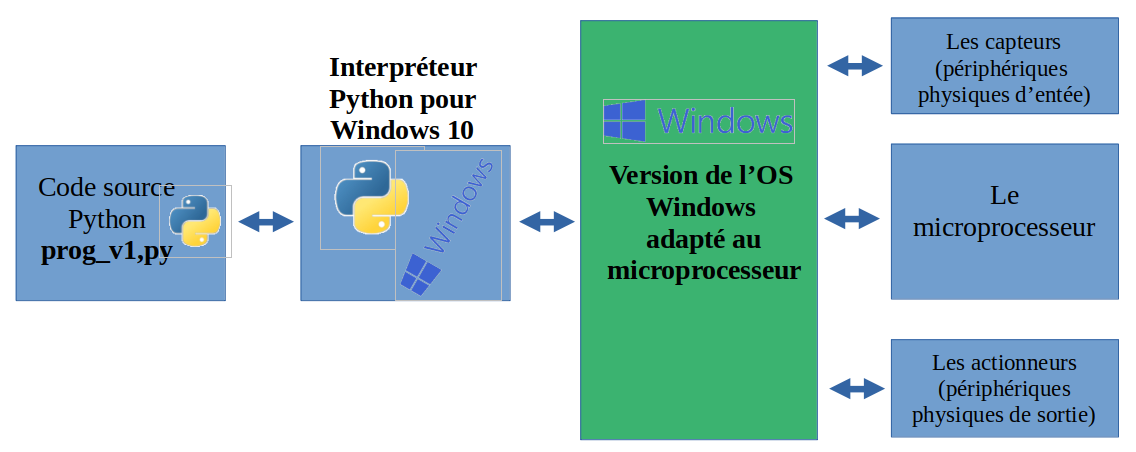
Comme vous le voyez, il y a deux niveaux de traductions et d'interprétation à faire, d'où la "lenteur" des langages interprétés.
Le cas d'un langage compilé comme le C par exemple est différent : cette fois, le code source va être compilé AVANT toute "exécution" directe. On crée donc un fichier exécutable, en langage machine. Il va donc traduire le code source texte C en langage machine adapté à la machine sur laquelle il tourne. Il doit donc être adapté à la fois à l'OS et au microprocesseur.
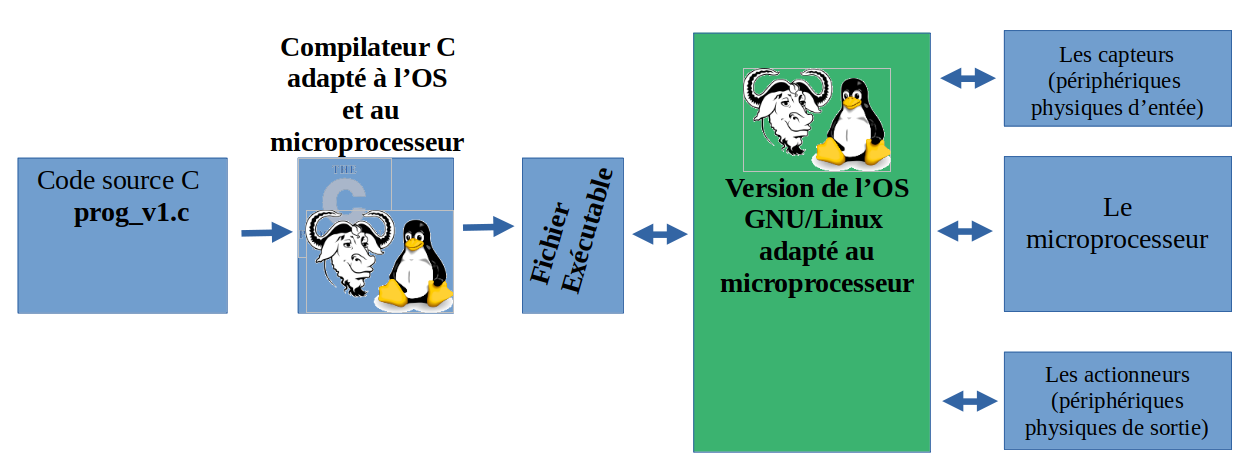
Avantage : beaucoup plus rapide (pas besoin d'interpréter, c'est déjà du langage machine).
Désavantage : problème de portabilité d'une machine à une autre. Même avec un même OS, un programme conçu pour un processeur 64 bits ne pourra pas tourner sur une machine 32 bits.
4 - Microcontrôleur
Avec la miniaturisation, vint la nécessité d'embarquer l'informatique dans des systèmes mobiles. On trouve ainsi des systèmes embarqués dans les voitures, les avions ou les systèmes d'alarme...
Chacun de ces systèmes a une tâche bien spécifique à réaliser une fois créé et le système ne nécessite donc pas d'avoir la polyvalence d'un 'vrai' ordinateur muni d'un microprocesseur.
Voici donc la liste des différences entre les microprocesseurs et les microcontrôleurs :
Les microcontrôleurs
- Les microcontrôleurs sont beaucoup moins polyvalents mais intégrent directement dans leurs puces un tas de fonctionnalité normalement externes aux microprocesseurs.
- Ils gagnent ainsi en autonomie, notamment énergétique. Cela leur permet de consommer moins d'énergie et donc de pouvoir fonctionner à partir de batteries de petite taille.
- Les microcontrôleurs diposent de deux zones différentes pour le programme et les données. Sur la plupart d'entre eux, on trouve :
- Une zone mémoire indépendante et non volatile contenant ce qu'on nomme le firmware, le programme de base permettant le fonctionnement du composant. Il s'agit donc d'une sorte de système d'exploitation en version minimaliste au possible. Il est installé de base par le constructeur, en usine mais peut éventuellement être modifié (mais c'est souvent assez complexe à faire). Cela évite notamment les manipulations accidentelles.
- Une zone mémoire non volatile dans laquelle on peut téléverser le programme qu'on veut faire fonctionner. A chaque redémarrage de microcontrôleur, ce programme va donc se relancer automatiquement. On peut donc programmer le processeur mais on doit utiliser une autre machine (un 'vrai' ordinateur) pour créer le programme et le téléverser dans le microcontrôleur.
- Une zone mémoire volatile permettant de stocker les données nécessaires au fonctionnement du programme. Cette mémoire s'efface donc à chaque fois qu'on éteint ou redémarrage le système.
Ces microcontrôleurs jouent donc un rôle très important dans l'informatique embarquée et ont principalement pour but
- de recueillir les informations fournies par des capteurs auxquels ils sont reliés
- de commander les actionneurs auxquels ils sont reliés
En conséquence, les microcontrôleurs sont optimisés pour les gestions des entrées / sorties avec l'extérieur et disposent souvent de plus de registres dédiés à cette communication qu'un microprocesseur. C'est pour cela qu'ils disposent également la plupart du temps de broches permettent de brancher le matériel électronique ou d'autres cartes.
En conclusion, les trois grandes différences avec un microprocesseurs sont :
- La moindre consommation et le fonctionnement autonome facilité des microcontrôleurs
- La spécialisation des microcontrôleurs dans la gestion des entrées / sorties avec des capteurs et actionneurs
- La moins grande polyvaence du microcontrôleur
A l'heure actuelle, il existe un très grand nombre de microcontrôleurs, à destination du grand public ou à destination des professionnels.
Parmi les plus connus, citons :
- Les microcontrôleurs basés sur le projet Arduino : se programment dans le langage Arduino, très proche du C++. Ci-dessous, la carte UNO, certainement l'une des plus célèbres car c'est sur ce modèle que commencent la plupart des gens.
- Les Micro:bits de la BBC : se programment en Python.


