Vous allez voir aujourd'hui que l'informatique théorique a des liens étroits avec la logique mathématique.
Vous êtes ici dans la partie "programmation avec Python". Que vient donc faire la logique mathématique dans cette partie ?
Nous allons parler aujourd'hui de ce qu'un algorithme (et donc un programme réel) peut faire ... ou pas. L'une des premières choses à faire lorsqu'on vous demande de réaliser quelque chose est de s'assurer que la tâche demandée est réalisable à l'aide d'un algorithme.
Mais, ca veut dire quoi "réalisable algorithmiquement" ?
Comment peut-on savoir qu'on ne pourra pas trouver de solution avant d'avoir cherché ?
Après tout, peut-être qu'en cherchant plus longtemps, on finirait par trouver, non ?
A - Algorithme : une notion vague avant le 19e siècle
La notion d'algorithme est utilisée depuis très longtemps. Nous avons vu en 1er, que dès l'Antiquité, certains résultats et calculs pouvaient être déterminés en utilisant ces fameux algorithmes.
Pourtant la définition d'un algorithme est restée pendant très longtemps assez vague : une sorte de recette de cuisine pour certains, un ensemble d'instructions élémentaires pour d'autres...
Jusqu'au début du siècle dernier, bien peu de personnes soupçonnaient que l'on pourrait réellement préciser la notion d'algorithme.
B - Apparition de la logique mathématique
Avant de voir ce travail de formalisation de l'algorithme aboutir, il a fallu que la logique mathématique soit elle même formalisée à la fin du 19e siècle.
La logique mathématique est la branche des mathématiques qui s'intéresse aux mathématiques en tant que langage : la façon dont on formalise un énoncé mais aussi la façon dont on construit une démonstration.
Ce travail est le résultat d'un ensemble de recherches issues de plusieurs directions différentes :
en 1847, George Boole publie les bases de l'algèbre qu'on nomme maintenant l'algèbre booléen (a ET b revenant à a.b, a OU b revenant à a+b comme vu en première approche en 1er...)
en 1847, Auguste De Morgan publie ses propres travaux (dont les fameuses formules a+b = a . b..., rapidement vues en 1er également...)
leurs travaux vont servir de base à ce qui va devenir une nouvelle branche des mathématiques : la logique mathématique. Gottlob Frege va clarifier et formaliser le raisonnement logique en 1879; notamment la logique des relations.
les mathématiciens Gottlob Frege, Bertrand Arthur William Russell, Giuseppe Peano et David Hilbert vont travailler à donner une fondation axiomatique des mathématiques.
Chaque branche des mathématiques possède son propre sujet d'étude. Ainsi l'arithmétique peut être vue comme la théorie des nombres par exemple. On doit la définir par un ensemble précis de propriétés qu'on décide comme étant des vérités. On les nomme des axiomes. Voici les trois premiers axiomes de l'arithmétique (exprimés en français plutôt que sous forme d'équations) :
L'élément appelé zéro et noté 0 est un entier naturel.
Tout entier naturel n a un unique successeur, noté s(n) ou Sn qui est un entier naturel.
Aucun entier naturel n'a 0 pour successeur.
...
en 1929, Kurt Gödel prouve le théorème de complétude : toute proposition P d'une théorie mathématique axiomatique qui est VRAIE dans tous ces modèles est démontrable dans le cadre de cette théorie. On pense alors qu'on va pouvoir un jour trouver la théorie mathématique ultime, celle qui permettra de tout démontrer !
en 1931, ce même Kurt Gödel va publier ses deux théorèmes d'incomplétude montrant que pour toute théorie mathématique comportant l'arithmétique de base :
une telle théorie complète incluant l'arithmétique(c'est à dire qui permet de démontrer que toute proposition P exprimable dans la théorie est soit VRAIE, soit FAUSSE) est nécessairement une théorie incohérente : on pourrait rouver qu'une proposition est VRAIE en utilisant une démonstration et FAUSSE en utilisant une autre démonstration !
Pour être utilisable, une théorie incluant l'arithmétique doit donc être incomplète : il doit exister certaines propositions P indécidables : des formules qu'on ne peut ni démontrer (prouver que P est toujours VRAIE), ni réfuter (prouver que P est toujours FAUSSE) dans tous les modèles de cette théorie.
Pourquoi ? Simplement car une théorie est un ensemble d'axiomes.Lorsqu'une proposition P est prouvable en utilisant ces axiomes de la théorie, elle est donc VRAIE dans tous les modèles basés sur cette théorie.
