2 - Système d'exploitation
Si on schématise, un ordinateur est composé de plusieurs parties qui communiquent entre elles :
- Un processeur qui gère l'exécution des instructions et qui réalise les évaluations demandées.
- Une mémoire rapide volatile (qui s'efface à l'arrêt du système).
- Une mémoire rapide non volatile (qui ne s'efface pas à l'arrêt).
- Des mémoires lentes de stockage gros volume (disque dur, clé USB...)
- Des périphériques divers et variés (écran, clavier, souris, écran tactile...)
Ce processeur tient aujourd'hui sur une simple puce électronique.
On parle de mémoire vive, ou de RAM (Random Access Memory). C'est dans cette mémoire qu'on place les programmes et les données en cours d'exécution. RAM indique bien qu'on peut accèder à n'importe quelle case mémoire à coût CONSTANT.
On parle de mémoire morte ou de ROM contenant notamment les instructions que doit faire l'ordinateur au démarrage
Et le système d'exploitation dans tout ça ?
C'est le centre de cette activité.

Prérequis : l'activité Python Interface Console pour comprendre ce qu'est une fonction d'interface
Evaluation ✎ : -
Documents de cours : open document ou pdf
1 - Démarrage
Processeur ou CPU
Le centre de commande de l'ordinateur est le processeur. C'est lui qui va prendre la main au démarrage. On le nomme également CPU pour Central Processing Unit.
Le CPU est composé principalement :
- De l'Unité Arithmétique et Logique (UAL) : capable de récupérer des octets en mémoire pour effectuer effectuer différents calculs ou opérations d'écriture.
- De l'unité de contrôle (UDC) : capable de récupérer des octets en mémoire pour les interpréter en instructions. Elle commande alors l'UAL pour que celle-ci fasse l'opération demandée.
- Des registres : de très petites mémoires volatiles mais très rapides car proches des deux circuits précédents.
Les registres étant volatiles, ce n'est pas eux qui peuvent stocker les programmes qui se lançent au démarrage...
Alors, où se trouve le système de démarrage ?
RAM : Random Access Memory
Si le CPU est le centre de commande de l'ordinateur, la RAM est sa mémoire à court terme. On place dans la RAM :
- les instructions des programmes en cours d'utilisation et
- les données en cours d'utilisation.
En 2022, l'unité de mesure de cette mesure est typiquement le Giga-octet (Go) (1 Go représente un milliard d'octets).
Il s'agit d'une mémoire rapide mais volatile : elle se vide à chaque fois qu'on éteint l'ordinateur.
D'ailleurs, cela veut dire qu'au démarrage de l'ordinateur, la RAM est vide !
Alors, où se trouve le système de démarrage ?
Mémoire de masse : disque dur, clé USB ou disque SSD
Ce sont des zones mémoires de bien plus grande capacité que la RAM mais également bien moins rapides.
Par contre, elles sont non volatiles.
Le programme de démarrage est-il de ce type de mémoire ?
Et bien non... Ce sont des périphériques extérieurs et au démarrage, le CPU n'y a pas accès tout simplement car il ne sait pas comment leur parler (ça dépend de la technologie de la mémoire, de sa marque, de sa capacité...)
Donc le programme de démarrage ne peut pas être dans une mémoire de masse...
Alors, où se trouve le système de démarrage ?
01° Rechercher les caractéristiques suivantes de votre ordinateur (plutôt facile) puis de votre smartphone (c'est déjà plus difficile) :
- Nom et type du processeur
- Fréquence du processeur si possible (en Hz, nombre d'opérations par seconde en gros)
- Nombre de coeurs (nombre de cerveaux indépendants pouvant travailler en même temps)
- Taille de la RAM
Suivre pour cela les indications suivantes :
- Ordinateur sous système d'exploitation Windows :
- Cliquez sur Démarrer, sélectionnez Paramètres (icône d’engrenage), et allez dans Système. Sélectionnez Informations système.
- Ordinateur sous système d'exploitation Linux avec interface graphique (Ubuntu par exemple) :
- Cliquez sur l'icône Paramètres, sélectionnez à propos.
- Ordinateur sous système d'exploitation Linux même sans interface graphique :
- Ouvrir un terminal, taper cat /proc/cpuinfo
- Smartphone sous système d'exploitation Android :
- En réalité, c'est pas si facile que cela, notamment car les smartphones sont vendus d'un bloc. Vous pouvez déjà chercher sur le Web les caractéristiques de votre appareil
- En cliquant sur Parametres puis à propos, vous devriez obtenir au moins les informations sur votre RAM.

Si vous ne savez pas ouvrir un terminal sous Ubuntu, cherchez cette icône :

Question : Où se trouve alors le programme de démarrage votre ordinateur ? En effet, il ne peut être ni dans les registres, ni dans la RAM, ni dans la mémoire de masse...
Voici, enfin, la réponse.
Etape 1 : Lecture et activation du BIOS ou de l'UEFI.
Au démarrage, le CPU est configuré pour exécuter une zone particulière d'une petite mémoire non volatile qu'on nomme souvent "mémoire morte".
Pourquoi parle-t-on de mémoire morte ou ROM ? Cela veut dire Read Only Memory. Il s'agit d'une mémoire de taille plutôt réduite mais non volatile : elle ne s'efface pas en l'absence d'alimentation. On parle encore aujourd'hui de mémoire morte car, au début de l'informatique, les informations qui s'y trouvaient ne pouvaient plus être modifiées. Ce n'est plus le cas aujourd'hui, mais le terme est resté.
Que ramene-t-on de la ROM ? Un premier programme qui se charge de gérer le fonctionnement le plus primaire du système : il permet juste de savoir comment gérer les entrées/sorties basiques (clavier, écran, et surtout le disque dur...).
Ce programme est :
- soit le BIOS (pour Basic Input Output System) sur les systèmes un peu anciens. Ecrit en assembleur, ce programme est peu adaptable et présente quelques problèmes de sécurité.
- soit l'UEFI (pour Unified Extensible Firmware Interface) sur certains systèmes plus récents. Ecrit en C, il a été concu pour rendre moins interdépendant l'aspect matériel et l'aspect logiciel.
Quelle est la première action de ce premier programme ?
Etape 2 : Chargement et exécution du chargeur d'amorçage
Maintenant qu'on dispose des instructions permettant d'interagir avec les éléments centraux de l'ordinateur, on lance alors les instructions d'un autre petit programme qui se nomme le chargeur d'amorçage (bootloader en anglais). Le système va donc copier les instructions de ce programme depuis le stockage de masse (lent) vers la RAM (rapide) et le CPU va pouvoir commencer à l'exécuter en allant puiser les instructions directement dans la RAM. C'est cela qu'on nomme un processus.
La plupart du temps, le chargeur d'amorçage n'est pas vu par l'utilisateur puisque son rôle se limite à charger le système d'exploitation (OS) en mémoire vive (RAM) de façon à le faire exécuter par le processeur (CPU). Après quelques secondes d'écran noir où apparaissent quelques lignes de texte, on voit les premiers écrans signalant qu'on est sur Windows, Linux, iOS ou Android par exemple.
Mais le chargeur d'amorçage permet éventuellement de choisir le système d'exploitation à utiliser si vous en avez plusieurs installés ou de lancer le système en mode sans échec... Avec deux systèmes, cela se nomme le dual-boot. On obtient alors un premier écran souvent purement textuel sur lequel on doit choisir le système d'exploitation à lancer. Pratique si on veut utiliser Linux, sans pour autant se passer de Windows lorsqu'on en a besoin.

