Fiche Lists avec Python
L'objet list de Python est un objet :
- itérable : on peut y accéder avec une boucle for nominative
- ordonné : les élément sont indexés par un numéro (on peut donc utiliser un for numérique)
- mutable : en français, on dira aussi modifiable après création ou muable.
Cette fiche détaille l'utilisation des listes de Python.
Attention pour la NSI : la structure de données list de Python porte un nom "problématique" car il ne s'agit pas vraiment de la structure de données nommées liste en informatique (cette structure sera vue en Terminale).
La liste de Python est utilisée en 1er NSI pour implémenter la structure de données nommée tableau (array en anglais). Mais il existe des différentes importantes entre les tableaux et ces listes.
Cette fiche traite bien des lists de Python et pas de la façon dont on les utilise au lycée.
Une fiche sur les listes de Python utilisées comme les tableaux est en cours d'élaboration.
1 - Déclaration
Le type list est l'un des objets natifs de Python.
On définit un list à l'aide d'un caractère séparateur signalant le début de la déclaration et on utilise un autre caractère pour signaler la fin de la déclaration.
Ces caractères délimitateurs sont :
- Le crochet ouvrant
[ - Le crochet fermant
]
Quelques exemples :
>>> ma_liste = [1, 'a', 45.2, "bonjour", 'b']
>>> type(ma_liste)
<class 'list'>
>>> print(ma_liste)
[1, 'a', 45.2, 'bonjour', 'b']
>>> ma_liste
[1, 'a', 45.2, 'bonjour', 'b']
On remarque donc que :
- La liste de Python précédente contient 5 éléments ordonnés
- Ces éléments peuvent être de natures différentes (en NSI, on n'utilisera pas cette propriété)
- Ces éléments sont séparés par des virgules
Lorsqu'on demande d'afficher une liste, Python rajoute des espaces après les virgules même si vous ne les avez pas placé lors de la déclaration.
>>> ma_liste = [1,'a',45.2,"bonjour",'b']
>>> ma_liste
[1, 'a', 45.2, 'bonjour', 'b']
On peut placer un objet (comme une liste) dans une liste :
>>> legumes = ['poivron','concombre','oignon']
>>> fruits = ['pomme','poire']
>>> ma_liste = [legumes,fruits]
>>> ma_liste
[ ['poivron', 'concombre', 'oignon'], ['pomme', 'poire'] ]
On voit bien que la liste ma_liste contient deux éléments uniquement. Par contre, ces éléments étant des listes, ils contiennent eux-mêmes d'autres éléments.
Pour créer une liste contenant x fois le même élément, on peut utiliser ceci :
>>> ma_liste = ['a']*10
>>> ma_liste
['a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a']
Pour créer une liste contenant une succession de nombres, on peut utiliser la fonction native range (qu'on détaille plus bas, lors de l'utilisation du for). Il faut alors l'associer à la fonction native list qui crée automatiquement une liste à partir d'un objet qu'on lui transmet. L'objet doit bien entendu être transformable en liste : il doit être composé d'une séquence d'éléments.
>>> ma_liste = list( range(0,11,2) )
>>> ma_liste
[0, 2, 4, 6, 8, 10]
On notera qu'on place ici des parenthèses puisque list(...) est bien une fonction native qui crée une liste. Pas de [] donc.
Dernier exemple : on peut créer une liste à partir d'un string :
>>> chaine = 'abcde'
>>> ma_liste = list( chaine )
>>> ma_liste
['a', 'b', 'c', 'd', 'e']
On peut également définir le contenu d'une liste par compréhension : on associe une boucle for sur un ensemble d'élément et on définit l'instruction à faire sur chacun des éléments.
>>> x = [i*i for i in range(0,20,2)]
>>> x
[0, 4, 16, 36, 64, 100, 144, 196, 256, 324]
Ici, on définit l'ensemble [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] avec range(0,20,2) : part de 0 et on compte de deux en deux tant que le résultat est strictement inférieur à 20.
Ensuite, pour chaque élément de [0, 2, 4, 6, 8, 10, 12, 14, 16, 18], on crée une liste en mettant l'élément au carré.