Et c'est le problème avec la théorie de l'arithmétique : ses axiomes caractérisent l'ensemble des entiers naturels mais également des ensembles d'entiers "exotiques", légèrement différents. Et certains propositions semblant vraies sur les entiers naturels (lorsqu'on utilise cette formule, les tests montrent toujours que c'est vrai) ne sont pas vérifiées avec ces autres entiers "exotiques".
Lorsqu'une proposition P sur les entiers semble fonctionner mais qu'on ne parvient pas à la démontrer, il y 3 possibilités :
On peut finir par trouver la démonstration et on montrera alors qu'elle est définitivement valide.
On peut finir par trouver un contre-exemple dans les entiers : la proposition est définitivement réfutée, c'est juste que les exemples la mettant en défaut ne sont pas si courants que cela.
Elle est indécidable pour cette théorie. Par exemple, elle est "vraie" sur nos entiers naturels mais pas sur tous les modèles exotiques d'entiers : on ne parviendra donc jamais à la démontrer ET on ne trouvera jamais de contre-exemples la mettant en défaut... Une proposition indécidable est donc une proposition d'une théorie dont la vérité est variable en fonction du modèle sur lequel on l'applique. On ne pourra alors pas "généraliser" de démonstration ou de réfutation pour aboutir à une conclusion applicable à tous les modèles pour cette propriété.
Moralité, si une formule semble toujours vraie mais qu'on ne parvient pas à la démonstrer, on ne peut pas savoir si on est dans le cas 1 ou le cas 2 ou le cas 3.
Idem avec une formule qui semble toujours fausse mais dont on ne parvient pas à trouver de réfutation définitive.
Gödel démontre aussi dans son deuxième théorème d'incomplétude que déterminer si une théorie est incohérente est justement une proposition indécidable. Il n'existe donc pas de prédicat permettant de savoir si une théorie est incohérente ou pas dans le cadre de la théorie elle-même. C'est le fait de tomber, un jour, par hasard, sur une incohérence qui va lui donner un statut de théorie incohérente...
Tout ceci va permettre de redonner des bases stables et solides aux mathématiques : les mathématiciens ont pu se mettre d'accord sur un nombre limité d'axiomes pour chaque théorie.
Assez pour obtenir une théorie solide mais... incomplète. Les axiomes de l'arithmétique caractèrisent et s'appliquent à l'ensemble des entiers naturels, mais également à d'autres ensembles d'entiers exotiques.
Pas trop pour espérer ne pas travailler sur une théorie incohérente.
Seuls les non mathématiciens pensent que c'est la fin des mathématiques. Depuis cette époque, on n'a jamais trouvé d'exemples montrant l'incohérence de l'arithmétique. Et si il s'avérait que ce soit le cas, il suffirait sans doute de modifier quelques axiomes. C'est pour cela que, dans toute démonstration, on énonce clairement quels théorèmes et axiomes sont utilisés.
Après ce petit détour par les théories mathématiques, revenons à l'informatique.
D'abord, notez bien qu'on retrouve une notion que vous connaissez très bien : TESTER un programme ne revient pas à PROUVER LA CORRECTION de votre programme. Un jeu de tests d'un milliard de cas ne remplace pas une preuve de correction (sauf si vous parvenez alors à tester tous les cas possibles bien entendu : c'est alors une démonstration par cas).
C - La définition de l'algorithme et de la calculabilité
Le travail de formalisation de l'algorithme fut effectué en plusieurs étapes de 1931 à 1936 notamment par :
Image par : Konrad Jacobs, Erlangen, Copyright is MFO, CC BY-SA 2.0 DE <https://creativecommons.org/licenses/by-sa/2.0/de/deed.en>, via Wikimedia Commons"
Alan Turing
Image du domaine public
Kurt Godel.
Image du domaine public
De façon à caractériser l'arithmétique et le calcul, ils vont chercher à trouver ce qu'est le calcul. Plusieurs moyens de formaliser (définir mathématiquement) ce qu'est une fonction calculable vont être trouvés :
Les fonctions récursives sont utilisées dans le cadre théorique de modèle de calcul par Kurt Godel, notamment dans ses théorèmes d'incomplétude. Mais, sont-elles vraiment l'outil le plus adapté pour le calcul ? Calculent-elles tout ce qui est calculable ?
Le lambda-calcul (ou λ-calcul) est un système formel inventé par Alonzo Church. Il est basé fondamentalement sur le concept de fonction et formalise assez simplement la notion de calcul.