Etape 3 : Chargement du noyau du système d'exploitation voulu
Une fois le choix du système réalisé, on charge en RAM les instructions d'un nouveau programme : le système d'exploitation. Les instructions sont lues depuis la mémoire de masse et placées en RAM.
En anglais, Système d'Exploitation se dit Operating System et son acronyme est OS.
En réalité, on ne charge initialement que les parties "fondamentales" du système d'exploitation (OS) en mémoire vive (RAM). Cet ensemble de petits programmes fondamentaux se nomme le noyau en français et le kernel en anglais.

Voilà.
La RAM contient maintenant le noyau du système d'exploitation, formé d'un ensemble de programmes. Mais à quoi servent-ils ?
2 - Accès à un terminal Linux
Il est plus que probable que vous connaissiez surtout le système d'exploitation nommé Windows.
Trois solutions pour travailler sous Linux aujourd'hui :
- Utiliser l'un des PC Linux de la salle d'informatique
- Utiliser une connexion internet pour contrôler un terminal Linux à distance (solution Hauts de France)
- Utiliser une connexion internet pour contrôler un terminal Linux à distance (solution Always Data)
Les trois sections sont au moins à lire. La fiche de connexion chez Alwaysdata vous permettra de vous créer un compte chez cet hébergeur Web pour réaliser votre première page réellement accessible sur Internet. L'option B vous permettra d'un peu travailler si vous n'avez pas accès à vos mails.
Option a - Un ordinateur sous Linux
Sous Linux-Ubuntu, vous trouverez l'accès à un terminal dans les applications. Son icône est un petit écran noir.
02° Ouvrir un émulateur de terminal en cliquant sur l'icône.
Si vous ne le trouvez pas, cliquez sur l'icône en bas à gauche, celle avec 9 carrés. Vous allez atteindre le menu des programmes. En cliquant sur les points à droite de l'écran, vous allez pouvoir passer sur l'écran 2 ou 3.
Vous devriez obtenir ceci :

Décoder les informations visibles sur le terminal
rv@monordi:~$ _
On voit que l'utilisateur se nomme rv et qu'il est connecté (@) sur un ordinateur qui se nomme monordi.
Le caractère tilde ~ veut dire que le terminal pointe pour l'instant sur le répertoire personnel de l'utilisateur.
Enfin le signe dollar $ est l'invite de commande. L'invite de commande Windows est le signe >.
03° Sur l'exemple ci-dessous :
totolasticot@monordi:/bin$ _
- Comment se nomme l'utilisateur ?
- Sur quel poste est-il connecté ?
- Sur quel répertoire pointe le terminal pour l'instant ?
- Dans l'adresse /bin, que symbolise le premier slash / ? Cette adresse est-elle une adresse absolue ou une adresse relative ?
...CORRECTION...
- Il s'agit de l'utilisateur totolasticot.
- Il est connecté sur la machine monordi.
- Et le terminal pointe à ce moment sur le répertoire /bin.
- Le premier slash symbolise la racine de la machine. Il s'agit donc d'une adresse absolue sur la machine.
04° Voici un aperçu de deux instructions que le terminal va transmettre au système d'exploitation en tant qu'appel système :
- La commande whoami (qu'on peut traduire par "qui suis-je ?" en français) affiche le nom de l'utilisateur ayant lancé cette commande.
- La commande pwd (pour "print working directory", qu'on peut traduire par "affiche le répertoire courant" en français) provoque l'affichage du répertoire sur lequel pointe actuellement le terminal.
rv@monordi:~$ whoami
rv
rv@monordi:~$ pwd
/home/rv
Question 1 : les réponses fournies sont-elles bien compatibles avec l'étude de la ligne décrivant l'utilisateur ?
Question 2 : d'après la réponse du pwd, à quel répertoire fait référence en réalité le symbole tilde ~ ?
...CORRECTION...
Oui, il s'agit de bien l'utilisateur rv.
Et le terminal pointe bien à ce moment sur le répertoire /home/rv qui est le répertoire personnel de l'utilisateur. Répertoire qu'on représente plus simplement par ~.
Option B - Passer par un site proposant l'accès à une console Linux
Le site https://bellard.org/jslinux/ vous propose de prendre en main une machine virtuelle Linux.
Si vous cliquez sur la première possibilité, vous obtiendrez l'accès à une machine virtuelle Linux.
05° Utiliser le cas 1 ou 2 en fonction de vos accès. Comment se nomme ici l'utilisateur ? A quel endroit se trouve le répertoire personnel de l'utilisateur, celui symbolisé par le tilde ?
~ $ whoami
user
~ $ pwd
/home/user
~ $ _
...CORRECTION...
Il s'agit juste de user.
Le terminal pointe bien à ce moment sur le répertoire /home/user qui est le répertoire personnel de l'utilisateur. Répertoire qu'on représente plus simplement par ~.
Option C - Passer par un hébergeur Web
Passer par un hébergeur peut être un bon choix puisqu'à partir de là, vous aurez un compte actif gratuit et vous pourrez commencer à y placer des pages et applications Web qui seront vraiment accessibles depuis un accès Internet.
Je vous présente ici une manière d'accéder à une telle console en passant par l'hébergeur alwaysdata qui propose des interfaces assez claires permettant d'installer plein de choses basées sur Python.
Si vous choisissez cette solution (ce n'est pas long, il vous faut juste un e-mail valide), voici la fiche qui vous permettra de créer ce compte :
ACCESS SSH VIA LE WEB CHEZ ALWAYSDATA
✎ 06° Vous avez le résultat d'une connexion réussi en SSH avec alwaysdata ci-dessous
testprofad@ssh1:~$ _
- Comment se nomme l'utilisateur ?
- Sur quel poste est-il connecté ?
- Sur quel répertoire pointe le terminal pour l'instant ?
✎ 07° Observer les réponses fournies lors de l'utilisation du terminal. Répondre ensuite aux questions (les explications se trouvent question 2 si vous les avez zappé...)
testprofad@ssh1:~$ whoami
testprofad
testprofad@ssh1:~$ pwd
/home/testprofad
Question 1 : les réponses fournies sont-elles bien compatibles avec l'étude de la ligne décrivant l'utilisateur ?
Question 2 : à quel endroit se trouve le répertoire personnel de l'utilisateur, celui symbolisé par le tilde ?
3 - Inspection de contenu
La question 08 est une longue suite de petites manipulation. Suivre les exemples ci-dessous en utilisant les commandes sur votre propre système au fur et à mesure. Bien entendu, les réponses ne seront pas les mêmes selon la solution Linux envisagée.
A - Voir le contenu d'un répertoire
Commençons par voir comment on peut regarder le contenu du répertoire courant, le répertoire sur lequel le terminal pointe.
Commande ls
La commande ls (comme list en anglais) permet de lister le contenu du répertoire courant.
Que peut contenir un répertoire ?
- des fichiers
- d'autres répertoires
Exemple chez alwaysdata :
08-A° Commençons par voir ce que contient le répertoire courant avec la commande ls :
testprofad@ssh1:~$ ls
admin www
On voit qu'il contient deux répertoires nommés admin et www
08-B° On peut rajouter des options courtes à une commande en utilisant un tiret et une lettre représentant l'option.
Commencez bien ici par découvrir le répertoire de travail personnel. Sans cela, l'historique du bash (le fichier .bash_history n'apparaîtra pas).
Ici ls -a veut dire d'afficher tout le contenu du répertoire, même les fichiers cachés. Pourquoi a ? Pour all.
testprofad@ssh1:~$ pwd
/home/testprofad
testprofad@ssh1:~$ ls -a
. .. admin .bash_history www
- Un simple fichier nommé .bash_history
- Un répertoire nommé .
- Un répertoire nommé ..
On observe donc qu'il existe plusieurs choses cachées dans ce répertoire :
86-C° Il existe également des options plus longues qu'une simple lettre à taper.
Dans ce cas, on doit placer deux tirets devant le nom de l'option. A titre d'exemple, voici la version longue de la commande all.
testprofad@ssh1:~$ ls --all
. .. admin .bash_history www
08-D° Comment est-ce que je sais que ce sont des fichiers ou des répertoires ? C'est facile, il y a la couleur.
Sinon, il suffit de lui demander poliment avec l'option -l qui fournit un plus long (-l pour long) descriptif du contenu.
testprofad@ssh1:~$ ls -l
total 0
drwxr-xr-x 5 root root 69 May 31 12:46 admin
drwxr-xr-x 2 testprofad testprofad 24 May 31 12:46 www
- C'est un d s'il s'agit d'un répertoire (directory en anglais)
- C'est un - s'il s'agit d'un simple fichier
Chaque objet présent est décrit par une ligne que nous détaillerons dans l'activité suivante. Aujourd'hui, je ne m'intéresse qu'à la première colonne :
08-E° Pour observer le type des objets cachés, il suffit donc d'utiliser les deux options courtes à la fois en les plaçant derrière le même tiret :
testprofad@ssh1:~$ ls -la
total 4
drwxrwx--- 4 root testprofad 51 May 31 18:29 .
drwxr-x--x 826 root root 0 May 31 22:06 ..
drwxr-xr-x 5 root root 69 May 31 12:46 admin
-rw------- 1 testprofad testprofad 18 May 31 18:29 .bash_history
drwxr-xr-x 2 testprofad testprofad 24 May 31 12:46 www
Pourquoi a ? Simplement pour dire all, tous en anglais.
C'est l'avantage des options courtes. On peut les regrouper pour obtenir un effet global. Par exemple, si on veut la taille mémoire en octets plutôt qu'en blocs, il suffit de rajouter l'option h. Ci-dessous, vous pourrez constater, sur la première ligne, que le contenu affiché occupe 4 ko puisqu'il est noté total 4.0K.
testprofad@ssh1:~$ ls -lah
total 4.0K
drwxrwx--- 4 root testprofad 51 May 31 18:29 .
drwxr-x--x 823 root root 0 May 31 22:27 ..
drwxr-xr-x 5 root root 69 May 31 12:46 admin
-rw------- 1 testprofad testprofad 18 May 31 18:29 .bash_history
drwxr-xr-x 2 testprofad testprofad 24 May 31 12:46 www
Avec Linux (et Unix), les répertoires et fichiers cachés sont simplement ceux dont le nom commence par un point. Comme .bash_history sur l'exemple ci-dessous.
Nous verrons dans la prochaine activité qu'on peut réellement rendre invisible certains répertoires et fichiers pour certains utilisateurs. C'est l'une des puissances de Linux : on contrôle très finement les droits accordés.
Il existe également deux répertoires dont les noms sont un peu bizarre :
- Le répertoire dont le nom est . est un alias pour parler du répertoire actuel
- Le répertoire dont le nom est .. est un alias pour parler du répertoire parent du répertoire actuel
Nous n'allons pas faire le tour de toutes les options de la commande ls. Posons-nous une dernière question.
08-E° Comment obtenir de l'aide si l'accès Internet est en panne ? En utilisant l'option longue --help.
testprofad@ssh1:~$ ls --help
B - Voir le contenu d'un fichier
Comme nous sommes en mode texte, on ne peut pas faire ce que vous avez l'habitude de faire : un double-clic sur le fichier.
Commande cat pour lire un fichier
La commande cat (pour concaténation) permet, notamment, d'afficher le contenu d'un fichier dans la console.
Comme la concaténation des strings : on va ajouter l'entrée fournie à la suite des données contenues dans une sortie (un fichier, un terminal, une connexion réseau...)
Regardons ce que contient le fichier .bash_history ou .ash_history en fonction de votre système.