[02, 22, 42, 62, 82, 102, 122, 142, 162, 182]
2 - Objet ordonné et itérable
Un objet List est un ensemble ordonné d'éléments : on peut y accéder en utilisant un index chiffré.
On peut accéder au contenu de l'index i en utilisant des crochets : [ i ] .
Attention : la case du début est la case 0.
>>> ma_liste = [ 1, 'a', 45.2, "bonjour", 'b', ['fraises','framboises'] ]
>>> ma_liste[0]
1
>>> ma_liste[1]
'a'
>>> ma_liste[2]
45.2
>>> ma_liste[5]
['fraises', 'framboises']
La correspondance index - élément sur les 6 éléments de la liste donne ceci sur l'exemple
| Index | 0 | 1 | 2 | 3 | 4 | 5 |
| Elément | 1 | 'a' | 45.2 | 'bonjour' | 'b' | ['fraises', 'framboises'] |
On peut connaître la longueur d'une liste en utilisant la fonction native len avec len(x) où x est l'objet à étudier.
>>> x = [1, 'a', 45.2, "bonjour", 'b', ['fraises','framboises'] ]
>>> len(x)
6
On voit bien que x contient 6 éléments ( numérotés de 0 à 5, attention).
On peut alors lire le contenu de la liste en utilisant une boucle for numérique associée à la longueur de la chaîne :
>>> x = [1, 'a', 45.2, "bonjour", 'b', ['fraises','framboises'] ]
>>> for index in range(len(x)):
... print( x[index] )
...
1
a
45.2
bonjour
b
['fraises', 'framboises']
Ce n'est pas le moyen le plus simple de lire les éléments un par un. On peut également lire le contenu d'une liste en utilisant une boucle for nominative. ATTENTION : on perd néanmoins l'information sur le numéro d'index. En fonction de ce qu'on veut faire, on prend l'une ou l'autre des méthodes.
>>> x = [1, 'a', 45.2, "bonjour", 'b', ['fraises','framboises'] ]
>>> for element in x:
... print( element )
...
1
a
45.2
bonjour
b
['fraises', 'framboises']
Attention : ici element ne contient pas le numéro de la case mais bien le contenu de la "case".
3 - Lecture rapide des éléments d'une liste
Cette partie explique l'utilisation de la boucle for numérique ou des slices pour lire des bouts de liste. L'utilisation de slice est pratique mais ne figure pas au programme de 1er NSI. Vous ne pourrez donc pas avoir de questions les concernant à l'examen ou même des bouts de code les utilisant. On préfère vous faire manipuler les listes en utilisant simplement les boucles bornées (for). Par contre, c'est pratique et rapide. En projet, vous pouvez faire comme vous voulez.
Pour lire le contenu des éléments de 0 à 4 (c'est à dire tant que l'index est < 5), on peut écrire :
1
2
3 | x = [1, 'a', 45.2, "bonjour", 'b',['fraises','framboises']]
for index in range(0,6): # On peut écrire plus simplement in range(5)
print(x[index])
|
On notera que si le premier numéro du range est 0, on peut l'omettre. L'interpréteur remplira avec un 0 par défaut.
1
a
45.2
bonjour
b
On peut récupérer le bout de la liste correspondante avec les instructions suivantes :
1
2 | x = [1,' a', 45.2," bonjour", 'b', ['fraises','framboises']]
print(x[0:6]) # On peut écrire plus simplement x[:6]
|
[1, ' a', 45.2, ' bonjour', 'b']
Pour lire le contenu des cases de 2 à 4 (c'est à dire tant que l'index de la case est < 5), on peut écrire :
1
2
3 | x = [1, 'a', 45.2, "bonjour", 'b',['fraises','framboises']]
for index in range(2,5):
print(x[index])
|
45.2
bonjour
b
On peut récupérer la sous-liste correspondante avec les instructions suivantes :
1
2 | x = [1,' a', 45.2," bonjour", 'b', ['fraises','framboises']]
print(x[2:5])
|
[45.2, ' bonjour', 'b']
Pour lire le contenu des cases de 0 à 5 de deux en deux, on peut écrire :
1
2
3 | x = [1, 'a', 45.2, "bonjour", 'b',['fraises','framboises']]
for index in range(0,6,2):
print(x[index])
|
1
45.2
'b'
On peut récupérer la sous-liste correspondante avec les instructions suivantes :
1
2 | x = [1,' a', 45.2," bonjour", 'b', ['fraises','framboises']]
print(x[0:6:2])
|
[1, 45.2, 'b']
On peut omettre de noter certains paramètres. Il suffit de ne pas le mettre mais de placer le : suivant.