Sans rentrer dans les détails, voici la façon dont on écrit la fonction successeur en λ-calcul :
λx.x+1 : cette codification veut dire que notre fonction attend de recevoir un argument x et qu'elle renvoie alors x+1. C'est bien la fonction successeur.
La machine de Turing est un modèle abstrait du fonctionnement des appareils mécaniques de calcul créé par Alan Turing dans le but de définir précisément ce qu'est un algorithme et ce que représente la complexité d'un algorithme. Il ne s'agit pas d'une machine réelle mais plutôt d'une définition la plus épurée possible de ce que doit faire une machine qui calcule. Sa simplicité permet en réalité de réalité de réaliser des démonstrations sur ce qui est calculable, ou pas.
Stephen Kleene va tenter de montrer l'équivalence entre les fonctions récursives, le λ-calcul, et la machine de Turing. Cela va aboutir à la thèse de Church-Turing qui énonce (sans le démontrer) que ces 3 méthodes de calcul "mécanique" (machine de Turing, λ-calcul et récursivité) sont équivalentes et peuvent toutes calculer les mêmes fonctions. Ces trois techniques ont donc la même "puissance prédictive". Si l'une d'entre elles parvient à réaliser un calcul, on pense que les autres le peuvent aussi.
Tous les tests jusqu'à présent ont montré cette équivalence. Mais tester, n'est pas prouver.
1.1 Calculabilité
Calculabilité "mécanique"
La calculabilité est définie comme tout traitement
issu d'un système physique de calculs (qu'on assimilera à une machine de Turing pour préciser la notion)
répondant après un nombre d'étapes fini (et donc un temps fini)
en utilisant un jeu fini d'instructions
Le point 1 contenant le terme "système physique de calculs" posait problème dans le cadre d'une définition mathématique. C'est en partie pour cela que Turing a développé sa fameuse machine : de cette façon, il est parvenu à formaliser mathématiquement ce qu'est un système physique de calculs. On a déterminé le caractère universel de cette machine : elle peut émuler le comportement de n'importe quel autre système de calculs connus et est facilement représentable théoriquement.
Vue d'artiste de la machine de Turing (domaine public, publié sur Wikipedia)
Thèse de Church
La thèse de Church élargit la définition au λ-calcul, à la récursivité et à tout langage de programmation Turing-complet (comme Python) : si Python peut effectuer un calcul, une machine de Turing également. Et inversement.
Calculable et Non Calculable
Cette définition de fonction calculable engendre donc naturellement la notion de fonction non calculable.
Sans entrer dans les détails de la démonstration, disons qu'il n'existe qu'un nombre limité d'algorithmes qui sont les combinaisons obtenues en prenant X mots dans l'alphabet du langage considéré contenant Y symboles. Avec un langage comportant 1000 symboles et un programme contenant 400 de ces symboles, on a 1000400 programmes différents (dont la plupart ne fonctionneront pas !). Un nombre fini, très grand, mais pas infini.
Or, les fonctions (même en ne considérant que les fonctions ayant un argument entier naturel et renvoyant un entier naturel) sont plus nombreuses ! Par conséquent, on ne pourra jamais calculer l'infinité des problèmes possibles à l'aide d'un programme de taille finie. Or, un programme de taille infinie ne peut pas répondre puisqu'il faudrait un temps infini pour exécuter son infinité d'instructions.
Une fonction calculable est une fonction pour laquelle on aura une réponse au bout d'un temps fini, quels que soient les arguments valides envoyés(c'est à dire respectant types et préconditions).
ENTREES VALIDES ➔ FONCTION CALCULABLE ➔ Fournit toujours une réponse
Une fonction non calculable est une fonction pour laquelle on aura parfois une réponse au bout d'un temps fini pour certains paramètres, et parfois aucune réponse car le calcul va provoquer une boucle infinie même avec des paramètres respectant les préconditions.
ENTREES VALIDES ➔ FONCTION NON CALCULABLE ➔ Peut founir une réponse OU boucler à l'infini
Bien entendu, impossible de prévoir à l'avance quelq sont les entrées qui génèrent une boucle infini.
Lorsque le programme ne fournit pas sa réponse et que vous trouvez le temps long, vous devez prendre une décision :
On le stoppe ? Mais il va peut-être répondre un jour !
On le laisse travailler ? Mais il est peut-être déjà en train de boucler à l'infini !
Bref, elles sont non calculables car elles ne rendent pas systématiquement la main. On ne peut pas les utiliser sans danger dans un système car elles peuvent, parfois, créer une boucle infinie.