- cat : la commande utilisée
- .bash_history : l'entrée (ce que nous voulons lire)
- vide sur cet exemple : la sortie qui doit ajouter l'entrée à la suite de ses données. Si on ne place rien, l'entrée va être envoyée par défaut sur le terminal.
testprofad@ssh1:~$ cat .bash_history
ls
ls -a
ls --all
ls -l
ls -la
ls -lah
ls --helpComme vous pouvez le voir, ce fichier .bash_history contient donc l'historique de toutes les commandes qui ont été utilisées sur le terminal. C'est très pratique dans le cadre d'un service en ligne : vous avez installé quelque chose et plusieurs mois plus tard, vous voulez faire pareil sans vous souvenir de la démarche à suivre. Il suffit d'aller voir l'historique.
C - Création rapide d'un fichier
On peut créer très facilement un fichier depuis le terminal en utilisant encore une fois la commande cat. Cette fois, nous allons indiquer une sortie : le fichier de destination !
Commande cat avec > pour créer un fichier
On indique avec le signe >.
Si on ne précise aucune entrée, l'entrée par défaut est alors le terminal : c'est vous qui allez taper le texte.

- cat : la commande utilisée
- vide : par défaut l'entrée est le terminal lui-même
- > : on indique qu'on veut placer ce contenu en mode écrasement ('w' comme write dans Python)
- fichier_magique : la sortie qui doit recevoir l'entrée.
Voici un exemple de commandes où on crée un fichier et on le lit juste après. On notera que si le fichier n'existe pas au préalable, il va être créé. Si le fichier existe déjà, son contenu va être écrasé.
- Pour passer à la ligne, on appuie sur ENTREE.
- Pour sortir du mode "saisie", on appuie simultanément sur CTRL + C .
testprofad@ssh1:~$ cat > fichier_magique
Bonjour.
Je viens de créer mon premier fichier texte
^C <-- Ceci n'est pas à taper : c'est CTRL+C pour sortir
testprofad@ssh1:~$ cat fichier_magique
Bonjour.
Je viens de créer mon premier fichier texte
Attention à bien vous placer dans un répertoire où vous avez les droits : ne restez pas à la racine du serveur !
Votre répertoire personnel ~ semble un bon choix
Le plus beau, c'est qu'on peut rajouter des choses à la suite du fichier plutôt que de l'écraser. En Python, cela correspondrait à l'ouverture d'un fichier en mode 'a' pour append.
Commande cat avec >> pour créer un fichier
Avec ce double signe, on va indiquer qu'on veut rajouter à la fin et pas écraser le contenu.
testprofad@ssh1:~$ cat fichier_magique
Bonjour.
Je viens de créer mon premier fichier texte
testprofad@ssh1:~$ cat >> fichier_magique
Et encore une ligne de plus, rajouté bien après les premières !
^C
testprofad@ssh1:~$ cat fichier_magique
Bonjour.
Je viens de créer mon premier fichier texte
Et encore une ligne de plus, rajouté bien après les premières !
✎ 09° Créer deux fichiers comportant chacun deux lignes. On les nommera fichier1 et fichier2.
Placer dans la copie numérique les codes nécessaires à cette création.
Pour la rédaction du Markdown : il ne s'agit pas de Python mais bien d'un code Bash. Le code sur votre copie markdown devra donc commencer par cela :
#!bash10° A votre avis, que va contenir fichier3 après les commandes suivantes ?
testprofad@ssh1:~$ cat fichier1
Je suis le contenu du fichier 1
Pas grand chose à dire...
testprofad@ssh1:~$ cat fichier2
Moi, je suis le deuxième.
Je n'ai pas pour autant plus de choses à dire.
testprofad@ssh1:~$ cat fichier1 > fichier3
testprofad@ssh1:~$ cat fichier2 >> fichier3
testprofad@ssh1:~$ cat fichier3
??? on obtient quoi ???
...CORRECTION...
La première commande cat fichier1 > fichier3 place le contenu du fichier1 dans un nouveau fichier3 en écrasant l'éventuel contenu précédent puisqu'il n'y a qu'un seul signe supérieur.
Par contre, dans la deuxième concaténation, cat fichier2 >> fichier3, on précise bien qu'on ne veut pas écraser le contenu. On va donc placer le contenu de fichier2 à la suite du contenu déjà présent.
On obtient donc cela :
testprofad@ssh1:~$ cat fichier3
Je suis le contenu du fichier 1
Pas grand chose à dire...
Moi, je suis le deuxième.
Je n'ai pas pour autant plus de choses à dire.
Il est temps de réaliser votre premier programme en C, un langage compilé.
11° Nous allons ici sur plusieurs lignes :
- Créer un fichier hello.c
- Placer les instructions C dans ce fichier à l'aide de cat
- Compiler le programme source C en exécutable en utilisant le compilateur gcc pour produire un fichier binaire exécutable nommé bonjour
- Demander à lister le contenu du répertoire avec ls pour vérifier qu'on a bien créé deux nouveaux fichier (selon les versions, vous devriez voir que l'exécutable n'a pa la même couleur que les autres)
- Demander l'éxécution du fichier binaire exécutable bonjour présent dans le répertoire de travail actuel (représenté par le point .)
~ $ touch hello.c
~ $ cat > hello.c
#include <stdio.h>
int main(void)
{
printf("hello world\n");
return 0;
}
^C <-- Ceci n'est pas à taper : c'est CTRL+C pour sortir
~ $ gcc hello.c -o bonjour
~ $ ls
bonjour hello.c
~ $ ./bonjour
hello world
4 - Se déplacer dans l'arborescence
S'il y a des répertoires, c'est bien qu'on doit pouvoir s'y "rendre". C'est ce que nous allons voir.
Voici l'arborescence visible que nous avions lorsqu'on avait lister le contenu du terminal pointant sur le répertoire personnel chez alwaysdata :
testprofad@ssh1:~$ ls
admin www
Pour rappel, ce répertoire personnel de l'utilisateur, tilde ~, possède une adresse dans la structure globale du serveur :
testprofad@ssh1:~$ pwd
/home/testprofad
Cela veut dire que le terminal aurait pu afficher ceci :
testprofad@ssh1:/home/testprofad$ _
Comme nous passons souvent beaucoup de temps dans ce répertoire spécifique à l'utilisateur, la version de l'alias ~ a été adoptée car c'est plus court que de devoir retaper tout le chemin vers le répertoire de l'utilisateur voulu /home/testprofad.
Si on devait représenter cela sous la forme d'une vraie structure de type répertoires imbriqués les uns dans les autres, ça donnerait donc ceci :
📁 / (la racine (root) de l'ordinateur)
📁 home
📁 testprofad
📁 admin
📄 fichier_magique
📄 fichier1
📄 fichier2
📄 fichier3
📁 www
Nous allons remplir le répertoire www dans la partie finale de cette activité : c'est là qu'il faut placer vos fichiers statiques html, css, javascript et autres fichiers images pour qu'ils soient accessibles depuis un navigateur.
Nous y revenons donc bientôt.
Si vous voulez créer ce répertoire www alors qu'il n'existe pas car vous n'êtes pas connectés chez un hébergeur, il suffit de le créer avec la commande mkdir pour make directory : créer le répertoire.
rv@rv-HP2:~$ mkdir www
D - Changer de répertoire (en fournissant une adresse relative)
Commande cd pour s'enfoncer dans l'arborescence (version adresse relative)