- Si on ne place pas le caractère initial, l'interpréteur remplacera par défaut par 0.
- Si on ne place pas le caractère final, l'interpréteur ira jusqu'au bout de la liste.
- Si on ne place pas la valeur de l'itération, l'interpréteur augmentera de 1 en 1 par défaut.
Ainsi les cas suivants sont équivalents :
>>> x = [1,'a',45.2,"bonjour",'b',['fraises','framboises']]
>>> x[0:4:1]
[1, 'a', 45.2, 'bonjour']
>>> x[0:4]
[1, 'a', 45.2, 'bonjour']
>>> x[:4]
[1, 'a', 45.2, 'bonjour']
Cela veut donc dire de ne garder que les caractères ayant un index strictement inférieur à 4.
Si on place le : à la fin, cela veut dire de ne garder que les éléments à partir de l'index 4 inclus.
>>> x = [1,'a',45.2,"bonjour",'b',['fraises','framboises']]
>>> x[4:]
['b', ['fraises', 'framboises']]
Et un dernier truc pour la route : comment inverser une liste ? Il suffit de lui dire de compter non pas en 1 mais en -1 !
Ici, je ne précise ni le début de la liste, ni la fin. J'ai donc noter :: pour indiquer que je donne uniquement la valeur de l'itération.
>>> x = [1,'a',45.2,"bonjour",'b',['fraises','framboises']]
>>> x[::-1]
[['fraises', 'framboises'], 'b', 'bonjour', 45.2, 'a', 1]
Pour lire une liste à l'envers, on peut même faire mieux encore avec la fonction native reversed qui va renvoyer les index dans le sens inverse. C'est une fonction optimisée pour parcourir un objet itérable en sens inverse, elle sera donc normalement plus rapide que la méthode précédente qui est plus généraliste.
1
2
3 | x = [1,'a',45.2,"bonjour",'b',['fraises','framboises']]
for element in reversed(x):
print(element)
|
Par contre, pour créer un nouveau string inversé, inverse = x[::-1] est plus court à taper que de taper une boucle.
4 - Mutable
Cela veut dire qu'on peut modifier le contenu d'une liste après sa création, sans modifier l'identifiant-mémoire de la liste.
Première conséquence : la modification par interaction directe est possible.
On peut modifier une liste en utilisant un code de ce type (contrairement aux strings) :
>>> x = ['Bonjour', ' à ', 'tous !']
>>> x
['Bonjour', ' à ', 'tous !']
>>> id(x)
2676573460296
>>> x[1] = ' les '
>>> x[2] = 'gens !'
>>> x
['Bonjour', ' les ', 'gens !']
>>> id(x)
2676573460296
On voit bien que les éléments de x ont changé par modification directe. Par contre, x a bien gardé le même identifiant : x pointe donc toujours vers le même objet, ce n'est pas un objet différent ayant écrasé le précédent.
Deuxième conséquence : l'utilisation de la modification par l'opérateur + peut être contre-productive.
Lorsqu'on "modifie" une liste en utilisant ce +, on crée en réalité un nouvel objet. Il faut être vigilant sur ce point car on pourrait croire que puisque les listes sont mutables (modifiables) ont garde le même objet.
>>> x = [1,2,3]
>>> id(x)
2676573390920
>>> y = [4,5,6]
>>> x = x + y
>>> x
[1, 2, 3, 4, 5, 6]
>>> id(x)
2676573390856
On voit ici clairement qu'on utilise le même nom x mais qu'on fait référence à deux entités différentes en mémoire.
On peut se demander en quoi c'est génant. On change d'id. Et alors ?