To compute, computability, computer
On notera qu'en anglais la calculabilité se nomme computability ; on comprend bien le lien avec "computer", là où le mot "ordinateur" ne montre pas aussi bien le lien évident entre les deux notions.
1.2 Définition d'Algorithme
Définition plus formelle d'Algorithme
Un algorithme peut maintenant être défini comme un ensemble d'instructions réalisables par un système physique de calcul et répondant donc aux critères de la calculabilité.
Algorithme et calculabilité sont donc intimement liés.
Python est Turing-compatible
Comme vous ne connaissez pas la machine de Turing mais que Python est Turing-compatible, nous pouvons en déduire que tout ce qui est calculable avec Python est calculable par un algorithme. Et inversement.
Vous saviez déjà qu'un algorithme est assimilable à une fonction : on lui donne des ENTREES sur lesquelles il travaille et pour lesquelles il fournit une SORTIE. Vous devriez maintenant comprendre qu'il ne s'agit pas juste d'une similitude mais d'une réelle équivalence.
ENTREES ➔ ALGORITHME ➔ SORTIE
ENTREES ➔ FONCTION ➔ SORTIE
Cette remarque vise à rappeler ce que vous avez déjà vu de nombreuses fois : un algorithme doit résoudre une classe de problèmes et pas uniquement une instance particulière d'un problème. Si votre "algorithme" ne sait gérer qu'un énoncé unique aux valeurs fixées et pas tout un ensemble d'énoncés, il ne s'agit pas vraiment d'un algorithme.
1.3 Théorie de la calculabilité
Lors de vos études supérieures, vous verrez peut-être que cette théorie ne vise pas juste à distinguer les fonctions calculables et les fonctions non calculables.
Elle vise aussi à les classifier, à savoir par exemple s'il existe des fonctions non calculables encore plus non calculables que d'autres !
Le lien avec la calculabilité est immédiat : un problème est décidable s'il existe une fonction calculable qui décide par Oui / Non de la réponse à la question posée par le problème.
Définition générale : un problème de décision est décidable s'il existe une machine de Turing qui termine et répond Vrai ou Faux sur n'importe quelle instance du problème.
Définition NSI : un problème de décision est décidable s'il existe une fonction-prédicat Python qui termine et répond True ou False sur n'importe quelle instance du problème.
Exemple
Le problème suivant est un problème décidable algorithmiquement "Un entier naturel x est-il un nombre premier ?". De façon naïve, il suffit de tester sa division euclidienne par tous les entiers compris entre 2 et lui-même. Si le reste vaut 0 à un moment, c'est qu'il ne s'agit pas d'un nombre entier.
On peut donc créer une telle fonction :
1
defest_premier(n:int)->bool:
Voici la résolution naïve (voir l'activité sur les corrections de bugs parlant un peu de RSA pour des versions plus efficaces) :
Décidable ne veut pas dire FACILE. Un problème décidable peut être FACILE ou DIFFICILE. Dans ce dernier cas, on pourra alors le résoudre en théorie mais pas concrètement si les données seront importantes.
Même un problème décidable peut donc s'avérer impossible à résoudre en pratique.
2.2 Indécidabilié algorithmique
Tous les problèmes ne sont pas décidables.
Définition
Les problèmes indécidables sont ceux pour lesquelles on ne peut pas créer de programmes capables de répondre systématiquement OUI ou NON pour chacune des instances possibles du problème.
Certains problèmes indécidables sont un peu plus "faciles" que les autres mais ils n'en restent pas moins indécidables :
Ceux qui terminent toujours lorsque la réponse est OUI et, sinon, peuvent soit répondre NON, soit BOUCLER.
Ceux qui terminent toujours lorsque la réponse est NON et, sinon, peuvent soit répondre OUI, soit BOUCLER.
Ils restent indécidables car si la réponse n'arrivent pas, vous ne savez pas s'ils bouclent ou s'ils sont dans la catégorie qu'ils savent gérer et vont finir par répondre. On dit parfois qu'ils sont semi-décidables.
Les problèmes indécidables plus "complexes" ne permettent pas de gérer systématiquement ni le OUI, ni le NON.
Gérer un problème indécidable ?
Dire qu'un problème est indécidable algorithmiquement ne veut pas dire qu'on ne peut pas trouver de solution PARFOIS. Il existe des instances particulières du problème pour lesquels on peut répondre. C'est le travail de l'informaticien de trouver justement quels sont les sous-problèmes accessibles.