La commande cd (pour change directory) permet de ...changer de répertoire.
Il y a deux façons d'utiliser la commande cd :
- on peut lui fournir une adresse relative au répertoire courant (celui sur lequel pointe le terminal actuellement).
- on peut lui fournir une adresse absolue sur l'ordinateur : c'est une adresse qui commence par /.
Cela sous-entend que le chemin est donné en disant "en partant du répertoire où te trouves actuellement, ..."
Cela sous-entend que le chemin est donné en disant "en partant de la racine du système, ..."
Dans cette partie, nous allons utiliser l'adressage relatif.
Pour "rentrer" dans l'un des répertoires visibles depuis le répertoire courant, il suffit de taper son nom à la suite de cd.
testprofad@ssh1:~$ ls
admin www
testprofad@ssh1:~$ cd admin
testprofad@ssh1:~/admin$ _
On remarque immédiatement que le terminal pointe maintenant sur ~/admin. On peut donc regarder ce qui s'y trouve.
testprofad@ssh1:~/admin$ ls
backup config logs mail tmp
Vous y trouverez donc les sauvegardes de vos projets, les fichiers de configuration, les fichiers de logs qui stockent tout ce qui se passe sur vos sites...
Imaginons que nous voulions voir les connexions effectuées en http sur votre site, il faudra aller dans le répertoire log jusqu'à trouver un fichier texte d'extension .log qui contiendra toutes ses informations. Bien entendu, pour l'instant, votre propre log devrait être vide car personne n'est encore venu sur votre site qui n'existe pas... Par exemple :
testprofad@ssh1:~/admin$ cd logs
testprofad@ssh1:~/admin/logs$ ls
apache http sites
testprofad@ssh1:~/admin/logs$ cd http
testprofad@ssh1:~/admin/logs/http$ ls
2020
testprofad@ssh1:~/admin/logs/http/2020$ cd 2020
testprofad@ssh1:~/admin/logs/http/2020$ ls
http-2020-06-01.log
testprofad@ssh1:~/admin/logs/http/2020$ cat http-2020-06-01.log
testprofad.alwaysdata.net 2a01:cb0c:96c:d400:2123:f77f:5555:f1fab - - [01/Jun/2020:21:01:21 +0200] "GET / HTTP/1.1" 200 82 "-" "Mozil
la/5.0 (X11; Ubuntu; Linux x86_64; rv:76.0) Gecko/20100101 Firefox/76.0"
C'est malin, nous sommes maintenant au plus bas de l'arborescence...
Comment remonter dans le répertoire situé juste au dessus ?
Commande cd .. pour remonter dans l'arborescence
C'est là qu'intervient le fameux répertoire caché qui portait un nom bizarre ... Cet alias désigne simplement le répertoire-parent, celui d'où on vient.
Taper cd .. veut donc dire de remonter dans le répertoire du dessus.
Voici donc un exemple pour voir comment on peut remonter :
testprofad@ssh1:~/admin/logs/http/2020$ cd ..
testprofad@ssh1:~/admin/logs/http$ cd ..
testprofad@ssh1:~/admin/logs$ cd ..
testprofad@ssh1:~/admin$ cd ..
testprofad@ssh1:~$
Nous voici donc revenus dans notre répertoire personnel
- qu'on note ~ mais
- dont l'adresse absolue est en réalité /home/testprofad : notez bien qu'elle commence par un SLASH / comme toute adresse absolue.
📁 / (la racine de l'ordinateur)
📁 home
📁 testprofad (nous sommes ici)
📁 admin
📄 fichier_magique
📄 fichier1
📄 fichier2
📄 fichier3
📁 www
12° Avec une commande, remonter dans le dossier parent de votre répertoire personnel quelque soit votre configuration de connexion (sur votre ordinateur personnel, chez alwaysdata ou sur le terminal virtuel de l'ENT).
Examiner alors son contenu. Il devrait vous paraître vide. Tenter avec un affichage des fichiers cachés.
Quelque chose devrait vous surprendre chez alwaysdata...
...CORRECTION...
Pour remonter, un simple cd .. suffit.
Pour observer le contenu, on utilisera un ls.
Pour observer même les contenus cachés, on utilisera ls -a.
Voici ce qu'on obtient sur mon système
rv@monordi:~$ cd ..
rv@monordi:/home$ ls
rv totolasticot
rv@monordi:/home$ ls -a
. .. rv totolasticot
Rien de particulier donc. Visiblement, il y a deux utilisateurs sur cette machine.
Voici ce qu'on obtient chez alwaysdata
testprofad@ssh1:~$ cd ..
testprofad@ssh1:/home$ ls
ls: cannot open directory '.': Permission denied
testprofad@ssh1:/home$ ls -a
ls: cannot open directory '.': Permission denied
Comme vous le voyez, vous n'avez pas le droit en tant que simple utilisateur de pouvoir visualiser les noms des autres utilisateurs. D'ailleurs, même votre compte n'est pas visualisable. Par contre, vous avez le droit de l'ouvrir... C'est ce qui fait la force en terme de sécurité de Linux et l'une des raisons qui ont propulsé cet OS en tête sur les ordinateurs-serveurs.
13° Regarder le message d'interdiction. Nous avons vu que le code .. signifiait le répertoire-parent. Que semble signifier le simple point unique . ?
Vous pouvez tenter des commandes comme ls . ou cd .
...CORRECTION...
Il s'agit du nom du répertoire courant. Celui dans lequel le terminal pointe.
Actuellement, vous êtes dans /home. Il s'agit donc du nom de répertoire que fournirait la commande pwd.
14° Remonter encore une fois dans le dossier parent à l'aide d'une commande texte. Vous devriez atteindre la racine / du système.
Questions
- Quels sont les éléments présents dans ce répertoire ?
- Lancer une commande de type ls . pour vous convaincre que le point symbolise bien le répertoire courant.
- Peut-on encore remonter plus haut avec un cd .. ou est-on bien à la racine de l'arborescence de la machine ?
Résultats chez alwaysdata
testprofad@ssh1:/home$ cd ..
testprofad@ssh1:/$ ls
alwaysdata boot etc lib lib64 media nfs proc run srv tmp var
bin dev home lib32 libx32 mnt opt root sbin sys usr
testprofad@ssh1:/$ ls -a
. alwaysdata boot etc lib lib64 .local mnt opt root sbin sys usr
.. bin dev home lib32 libx32 media nfs proc run srv tmp var
testprofad@ssh1:/$ ls -al
total 60
drwxr-xr-x 20 root root 4096 May 19 09:29 .
drwxr-xr-x 20 root root 4096 May 19 09:29 ..
drwxr-xr-x 7 root root 4096 May 29 09:12 alwaysdata
lrwxrwxrwx 1 root root 7 Mar 23 14:16 bin -> usr/bin
drwx------ 3 root root 4096 Apr 16 08:41 boot
drwxr-xr-x 13 root root 13160 May 19 09:29 dev
drwxr-xr-x 128 root root 12288 May 29 09:12 etc
drwxr-x--x 979 root root 0 Jun 1 22:57 home
lrwxrwxrwx 1 root root 7 Mar 23 14:16 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Mar 23 14:16 lib32 -> usr/lib32
lrwxrwxrwx 1 root root 9 Mar 23 14:16 lib64 -> usr/lib64
lrwxrwxrwx 1 root root 10 Mar 23 14:16 libx32 -> usr/libx32
drwxr-xr-x 3 root root 4096 Mar 23 14:24 .local
drwxr-xr-x 2 root root 4096 Mar 23 14:16 media
drwxr-xr-x 2 root root 4096 Mar 23 14:16 mnt
drwxr-xr-x 2 root root 0 Jun 1 21:53 nfs
drwxr-xr-x 2 root root 4096 Mar 23 14:16 opt
dr-xr-xr-x 177 root root 0 May 19 09:29 proc
drwx------ 5 root root 4096 Jun 1 12:03 root
drwxr-xr-x 25 root root 900 Jun 1 22:12 run
lrwxrwxrwx 1 root root 8 Mar 23 14:16 sbin -> usr/sbin
drwxr-xr-x 2 root root 4096 Mar 23 14:16 srv
dr-xr-xr-x 12 root root 0 May 19 09:29 sys
drwxrwxrwt 98 root root 2500 Jun 1 22:17 tmp