Pour comprendre le problème, il faut avoir connaissance de la façon dont se passe la 'copie' d'une liste via l'opérateur =. C'est la partie suivante.
5 - Test d'égalité de deux listes
Voyons ce qu'implique pour la 'copie' de listes :
>>> x = [1,2,3]
>>> x
[1, 2, 3]
>>> id(x)
2676573391048
>>> y = x
>>> y
[1, 2, 3]
>>> id(y)
2676573391048
Jusqu'à présent, rien de nouveau par rapport aux strings. Python ne crée pas réellement un nouvel objet mais juste un alias : il pointe vers la même case mémoire : l'id est toujours 2676573391048.
Si on s'arrange pour modifier la liste x (sans utilisation destructrice d'un + par exemple), x et y vont continuer à pointer vers le même objet et modifier x va également permettre à son alias d'afficher la modification.
>>> x = [1,2,3]
>>> y = x
>>> id(x)
2676573391048
>>> id(y)
2676573391048
>>> x
[1,2,3]
>>> y
[1,2,3]
>>> x[0] = 10
>>> x
[10, 2, 3]
>>> id(x)
2676573391048
>>> y
[10, 2, 3]
>>> id(y)
2676573391048
L'utilisation du signe = dans y = x crée un alias de x et non pas réelleemnt une nouvelle liste. On obtient juste deux façons de nommer le même objet.
Alors, en quoi l'utilisation du + est-elle à éviter ?
Si vous vouliez garder un lien entre x et y, l'utilisation de + va la briser : x = x + ['a'] ne va pas réellement rajouter 'a' à votre liste : cela va créer une nouvelle liste à partir de l'ancienne liste x et du nouvel élément. Mais votre nouvelle liste x ne va plus pointer vers la même adresse mémoire que y !
Un exemple pour concrétiser cela :
>>> x = [1,2,3]
>>> x
[1, 2, 3]
>>> id(x)
2676573235400
>>> y = x
>>> y
[1, 2, 3]
>>> id(y)
2676573235400
>>> x = x + [4]
>>> x
[1, 2, 3, 4]
>>> id(x)
2676573390856
>>> y
[1, 2, 3]
>>> id(y)
2676573235400
On voit bien que x et y pointent vers le même objet au début mais que lorsqu'on modifie x avec + son identifant change. Par contre, celui de y ne suit pas.
Et si je veux juste une copie d'une liste ? Dans ce cas, il faut utiliser une méthode particulière copy qu'on applique à la liste :
>>> x = [1,2,3]
>>> x
[1, 2, 3]
>>> id(x)
2676573518344
>>> y = x.copy()
>>> y
[1, 2, 3]
>>> id(y)
2676573389384
On obtient donc une liste ayant un contenu identique mais ne pointant pas vers les mêmes zones.
On peut obtenir un code assez similaire avec ceci :
>>> x = [1,2,3]
>>> x
[1, 2, 3]
>>> id(x)
2676573518344
>>> y = x[:]
>>> y
[1, 2, 3]
>>> id(x)
2676573518472
Ici, on crée une nouvelle liste car on va lire le contenu de a avec x[:] qui est interprété en x[0:len(x):1], c'est dire qu'il lit toute la liste de l'élément 0 à l'élément final, de un en un.
Autre manière de faire :
>>> x = [1,2,3]
>>> x
[1, 2, 3]
>>> id(x)
2676573518344
>>> y = x + []
>>> y
[1, 2, 3]
>>> id(x)
2676573518472
En gros, l'utilsation du + avec une liste vide [] va provoquer la création d'un nouvel objet avec une adresse différente de x mais avec le même contenu. Ca fonctionne mais autant utiliser la méthode qui va bien.
Copie d'une liste contenant une liste : Si vous avez une liste qui contient des listes et que vous désirez que ces listes aussi soient des copies, il faut utiliser la méthode deepcopy.
6 - Test d'égalité de deux listes
On peut comparer deux listes de deux façons :
- A l'aide d'un test logique
x == yqui teste l'égalité de contenu. - A l'aide d'un test
x is yqui teste l'égalité d'identité (même objet). On peut dire queisteste si x et y sont deux alias du même objet.