Mais de façon générale, cela veut dire que parfois on va boucler à l'infini, sans savoir qu'on est parti à l'infini !
Lorsque le programme ne fournit pas sa réponse et que vous trouvez le temps long, vous devez prendre une décision :
On le stoppe ? Mais il va peut-être répondre un jour !
On le laisse travailler ? Mais il est peut-être déjà en train de boucler à l'infini !
Globalement, si on sait que notre problème est indécidable, inutile de tenter de le gérer tel quel, il faut le rendre plus simple. Deux approches de simplification :
modifier la réponse attendue, en lui demandant d'être moins précise. On aura alors un problème légèrement différent mais c'est parfois mieux que rien.
réduire le domaine d'application. On se restreint à un certain type d'instances en entrée. On aura alors (peut-être) un algorithme applicable mais sur un domaine moins large.
Le principe est donc de répondre à un problème moins général mais décidable.
2.3 Hors programme : indécidabilité logique
L'indécidabilité algorithmique et l'indécidabilité logique sont deux notions différentes (mais elles ont un lien interne bien entendu).
En algorithmique, les algorithmes résolvent des instances d'un problème. Les entrées du problème sont donc variables et dépendent de l'instance. Pas d'histoire de théorie mathématique ici (du moins de façon apparente).
Un problème indécidable algorithmiquement est un problème pour lequel l'algorithme boucle parfois à l'infini et ne répond jamais.
Il s'agit donc de savoir :
si on peut trouver la réponse à
un problème aux entrées variables
en utilisant des actions basiques.
En logique, un énoncé est une propriété mathématique dont la description est totalement définie, aucune variable libre.
Un énoncé logique indécidable est un énoncé d'un théorie mathématique bien définie qu'on ne pourra jamais démontrer ou réfuter dans le cadre de cette théorie, car ses axiomes ne permettent pas de trancher.
Il s'agit de savoir :
si on peut trouver une démonstration (dire OUI) ou une réfutation (dire NON) à
un problème figé (un énoncé)
en utilisant les axiomes et théorèmes de la théorie considérée.
Nous allons voir et démontrer l'indécidabilité de l'un des problèmes indécidables les plus connus : le problême de l'arrêt d'un programme.
3.1 Démonstration par l'absurde
Vous avez vu plusieurs façons de réaliser des démonstrations :
La démonstration directe en utilisant l'implication
La démonstration par cas qui liste tous les cas possibles et prouve sur chaque cas qu'on obtient bien la réponse attendue
La démonstration par récurrence (initialisation, hérédité, conclusion à l'infini)
La preuve de correction d'un algorithme (initialisation, conservation, conclusion sur le cas final)
La démonstration par l'absurde
Le principe de la démonstration par l'absurde est le suivant :
On veut établir une preuve sur une propriété P.
On sait qu'une démonstration mathématique ne peut montrer l'absurde en partant de choses valides car, par construction, la logique mathématique est conçue pour préserver la vérité.
On fait l'hypothèse que NON P est valide.
On utilise cette hypothèse dans un raisonnement soigneusement conçu où tout le reste est parfaitement valide et démontré.
On espère aboutir à une contradiction logique.
Puisque la démonstration mathématique préserve la vérité et que le seul point douteux est l'hypothèse de départ, on peut en déduire que l'hypothèse de départ sur la propriété est fausse et qu'elle vaut l'inverse.
Si (NON P implique l'absurde) alors P.
3.2 Problème de l'Arrêt
Présentation informelle
Nous avons vu que algorithme, programme, fonction, machine de Turing ont le même pouvoir de déduction. On utilisera donc ici de façon totalement interchangeable programme et fonction par exemple. C'est pareil.
De façon informelle, on peut décrire le problème de cette façon : "Existe-il un programme capable de prédire l'arrêt de n'importe quel autre programme lancé sur des données quelconques mais connues ?"
Nous allons voir que ce problème de l'arrêt est indécidable : on ne peut pas créer un programme capable de prédire automatiquement si un autre programme dont on connaît le code-souce et les entrées va s'arrêter ou boucler à l'infini.
Les mathématiciens Church et Turing ont prouvé que ce problème est indécidable avant même l'apparition réelle des ordinateurs.
Formalisation sous forme d'une fonction Python
De façon plus formelle : peut-on créer une fonction arret() qui soit capable de prédire qu'une autre fonction quelconque f va s'arrêter un jour. La fonction arret() possède deux paramètres lui permettre de faire son analyse :
le paramètre f reçoit le code-source de la fonction qu'on veut étudier et
le paramètre e reçoit les entrées sur lesquelles f devra travailler.