drwxr-xr-x 15 root root 4096 Apr 16 08:39 usr
drwxr-xr-x 12 root root 4096 Apr 13 2016 var
Nous remarquerons qu'il y a un nouveau type de fichiers.
- Le tiret - codifie les fichiers.
- La lettre d codifie les répertoires (directories).
- La lettre l (L minuscule) codifie les liens (links).
Les liens sont des sortes d'alias.
Je prends le premier qui apparaît :
lrwxrwxrwx 1 root root 7 Mar 23 14:16 bin -> usr/bin
Cela veut dire que
- si je demande ici cd bin,
- l'OS va faire comme si j'avais taper cd usr/bin.
Deux noms mais une même entité.
Comme vous pouvez le voir, il y a une multitude de répertoires différents, chacun ayant son rôle dans la classificiation. Encore faut-il les connaître, ce qui n'est pas au programme de NSI, sauf un ou deux répertoires vraiment importants.
Ceci est à apprendre par coeur :
Rôles de quelques répertoires importants (à connaître)
- / pour la racine du système :
- /home pour la racine des répertoires des utilisateurs
- /home/NOM ou ~ : le répertoire personnel de l'utilisateur NOM
- /root : le répertoire personnel du super-administrateur. Il s'agit de l'administrateur de la machine, celui qui a tous les droits sur celle-ci. On le place dans un répertoire séparé des autres et pas dans /home/root pour des raisons de sécurité.
- . : le répertoire courant sur lequel pointe le terminal
- .. : le répertoire parent du répertoire courant
Ceci est pour votre culture générale, rien à apprendre :
Rôles de quelques répertoires importants (culture générale sur Linux)
- /bin : contient les exécutables binaires de base.
- /sbin : contient un peu la même chose, si ce n'est que ce sont des binaires vraiment fondamentaux.
- /lib, /lib32, /lib64 : contiennent les bibliothèques(des modules dans votre vocabulaire actuel) regroupant des fonctions utilisées par plusieurs des binaires présents dans /bin ou /sbin.
- /usr contient les exécutables des programmes que l'utilisateur installe lui-même.
- /boot contient le noyau Linux, le coeur du système, ainsi que quelques autres fichiers lancés à l'amorçage du système.
- /dev est le répertoire-racine de tous les périphériques comme les clés USB ou autres.
- Avec Windows, on a des noms de disques différents (comme C:, G: ...).
- Avec Linux, tout est regroupé dans la même arborescence commençant par /. Lorsqu'on branche un périphérique, il faut donc le monter (mount en anglais) sur votre arborescence et le début de son adresse absolue sera donc une variante de ce type /dev/ID_PERIPHERIQUE.
Dans le système d'exploitation Windows, ces répertoires correspondent en gros aux fichiers-bibliothèques .dll se trouvant dans C:\windows\system.32 ou C:\windows\SysWOW64.
Son équivalent Windows est un peu C:\program files.
Explications :
Si vous voulez vous renseigner sur les autres répertoires, vous devriez trouver votre bonheur sur le Web.
E - Localiser un programme
Avec une telle arborescence, tout est bien rangé. Mais parfois, on ne sait pas où !
Pour connaître la localisation d'une commande ou d'un programme qui pourrait être présent en plusieurs exemplaires, il existe la commande which.
testprofad@ssh1:/$ which python
/usr/bin/python
testprofad@ssh1:/$ which python3
/usr/bin/python3
testprofad@ssh1:/$ which pwd
/usr/bin/pwd
Cette commande which vous localise le fichier exécuté lorsqu'on lance l'appel à un programme.
Comment savoir si un programme est en réalité une commande interne au Shell de Linux ou une commande externe ?
Pour cela, il existe la commande type qui vous permet de savoir qui est quoi.
- Exemple avec cd qui s'avère être une commande interne au Shell.
- Exemple avec which qui s'avère être une commande externe au Shell.
rv@smonordi:~$ type cd
cd est une primitive du Shell
rv@smonordi:~$ type which
which est /usr/bin/which
✎ 15° Fournir les commandes qui vous permettent de répondre à ces questions :
- Vers quel fichier pointe le système lorsqu'on lui demande d'exécuter ping (commande qui permet de tester la connectivité entre deux machines) ?
- La commande ping est-elle une commande interne au Shell ?
- La commande exit qui permet d'arrêter la liaison avec le terminal est-elle une commande interne au Shell ou externe au noyau ?
F - Changer de répertoire (adresse absolue)
Imaginons que votre terminal pointe sur la racine /. Comment faire pour atteindre rapidement un répertoire sans avoir à faire tous les cd à la suite ?
Commande cd pour s'enfoncer dans l'arborescence (version adresse absolue)
Rappel :
La commande cd (pour change directory) permet de ...changer de répertoire.
Il y a deux façons d'utiliser la commande cd :
- on peut lui fournir une adresse relative au répertoire courant ("en partant du répertoire où te trouves actuellement, ...")
- on peut lui fournir une adresse absolue sur l'ordinateur : c'est une adresse qui commence par /. Cela sous-entend que le chemin est donné en disant "en partant de la racine du système, ..."
Dans cette partie, nous allons utiliser l'adressage absolu.
Quelques exemples d'utilisation :
- Retour à la racine quelque soit le répertoire courant
- Déplacement en une étape dans le répertoire www :
- Déplacement direct dans le répertoire /sbin :
- Déplacement dans le répertoire /home/testprofad/admin en utilisant le tilde :
Le terminal pointe initialement sur le répertoire personnel. On remarquera que le système note ~ plutôt que /home/testprofad.
testprofad@ssh1:~$ cd /
testprofad@ssh1:/$ _
On voit bien qu'on passe de ~ à /.
testprofad@ssh1:/$ cd /home/testprofad/www
testprofad@ssh1:~/www$ _
testprofad@ssh1:~/www$ cd /sbin
testprofad@ssh1:/sbin$ _
testprofad@ssh1:/sbin$ cd ~/admin
testprofad@ssh1:~/admin$ _
16° Déplacer le terminal pour qu'il pointe dans le répertoire /usr/bin.
...CORRECTION...
On fournit l'adresse absolue, il suffit de taper cd /usr/bin.
G - Lister le contenu d'un répertoire sans y aller
Pour voir le contenu d'un répertoire, on peut se déplacer dans ce répertoire et utiliser une commande ls.
Mais on peut faire mieux : on peut utiliser une commande ls en fournissant comme argument l'adresse du répertoire à étudier.
Un exemple en étant au départ du dossier personnel (tilde) qui contient deux autres répertoires.
testprofad@ssh1:~$ ls
admin www
La commande suivante est possible en adresse relative car admin est bien un sous-répertoire du répertoire courant. On observe le contenu du répertoire admin tout en restant dans le répertoire ~ :
testprofad@ssh1:~$ ls admin
backup config logs mail tmp
Idem avec le répertoire www qui est bien un répertoire contenu dans le répertoire courant.
testprofad@ssh1:~$ ls www
index.html <-- nous allons créer ce fichier ensemble, juste après
Par contre, si on demande à visualiser usr/bin, cela ne fonctionne pas car on fournit une adresse relative au répertoire courant : le système va chercher s'il existe un répertoire usr dans ~. Et la réponse est non.