Si vous n'allez pas plus loin dans cette sous-partie, retenez ceci : Pour comparer le contenu de deux listes, utilisez toujours ==.
Ici, on crée deux listes a et b de contenu identique mais ayant des identifiants (ou adresses) différents.
>>> a = [1,2,3]
>>> a
[1, 2, 3]
>>> id(a)
2676573169992
>>> b = [1,2,3]
>>> b
[1, 2, 3]
>>> id(b)
2676573518728
>>> a == b
True
>>> a is b
False
C'est clair : Python parvient à dire que les deux listes ont le même contenu mais ne sont pas réellement le même objet. Ainsi modifier a ne modifie pas b.
Donc, attention : pour tester l'égalité du contenu, il faut utiliser ==.
7 - Tests d'appartenance
On ne peut pas directement savoir si une liste est incluse dans une autre. Il faudra utiliser une fonction ou une méthode propre aux listes.
Par contre, pour savoir si une liste a contient un élément element, on peut par contre utiliser le test in :
>>> a = [1,2,3,4]
>>> element = 3
>>> element in a
True
>>> 7 in a
False
>>> 2 in a
True
Attention, le test vérifie aussi le type :
>>> a = [1,2,3,4]
>>> 2 in a
True
>>> "2" in a
False
8 - Méthodes d'ajout et suppression des éléments de liste
On peut ajouter et supprimer des éléments en utilisant les intervalles (le slicing). Mais il existe aussi des méthodes qui permettent de rajouter ou de supprimer des éléments de la liste sans modifier l'adresse de la liste : on reste donc réellement sur le même objet, on ne changera pas son numéro d'identification.
Pour chaque méthode, je fournis dans l'exemple l'équivalent en utilisant un intervalle.
Des exemples d'utilisation se trouvent sous le tableau.
Attention : les crochets [ ] indiquent que l'argument qu'on y touve est optionnel.
| Méthode | Action réalisée |
|---|---|
list.append(x) |
Rajoute l'élément Si |
list.extend(x_iter) |
Comme au dessus mais l'argument On rajoute alors les éléments internes de |
list.insert(i,x) |
Rajoute l'élément Si on utilise |
list.pop([i]) |
Supprime de la liste l'élément situé à la position i et le renvoie en retour. On peut donc stocker l'élément retiré dans une variable au besoin en notant par exemple Le paramètre i est optionnel (notation [i]). Si vous utilisez simplement Permet de gérer les flux en file ou en pile. |
list.remove(x) |
Supprime de la liste le premier élément de la liste qui est égal à Une exception est levée s’il existe aucun élément avec cette valeur. |
list.pop([i]) |
Supprime de la liste l'élément situé à la position i et le renvoie en retour. On peut donc stocker l'élément retiré dans une variable au besoin en notant par exemple Le paramètre i est optionnel (notation [i]). Si vous utilisez simplement |
str.count(sub[, start[, end]]) | Renvoie le nombre d'occurrences du string sub dans le string str. On peut rajouter les numéros de début et de fin des cases à analyser. |
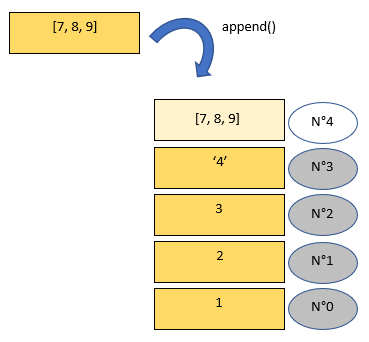
Exemple : pour list.append(x)
>>> a = [1,2,3]
>>> a
[1, 2, 3]
>>> a.append('4')
>>> a
[1, 2, 3, '4']
>>> b = [7,8,9]
>>> a.append(b)
>>> a
[1, 2, 3, '4', [7, 8, 9]]
On remarque que le contenu de a est modifié par la méthode. Il ne faut surtout pas noter quelque chose comme a = a.append(b) qui crée alors une nouvelle liste nommée a qui va écraser l'ancienne. La modification se fait directement.
Attention : on rajoute l'élément x, on ne rajoute pas les éléments de x si x est itérable. Ici, on a bien rajouté une liste b dans la liste a et pas les élements de b dans a.