Comme on le voit sur la dernière photo, tout est relativement miniaturisé et présent sur circuit imprimé. Mais, il y a encore mieux en terme de miniaturisation.
5 - Système sur puce : SOC
A l'heure actuelle, les systèmes informatiques à l'intérieur des smartphones, des tablettes, des montres connectés ou des voitures sont encore plus miniaturisés.
On parle de système sur puce (system on chip SOC) : la puce ne contient pas juste le processeur, mais l'ensemble des composants d'un ordinateur classique. Sur la puce d'un système sur puce, on trouve donc :
- Le processeur
- La mémoire vive
- Les processeurs esclaves (le GPU, la carte son, la carte de chiffrement...)
- Beaucoup de capteurs, d'actionneurs ou de dispositifs de communication :
- cartes réseaux et antennes Wifi, Bluetooth, radio
- cartes et antenne GPS
- capteurs de type accéléromètre, magnétomètre...
- Le gestionnaire d'énergie

Quels sont les avantages d'un système sur puce (Soc, system on a chip en anglais) ? (connaissances exigibles pour le BAC)
- Une augmentation de la vitesse de communication des éléments de l'ordinateur résultant : la diminution des distances permet de gagner en rapidité car plus la distance augmente, plus les hautes fréquences ont tendance à provoquer des pertes d'informations
- La diminution de la taille des composants signifie également une baisse de la consommation énergétique globale du système
- La diminution de la consommation signifie également une diminution de l'échauffement et donc aucune nécessité d'équiper le système d'un ventilateur. Un système sur puce est donc silencieux !
Les systèmes sur puce (SOC) sont donc des systèmes informatiques rapides et encore moins gourmands en énergie (à capacité comparable) qu'un microprocesseur ou qu'un microcontrôleur.
Au delà de l'informatique embarquée, on trouve maintenant des Soc sur de vrais systèmes informatiques, pouvant jouer ou non le rôle de "vrais" ordinateurs.
L'un des modèles les plus connus de ce type de système est le célèbre Raspberry Pi qui est à la fois un Soc et un microcontrôleur car il dispose sur la plupart des modèles d'une capacité de gestion des entrées / sorties via des broches de connection.
Cerise sur le gateau ? Le Raspberry Pi est fourni de base avec Linux. Elle est pas belle la vie ?
Une souris, un clavier et un cable HDMI pour vous brancher sur votre télé ou un autre écran et vous avez un vrai ordinateur. Pour un prix d'environ 40 euros.

6 - FAQ
Rien pour le moment
Activité publiée le 14 02 2021
Dernière modification : 07 02 2023
Auteur : ows. h.