testprofad@ssh1:~$ ls usr/bin
ls: cannot access 'usr/bin': No such file or directory
Pour que ça fonctione, il suffit de fournir une adresse absolue précisant qu'on cherche à partir de la racine, à partir de /. Ne lancez pas cette dernière commande : il y a beaucoup beaucoup de fichiers à cet endroit !
testprofad@ssh1:~$ ls /usr/bin
'['
gv2gxl ppmdim2to3 gvcolor
ppmdist 2to32 gvgen
ppmdither 2to32.4 gvmap
...
La commande cat admet également l'utilisation d'adresse absolue, pratique pour afficher le contenu d'un fichier sans être dans le bon répertoire.
17° Je vous fournis l'arborescence théorique suivante. Le répertoire courant est testprofad, surligné et cela apparaît bien devant l'invite de commande $.
📁 / (racine ordinateur)
📁 bin
📄 fichierA
📁 home
📁 testprofad
📁 admin
📄 fichierB
📁 www
📁 repC
Questions
- Comment afficher le contenu du fichier fichierA sans bouger et avec une adresse absolue ?
- Comment lister le contenu de repC sans bouger et avec une adresse absolue ?
- Comment afficher le contenu du fichier fichierA sans bouger et avec une adresse relative ? On rappelle que
..permet de trouver le dossier parent. - Comment lister le contenu de repC sans bouger et avec une adresse relative ?
...CORRECTION...
- L'adresse absolue est une adresse qui part de la racine (
/). C'est donc simple : il suffit d'écrirecat /bin/fichierA. - L'adresse absolue est une adresse qui part de la racine (
/). Il suffit d'écrirels /home/testprofad/www/repC. - L'adresse relative demande de partir du répertoire courant, dans notre cas
/home/testprofadqu'on symbolise par~. Pour atteindre le fichier fichierA, il faut donc remonter dans le dossier parent (home), remonter encore dans le dossier parent (/, la racine). Une fois à la racine, il faut redescendre dans l'arborescence et aller dans bin pour y trouver, enfin, le fichier voulu. - L'adresse relative demande de partir du répertoire courant, dans notre cas
/home/testprofadqu'on symbolise par~. Pour atteindre le répertoire repC depuis~, c'est facile :ls www/repC.
Du coup, ça donne cat ../../bin/fichierA.
✎ 18° Je vous fournis l'arborescence théorique suivante. Le répertoire courant est www, surligné et cela apparaît bien devant l'invite de commande $.
📁 / (racine ordinateur)
📁 bin
📁 fichierA
📁 home
📁 testprofad
📁 admin
📄 fichierB
📁 www
📁 repC
Questions
- Comment afficher le contenu du fichier fichierA sans bouger et avec une adresse absolue ?
- Comment afficher le contenu du fichier fichierA sans bouger et avec une adresse relative ? On rappelle que
..permet de trouver le dossier parent.
Récapitulatif des notions et commandes
Les notions abordées :
| Notion | Explication |
|---|---|
Racine / |
La racine est le point de départ de l'arborescence. |
| Adresse absolue | Il s'agit d'une adresse dont le point de départ est la racine. L'adresse commence donc par / .
|
| Utilisateur root | Le super-administrateur de la machine. Il a tous les droits sur la machine. Son répertoire personnel est situé à l'adresse absolue /root.
|
| Répertoire personnel d'un utilisateur | Il s'agit du répertoire qui appartient à un utilisateur. Il est situé à l'adresse absolue /home/NOM_UTILISATEUR. Il peut être adressé plus facilement en utilisant le raccourci Tilde ~ .
|
| Adresse relative | Une adresse qui prend comme point de départ le répertoire courant, le répertoire sur lequel pointe actuellement le terminal. |
Répertoire parent .. |
Il s'agit du répertoire "contenant" le répertoire courant. Par définition, seule la racine ne possède pas de parent. |
Les commandes à connaître :
| Commande | Explication |
|---|---|
| ls | Liste le contenu du répertoire dont l'adresse (relative ou absolue) est fournie juste après.ls www : liste le contenu d'un répertoire www contenu dans le répertoire courant.ls /home/utilisateur/www : idem mais avec une adresse absolue.Si on ne fournit rien( ls), il s'agira du répertoire courant.Quelques options : ls -a pour afficher les objets cachés (ceux qui commencent par un point)ls -l pour afficher des informations plus longues
|
| cd | Change directory : permet de changer de repertoire.cd ~ permet d'atteindre son propre répertoire.cd / permet d'atteindre la racine.cd .. permet de remonter d'un cran dans l'arborescence. |
| cat | Permet de concaténer une entrée vers une sortie. La forme générale pour écraser l'ancien contenu est cat entree > sortieLa forme générale pour rajouter du contenu est cat entree >> sortieSi on omet l'entrée, il s'agit par défaut du terminal. Si on omet la sortie, il s'agit par défaut du terminal. |
Les commandes qui ne sont pas à connaître mais que nous avons vu :
| Commande | Explication |
|---|---|
| which | Permet d'obtenir l'adresse absolue du fichier qui est reconnu comme étant l'exécutable d'une commande. Exemple which python3 |
| type | Permet d'obtenir le type d'une commande (interne ou externe au Shell-Noyau) |
| whoami | Permet de récupérer le nom de l'utilisateur du terminal |
| pwd | Print working directory, permet de récupérer le répertoire sur lequel pointe actuellement le terminal. |
5 - Mise en production d'un site
Nous avons maintenant tous les outils pour parvenir à publier votre première page HTML en production.
Si vous n'avez pas créé de compte chez alwaysdata, vous ne pourrez pas placer votre page en ligne bien entendu. Vous pourrez par contre tester l'utilisation des commandes.
19° Se connecter à votre compte alwaysdata via ssh, comme expliqué sur cette fiche
ACCESS SSH VIA LE WEB CHEZ ALWAYSDATA
Le terminal pointe initialement sur votre dossier personnel (~).
📁 / (racine ordinateur)
📁 home
📁 votrecompte
📁 admin
📁 www
Aller dans le répertoire www en utilisant la commande suivante :
votrecompte@ssh1:~$ cd www
votrecompte@ssh1:~/www$ _
Votre terminal pointe maintenant sur le dossier www qui est par défaut le dossier devant contenir vos fichiers accessibles par Internet.
📁 / (racine ordinateur)
📁 home
📁 votrecompte
📁 admin
📁 www
20° Créer un petit fichier HTML en suivant l'exemple des commandes suivantes :
votrecompte@ssh1:~/www$ cat > index.html
<!DOCTYPE html>
<html>
<p>Bonjour ! Voici la page d'accueil</p>
</html>
^C
21° Créer un deuxième petit fichier HTML en suivant l'exemple des commandes suivantes :
votrecompte@ssh1:~/www$ cat > nouveau.html
<!DOCTYPE html>
<html>
<p style="color: red;">Une nouvelle page</p>
</html>
^C
votrecompte@ssh1:~/www$ exit
Maintenant, vous devriez avoir ceci :
📁 / (racine ordinateur)
📁 home
📁 votrecompte
📁 admin
📁 www
📄 index.html
📄 nouveau.html
Il vous reste à activer l'accès à votre site en vous connectant à votre compte chez Alwaysdata.
22° Se connecter sur https://www.alwaysdata.com/fr/ pour atteindre le menu suivant :