Le code équivalent en slicing serait :
>>> a[len(a):] = ['4']
>>> a[len(a):] = [b]
On rajoute les éléments d'une liste à la suite du dernier élément. D'où la présence du : après len(a).
Cette méthode permet donc de considérer les listes comme des piles de livres : on rajoute les éléments au dessus des derniers éléments.
Exemple : pour list.extend(x_iter)
>>> a = [1,2,3]
>>> a
[1, 2, 3]
>>> b = [7,8,9]
>>> a.extend(b)
>>> a
[1, 2, 3, '4', 7, 8, 9]
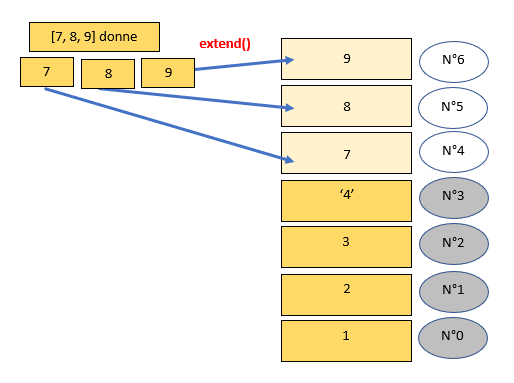
Le code équivalent avec l'intervalle serait :
>>> a[len(a):] = b
On rajoute les éléments d'une liste à la suite du dernier élément. D'où la présence du : après len(a).
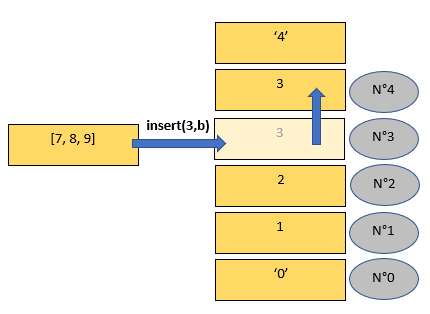
Exemple : pour list.insert(i,x)
>>> a = [1,2,3]
>>> a
[1, 2, 3]
>>> a.insert(0,'0')
>>> a
['0', 1, 2, 3]
>>> a.insert(len(a),'4')
>>> a
['0', 1, 2, 3, '4']
>>> b = [7,8,9]
>>> a.insert(3,b)
>>> a
['0', 1, 2, [7, 8, 9], 3, '4']
On rajoute '0' en tant que premier élément avec insert(0, ...).
On rajoute '4' en tant que dernier élément (d'ailleurs utiliser a.insert(len(a),truc) revient à utiliser a.append(truc).
On rajoute une liste b avant l'élément qui était à la position 3 avant cela. N'oubliez pas que le premier élément est l'élément 0.
Attention : on rajoute l'élément x, on ne rajoute pas les éléments de x si x est itérable. Ici, on a bien rajouté une liste b dans la liste a et pas les élements de b dans a.
Au final, on obtient alors :
insert() insère ailleurs qu'à la fin de la liste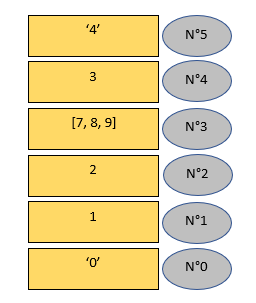
Pour faire la même chose avec les éléments de la liste b, c'est plus compliqué puisque x ne peut être qu'un élément unique :
>>> for element in b[::-1] :
a.insert(3,element)
>>> a
['0', 1, 2, 7, 8, 9, 3, '4']
Pourquoi commencer par le dernier élément ? Tout simplement car on pousse tout vers la droite à chaque fois :
['0', 1, 2, 3, '4'] devient :
['0', 1, 2, 9, 3, '4'] qui devient :
['0', 1, 2, 8, 9, 3, '4'] qui permet d'obtenir :
['0', 1, 2, 7, 8, 9, 3, '4']
Le code équivalent avec l'intervalle pour insérer une liste b serait :
>>> a = [1,2,3]
>>> b = [7,8,9]
>>> a[3:3] = [b]
>>> a
[1, 2, 3, [7, 8, 9]]
On place l'élément entre la position n°3 pour le début et la position n°3 pour la fin. On pousse donc les anciens éléments 3 et plus.