La thèse de Church-Turing nous dit que cela revient à se demander si cette fonction Python peut exister :
1
2
3
4
defarret(f:code_source,e:données)->bool:"""Prédicat qui renvoie True si f(e) s'arrêtera et répondra un jour"""if l'analyse prédit que f(e) s'arrêtera : returnTrueelse:returnFalse
On profite ici du fait que Python accepte de ne pas passer à la ligne après if ou else si il n'y a qu'une seule instruction à réaliser. Evitez de le faire mais cela va permettre ici d'avoir une vision plus condensée des actions réalisées.
Arret analyse sans exécuter
Il faut bien comprendre que le code-source de f n'est pas réellement exécuté par arret() : il s'agit de créer une fonction qui analyse le code-source et l'entrée fournie de l'autre fonction.
Si vous créez une fonction qui lance réellement f(e) et qui répondra Vrai si f(e) lui répond un jour, il est évident qu'elle ne parviendra pas à répondre si f(e) ne lui rend jamais la main.
3.3 Création d'une fonction inv()
Fonction inv qui inverse la prédiction
Voici le code-souce parfaitement valide d'une fonction inv() qui utilise à l'interne la fonction arret() :
1
2
3
4
5
6
defboucler():whileTrue:passdefinv(f:code_source)->True:ifarret(f,f):boucler()# Si f(f) va répondre, inv() boucleelse:returnTrue# Si f(f) va boucler, inv() renvoie True
Aucune erreur de programmation, c'est bien une fonction totalement correcte. Elle se nomme inv() car :
L05 : si arret prédit que f(f) s'arrêtera alors inv(f) tourne en boucle .
L06 : sinon, si arret prédit que f(f) s'arrêtera alors inv(f) s'arrête en répondant True.
C'est pas bizarre f(f) ?
On lance arret() en lui donnant f et f comme arguments. Cela veut dire qu'on lui demande si la fonction f va s'arrêter lorsqu'elle travaillera avec l'appel sur son propre code-source : f(f).
Ca n'a rien de bizarre :
On peut demander à un programme anti-virus de vérifier son propre code-source.
On peut demander à un compilateur C de compiler son propre code-source.
On peut demander à un programme de compression de comprimer son propre code-source.
...
3.4 Démonstration par l'absurbe de l'indécidablité de l'Arrêt
Nous allons montrer que Arrêt est un problème indécidable et qu'on ne peut donc pas créer en Python le prédicat arret() décrit en 3.2 : elle ne peut pas systématiquement répondre oui ou non.
Pour cela, nous allons utiliser une démonstration par l'absurde.
a. Hypothèse de départ
On fait l'hypothèse que Arrêt est décidable. Sous cette hypothèse, on peut avoir à disposition un prédicat arret() tel que décrit ci-dessous :
1
2
3
4
defarret(f:code_source,e:données)->bool:"""Prédicat qui renvoie True si f(e) s'arrêtera et répondra un jour"""if l'analyse prédit que f(e) s'arrêtera : returnTrueelse:returnFalse
b. Recherche d'une utilisation d'arret() menant à une absurdité
Nous allons construire un programme totalement valide, si ce n'est qu'on doit considérer que arret() existe et fonctionne.
Regardons ce qui va se passer si on fait l'appel suivant en ligne 17 :
arret(inv, inv)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Déclaration des fonctionsdefboucler():whileTrue:passdefinv(f:code_source)->True:ifarret(f,f):boucler()# Si f(f) va répondre, inv() boucleelse:returnTrue# Si f(f) va boucler, inv() renvoie Truedefarret(f:code_source,e:données)->bool:"""Prédicat qui renvoie True si f(e) s'arrêtera et répondra un jour"""if l'analyse prédit que f(e) s'arrêtera : returnTrueelse:returnFalse# Programme principalprint ( arret(inv, inv))
On se demande donc si la fonction inv() s'arrête lorsqu'elle travaille sur son propre code-source. Cela revient mentalement à avoir quelque chose comme ceci :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Déclaration des fonctionsdefboucler():whileTrue:passdefinv(f:code_source)->True:ifarret(f,f):boucler()# Si f(f) va répondre, inv() boucleelse:returnTrue# Si f(f) va boucler, inv() renvoie Truedefarret(f=inv:code_source,e=inv:données)->bool:"""Prédicat qui renvoie True si f(e) s'arrêtera et répondra un jour"""if l'analyse prédit que inv(inv) s'arrêtera : returnTrueelse:returnFalse# Programme principalprint ( arret(inv, inv))
Encore une fois, rien d'étrange pour le moment.