Appuyer sur l'icône Engrenage pour aller dans la configuration de votre site par défaut (vous pouvez en créer d'autres en utilisant AJOUTER UN SITE si vous voulez).
Le site créé pour la démonstration est accessible sous le nom testprofad.alwaysdata.net).
Sur l'image ci-dessous, je tente de rendre le site accessible également via le sous-domaine www par exemple. En tapant le nouveau nom : www.testprofad.alwaysdata.net.
Ca ne marchera pas car le nom de domaine alwaysdata.net ne m'appartient pas.

Par contre, si vous achetez un nom de domaine un jour (comme informatique.fr), vous pourrez rajouter ce que vous voulez à gauche (comme www.informatique.fr).
Avec l'adresse fournie par l'hébergeur, vous pouvez juste rajouter un complément d'accès via l'URL en le plaçant à droite. Par exemple : testprofad.alwaysdata.net/rajout
Il reste à configurer le type de site, en allant un peu plus bas.

Comme vous pouvez le voir, on peut choisir le type de site créé. Pour ajourd'hui, choisir un site statique : de simples pages HTML, CSS et JS à distribuer au client.
Les autres possibilités permettent de créer un site dynamique (créant notamment les pages à la volée).
On remarquera également qu'on peut choisir le répertoire qui devra contenir les pages à distribuer. Par défaut, il s'agit de /www. La racine / n'est pas ici la racine du serveur distant mais la racine de votre compte (le tilde ~). Laisser le dossier par défaut, c'est clair au moins.
Appuyer sur Valider pour que vos modifications soient prises en compte.
23° Tapez les adresses voulues dans votre barre d'adresse. Tester le site de test ou vos propres pages. La première devra se nommer index.html : c'est le nom par défaut de la page d'accueil.
Quelques exemples :
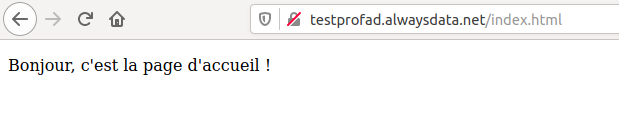
- Page d'accueil : http://testprofad.alwaysdata.net/index.html
- Page d'accueil : http://testprofad.alwaysdata.net/
- Une deuxième page : http://testprofad.alwaysdata.net/nouvelle.html
Comme vous le voyez, les pages sont stockées sur le serveur dans un répertoire bien précis (/home/testprofad/www mais ça n'apparaît absolument pas dans les URL que tapent l'utilisateur.
Les exemples visuels des requêtes HTTP :