Notez qu'on place les crochets autour de b pour dire de rajouter la liste et pas ses éléments.
Pour rajouter les éléments de b, nous aurions utilisé b, sans les crochets. C'est plus facile qu'avec la méthode.
>>> a = [1,2,3]
>>> b = [7,8,9]
>>> a[3:3] = b
>>> a
[1, 2, 3, 7, 8, 9]
Exemple : pour list.pop([i])
>>> a = ['0', 1, 2, [7, 8, 9], 3, '4']
>>> a
['0', 1, 2, [7, 8, 9], 3, '4']
>>> a.pop()
'4'
>>> a
['0', 1, 2, [7, 8, 9], 3]
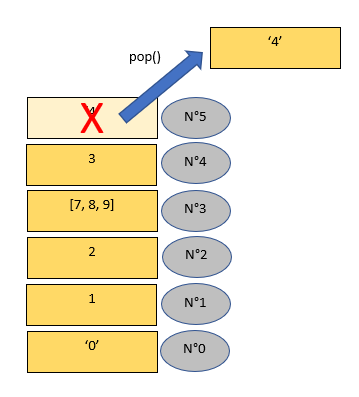
On voit qu'on supprime le dernier élément et que la méthode renvoie l'élément qu'elle a détruit. Nous aurions pu noter plutôt ceci pour récuperer la valeur :
>>> a = ['0', 1, 2, [7, 8, 9], 3, '4']
>>> a
['0', 1, 2, [7, 8, 9], 3, '4']
>>> z = a.pop()
>>> a
['0', 1, 2, [7, 8, 9], 3]
>>> z
'4'
L'association des méthodes append() et pop() permet donc réellement de gérer les informations comme une pile : on rajouter toujours au sommet et on traite d'abord le sommet la pile. Ainsi, ce qui est en début de liste et en bas de la pile et ne pourra être traiter qu'une fois que ce qui est au dessus sera traité. Si vous avez un système dont la priorité est de réagir d'abord aux derniers événements, cette association de méthodes est faite pour vous :
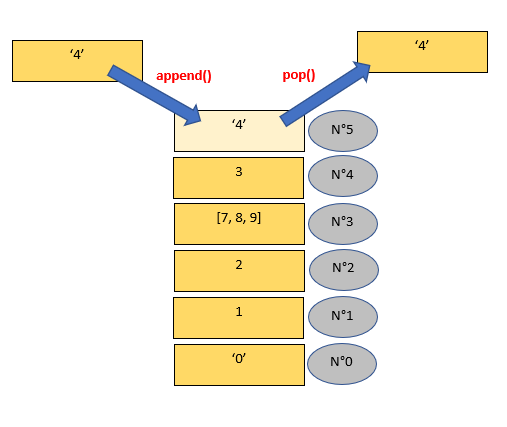
Bien. Imaginons maintenant que nous voulions supprimer et récupérer la liste [7,8,9]. Elle est en position 3, il doit donc utiliser la méthode pop(3) :
>>> a = ['0', 1, 2, [7, 8, 9], 3]
>>> a
['0', 1, 2, [7, 8, 9], 3]
>>> z = a.pop(3)
>>> a
['0', 1, 2, 3]
>>> z
[7, 8, 9]
Une utilisation concrète est le pop(0) pour créer l'inverse de la pile à savoir : la file. Comme dans une file d'attente. Le premier arrivé sera le premier servi. Et on rajoute les derniers à l'arrière :
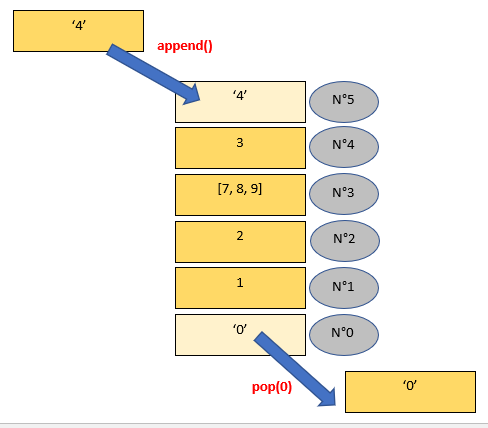
Un autre exemple :
>>> a = ['a', 'b', 'c', 'd']
>>> a
['a', 'b', 'c', 'd']
>>> z = a.pop(0)
>>> a
['b', 'c', 'd']
>>> f"On traite le cas de l'élément {z}"
On traite le cas de l'élément a
>>> z = a.pop(0)
>>> a
['c', 'd']
>>> f"On traite le cas de l'élément {z}"
On traite le cas de l'élément b
Exemple : pour list.remove(x)
>>> a = ['a', 'b', 'c', 'd', 'a']
>>> a
['a, 'b', 'c', 'd', 'a']
>>> a.remove('a')
>>> a
['b', 'c', 'd', 'a']
>>> a.remove('d')
>>> a
['b', 'c', 'a']
>>> a.remove('4')
ValueError: list.remove(x): x not in list
Notez bien qu'on enlève d'abord les éléments ayant le numéro d'index le plus petit. L'exception ValueError devra être gérée par l'utilisation d'un try ou avec une vérification préliminaire à l'action du remove.