Regardons maintenant ce que va donner la fonction inv() lorsqu'elle travaillera sur son propre code-source, comme sur la ligne 12.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Déclaration des fonctionsdefboucler():whileTrue:passdefinv(f=inv:code_source)->True:ifarret(inv,inv):boucler()# Si inv(inv) va répondre, inv() boucle !else:returnTrue# Si inv(inv) va boucler, inv() répond !defarret(f=inv:code_source,e=inv:données)->bool:"""Prédicat qui renvoie True si f(e) s'arrêtera et répondra un jour"""if l'analyse prédit que inv(inv) s'arrêtera : returnTrueelse:returnFalse# Programme principalprint ( arret(inv, inv))
Cela revient à écrire ceci en explicitant le code en français :
6
7
8
Sur un appel d'inv sur son propre code-source:
Si arrêt prédit que inv(inv) va s'arrêter, inv(inv) boucle sur son appel réel
Sinon, si arrêt prédit que in(inv) va boucler, inv(inv) répond et s'arrête lors de l'appel réel
Nous aboutissons donc à une contradiction : on fait l'hypothèse que le prédicat arret() existe et fonctionne et il prédit l'inverse de ce qu'il doit répondre.
Conclusion de la démonstration
Nous avons fait l'hypothèse de l'existence du prédicat arret() et cela nous a permis de créer un programme totalement rigoureux, à part cette hypothèse.
Cela mène à une contradiction.
L'hypothèse de départ ne peut donc pas être bonne, elle est donc fausse (tiers exclu : c'est soit vrai, soit faux).
Il n'est pas possible de créer un prédicat qui prédit Arret.
Arret est donc un problème indécidable.
4 - Conclusion
Nous avons fait l'hypothèse de l'existence d'une fonction arret capable d'analyser le code de n'importe quel autre programme ou fonction pour savoir si il va s'arrêter et répondre sur l'entrée qu'on lui propose
l'utilisation de cette hypothèse associée à d'autres raisonnements corrects eux mène à une incohérence, un résultat absurde.
Cela veut donc dire que notre hypothèse de départ n'est pas bonne et qu'il n'existe pas de programme ou fonction arret capable d'analyser le code de n'importe quel autre programme ou fonction pour savoir si il va s'arrêter et répondre sur l'entrée qu'on lui propose.
Prenons quelques minutes pour voir ce qu'est cette fameuse machine de Turing même si aucune connaissance n'est attendue à ce sujet dans le programme. Cela vous permettra de comprendre ce qu'on entend par "machine physique".
4.1 Machine de Turing
Il s'agit donc d'une machine composée fondamentalement des éléments suivants :
Un ruban (supposé infini s'il le faut) comportant des cases dans lesquelles on peut écrire des valeurs issues d'un ensemble fini A de valeurs permises à définir. Je prendrais ici A = {∅, 0, 1} par exemple (A comme alphabet).
Une tête de lecture se plaçant au dessus du ruban et capable :
de lire et modifier le contenu de la case actuelle au dessous de laquelle elle se trouve,
de se déplacer à droite ou à gauche de la case actuelle
de lire et modifier une mémoire définissant son état. Elle peut prendre une valeur dans un ensemble fini T d'états. Par exemple T = {'init', 'travail', 'fini'}.
Une table de transition (accessible depuis la tête) permettant de déterminer l'action à réaliser en fonction de ce que contient la case actuelle et la mémoire des états. Par exemple :
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Avec la combinaison (ETAT=INIT, LECTURE=0), on trouve l'instruction désignée dans le tableau (la case du milieu en haut), et on déduit qu'on doit placer ETAT sur TRAVAIL, écrire 0 dans la case (donc on ne fait rien) et se déplacer à droite.
Arrêt : une machine de Turing s'arrête si elle tombe sur une combinaison (état, lecture) qui n'est pas possible dans sa table de transition.
Ici, on voit qu'elle ne possède pas d'instructions à réaliser si l'état est FINI. Elle stoppera donc lorsqu'elle aura atteint cet état.
4.2 Exemple de Machine de Turing
Imaginons un ruban portant notamment des cases vides et une tête de lecture située sur l'une d'entre elles :
Notre ruban contient ∅∅010 au début, la droite de ruban est constituée de cases vides uniquement.
init∅∅010∅∅
Pour savoir ce qu'on doit faire, on cherche le couple (ETAT=init, LECTURE=∅) : on laisse INIT et ∅ et on se déplace à droite.