✎ 24° Envoyez moi quelques adresses de votre petit bout de site Internet si vous avez bien voulu vous créer un compte chez un hébergeur.
- les programmes et
- le matériel technologique physique.
- de permettre la communication entre programmes et périphériques sans que le programme n'ai besoin de connaitre exactement les détails du matériel sur lequel il agit.
- de garantir l'intégrité du système en vérifiant qu'un programme ne puisse pas provoquer d'erreur fatale lorsqu'il veut réaliser quelque chose.
- de gérer les ressources communes disponibles sur l'ordinateur entre les différents programmes : mémoires, écran...
- c'est le système d'exploitation qui va décider quels sont les 4 programmes qui accédent à l'un des processeurs.
- c'est le système d'exploitation qui répartit la RAM entre les différents programmes actifs.
- le système d'exploitation reçoit la demande
- le système d'exploitation vérifie la validité de la demande
- le système d'exploitation utilise les pilotes qui vont bien pour réaliser l'instruction demandée par le programme.
- Avec Windows, on nomme cela une invite de commande
- Avec Linux, on nomme cela un terminal
- on désire commander un ordinateur à distance.
- on désire configurer plusieurs ordinateurs avec un programme plutôt que de cliquer un nombre de fois hallucinant sur une interface graphique.
- ...
6 - Rôles du système d'exploitation
Rôles du système d'exploitation
Le système d'exploitation fait office d'interface (de tampon) entre :
Les systèmes d'exploitation ont pour rôles :
Grace au système d'exploitation, un programme commande tous les écrans de la même façon par exemple. Le programme n'a pas besoin de connaître la marque, le modèle et la commande exacte permettant de faire telle ou telle action. Le programme envoie sa demande à l'OS et l'OS réalise la traduction pour que l'écran comprenne ce que le programme veut de lui. Ces programme qui gèrent la traduction se nomment les pilotes.
Le programme fait une demande. L'OS va alors d'abord vérifier que cette action est bien autorisée et ne va pas nuire à une autre partie du système. L'OS reçoit donc les demandes des programmes mais réalise un filtre avant de traduire réellement la demande, ou de ne pas la transmettre. C'est bien l'OS qui autorise ou pas un programme d'agir de telle ou telle manière.
Plusieurs programmes mais un seul processeur et une seule RAM. C'est l'OS qui répartit les ressources et donne accès à tour de rôle à tout le monde.
Par exemple, un CPU 4 coeurs ne devrait donc faire tourner que 4 programmes en même temps puisque c'est un peu comme s'il y avait 4 processeur.

Quel est le rôle de l'OS là dedans ?
Et comment fait le système d'exploitation pour permettre aux programmes d'interagir avec le matériel ?
Appels systèmes : les fonctions d'interface de l'OS
Les programmes utilisent des appels systèmes, des commandes que l'OS reçoit, connait, analyse et exécute s'il le décide : les programmes font des demandes d'actions mais le système d'exploitation est le seul à interagir directement avec les périphériques, les processeurs, la carte-réseau ou la RAM.

Les appels systèmes sont donc des fonctions d'interface accessibles aux programmes, permettant de demander poliment au système d'exploitation de faire quelque chose pour eux.
Exemple 1 : vous lancer un script Python contenant un print(). L'interpréteur Python va lire votre demande (print()) et va la traduire en un ensemble d'appels système qu'il va envoyer au système d'exploitation : open, write.... Le système d'exploitation va alors recevoir ces appels et va à son tour le traduire pour que l'écran physique comprenne la demande et l'exécute.
Exemple 2 : Imaginons que vous vouliez supprimer un fichier présent sur votre clé USB. Que vous le fassiez via l'interface graphique, via un programme Python ou en utilisant la console, l'OS va recevoir un appel système delete :

Dans les trois cas, le système d'exploitation va réagir de la même manière :
Les programmes n'ont pas besoin de connaître quoi que ce soit sur la clé USB, à part son identifiant : c'est l'OS qui se charge de tout.
Les systèmes d'exploitation disposent donc d'un ensemble d'appels systèmes basiques permettant de gérer correctement les ressources communes : les périphériques, le CPU, la mémoire...
OS c'est pas un métier, c'est une vocation. Jamais un instant de calme. Il s'agit du chef d'orchestre de votre ordinateur. Une application complexe composée de plusieurs autres programmes et en interaction avec tous les autres programmes tournant sur la machine.
Les premiers systèmes d'exploitation ne comportaient pas d'interface graphique. On passait donc nécessairement par une console d'interfaçage purement textuelle qui recevait nos instructions et les transforme en appels systèmes à destination du système d'exploitation. Le nom de la console varie avec le nom du système d'exploitation :
Aujourd'hui, on utilise encore beaucoup ces commandes lorsque
7 - Commandes Windows
Pour que vous puissiez voir un peu comment marche votre console si vous êtes chez Microsoft avec Windows, voilà quelques commandes équivalentes. Sur MacOS, vous devriez pouvoir utiliser la majorité des commandes présentées pour Linux, puisque MacOS est basé également sur UNIX.
Voici un tableau d'équivalence approximative. Toutes les commandes Linux ne sont pas disponibles avec Windows.
| Linux | Windows |
|---|---|
Racine / |
Racine C:\ . |
cd (change directory) |
cd aussi. |
ls (list) |
dir |
cat (concaténation) |
edit ou editln pour le créer, type pour lire le contenu d'un fichier texte. |
8 - FAQ
C'est quoi le total avec ls -l ?
Remarque totalement optionnel.
La première ligne, total, fournit le nombre de blocs-mémoires utilisés par le contenu visible du répertoire.
Chaque bloc-mémoire représente un nombre précis d'octets en fonction du système : 512, 1024 ou plus...
Ca marche comment le transfert FTP ?
Réponse courte : UTILISER FTP FILEZILLA et ALWAYSDATA
Il n'y a pas de raccourci clavir pour ouvrir un terminal ?
Le raccourci clavier est CTRL+ALT+T .
Si vous avez une version Linux-Debian, vous pouvez accéder à l'un des terminaux avec par exemple CTRL+ALT+F3 , CTRL+ALT+F4 ... Ca fonctionne bien entendu aussi sur Ubuntu puisqu'il est basé sur la Debian.
Pour retrouver votre fenêtre graphique, il faudra surement faire CTRL+ALT+F2 ou CTRL+ALT+F1 . Il s'agit de retrouver le terminal depuis lequel l'interface graphique a été lancée.
Activité publiée le 01 06 2020
Dernière modification : 09 05 2025
Auteur : ows. h.