Il existe également une fonction permettant de supprimer un élément d'une liste. La fonction del().
Quelques exemples d'utilisation où j'ai placé en bleu les valeurs ciblées par le del situé en dessous.
>>> x = [i*i for i in range(0,20,2)]
>>> x
[0, 4, 16, 36, 64, 100, 144, 196, 256, 324]
>>> del x[1]
>>> x
[0, 16, 36, 64, 100, 144, 196, 256, 324]
>>> del x[2]
>>> x
[0, 16, 64, 100, 144, 196, 256, 324]
>>> del x[-1]
>>> x
[0, 16, 64, 100, 144, 196, 256]
>>> del x[1:3]
>>> x
[0, 100, 144, 196, 256]
>>> del x[::2]
>>> x
[100, 196]
9 - Autres méthodes
Il existe d'autres méthodes que celles qui permettent de rajouter ou de supprimer des éléments dans les listes.
Des exemples d'utilisation se trouvent sous le tableau.
Attention : les crochets [ ] indiquent que l'argument qu'on y touve est optionnel.
| Méthode | Action réalisée |
|---|---|
list.clear() |
Supprime tous les éléments d'une liste, qui se retrouve donc vide. |
list.index(x[, start[, end]]) |
Renvoie le plus petit numéro d'index correspondant à l'élément x. Renvoie une exception Les valeurs start et end sont optionnelles et se comporte comme un intervalle. Les valeurs par défaut sont 0 et la longueur de la liste. |
list.count(x) |
Renvoie le nombre de fois où l'élément x est présent dans la liste. |
list.sort(key=None, reverse=False) |
Trie les éléments sur place, (les arguments peuvent personaliser le tri, voir sorted() pour leur explication). |
list.copy() |
Renvoie une copie superficielle de la liste. Équivalent à a[:]. |
list.reverse() |
Inverse l’ordre des éléments de la liste. |
Exemple : pour list.clear()
>>> a = ['a', 'b', 'c', 'd', 'a']
>>> a
['a, 'b', 'c', 'd', 'a']
>>> a.clear()
>>> a
[]
Exemple : pour list.index(x[, start[, end]])
>>> a = ['a', 'b', 'c', 'd', 'a']
>>> a
['a, 'b', 'c', 'd', 'a']
>>> a.index('a'')
0
>>> a.index('d')
3
>>> a.index('z')
ValueError: 'z' is not in list
Notez bien qu'on détecte d'abord les éléments ayant le numéro d'index le plus petit. L'exception ValueError devra elle être gérer par l'utilisation d'un try ou d'un count.
Exemple : pour list.count(x)
>>> a = ['a', 'b', 'c', 'd', 'a']
>>> a
['a, 'b', 'c', 'd', 'a']
>>> a.count('a')
2
>>> a.count('b')
1
>>> a.count('z')
0
Article publié le 10 11 2019
Dernière modification : 10 11 2019
Auteur : ows. h.