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
La "nouvelle" configuration après la première séquence :
∅init∅010∅∅
On retrouve le couple (ETAT=init, LECTURE=∅) : même action qui la précédente, on laisse INIT et ∅ et on se déplace à droite.
Nouvelle configuration après la deuxième action :
∅∅init010∅∅
Cette fois, on obtient le couple (ETAT=init, LECTURE=0) : on passe à TRAVAIL, on laisse 0 et on se déplace à droite.
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Nouvelle configuration :
∅∅0travail10∅∅
Cette fois, on obtient le couple (ETAT=travail, LECTURE=1) : on laisse TRAVAIL, on laisse 1, et on se déplace à droite.
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Nouvelle configuration :
∅∅01travail0∅∅
Cette fois, on obtient le couple (ETAT=travail, LECTURE=0) : on laisse TRAVAIL, on laisse 0, et on se déplace à droite.
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Nouvelle configuration :
∅∅010travail∅∅
On obtient le couple (ETAT=travail, LECTURE=∅) : on place FINI, on place 0, et on se déplace à droite.
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Nouvelle configuration :
∅∅0100fini∅
∅
0
1
init
Etat ← init Case ← ∅ Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
travail
Etat ← fini Case ← 0 Vers Droite
Etat ← travail Case ← 0 Vers Droite
Etat ← travail Case ← 1 Vers Droite
Et là, nous tombons sur un problème : le couple ('fini', ∅) n'est pas présent dans la table de transition : cette donnée n'est pas interprétable comme une instruction !
Dans ce cas, la machine s'arrête.
On est parti de ce ruban :
∅∅010∅∅
Et on obtient ce ruban :
∅∅0100∅
Le ruban de la machine est passée de 010 (soit 2 en décimal) à 0100 (soit 4 en décimal). Voilà ce que fait la table de transition de cette machine de Turing : elle multiplie par deux l'entier naturel encodé sur le ruban !
Fin sur une "vraie" machine de Turing
Pour parvenir à exécuter des actions à la suite les unes des autres, la Machine doit normalement s'arrêter au début de sa bande, tout à gauche.
Ici, il ne s'agit que d'un exemple rapide mais il faudrait rajouter des états supplémentaires pour parvenir à arrêter la tête de lecture correctement, sur la première case.
En conclusion, cette machine permet donc de formaliser ce que peut ou pas calculer un "système physique".
Puisqu'une machine donnée possède un nombre d'états dénombrables (nombre de cases et états), on est capable de les lister une par une en étant certain de ne pas en oublier une.
Exemple : 2 cases acceptant 0,1 sur le ruban et 2 états 0,1 donne 8 machines :
Etat 0 et Ruban 00
Etat 0 et Ruban 01
Etat 0 et Ruban 10
Etat 0 et Ruban 11
Etat 1 et Ruban 00
Etat 1 et Ruban 01
Etat 1 et Ruban 10
Etat 1 et Ruban 11
Or, nous ne pouvons pas faire la même chose avec les problèmes à résoudre : nous n'obtenons pas un ensemble dénombrable. Cela veut donc dire qu'il existe nécessairement des choses que la machine de Turing (ou, d'après la thèse de Church-Turing, n'importe quel système informatique) ne pourra pas résoudre.
Cette partie doit être vue comme un exposé de culture générale. Il ne s'agit que de vous montrer que la notion de décidabilité a été traitée sérieusement par des gens compétents, pas de le démontrer.
Les notions de décidabilité et d'indécidabilité sont loin d'être évidentes. Vous allez voir d'ailleurs qu'elles ne se limitent pas qu'aux algorithmes et à leurs limitations "physiques".
1 - Axiomes et théories mathématiques axiomatiques
Une théorie mathématique axiomatique est composée d'un ensemble d'axiomes, des propositions à la base de la théorie voulue. On les considère intrinsèquement vraies dans le cadre de la théorie. Ce sont ces axiomes qui définissent l'objet abstrait sur laquelle la théorie travaille.
Important : les axiomes ne doivent pas être contradictoires entre eux bien entendu.
La géométrie Euclidienne dispose de son jeu d'axiomes
L'arithmétique dispose de son jeu d'axiomes
La théorie des ensembles dispose de son jeu d'axiomes
...
L'arithmétique peut ainsi se résumer à un certain nombre d'axiomes. Voici les trois premiers :
L'élément appelé zéro et noté 0 est un entier naturel.
Tout entier naturel n a un unique successeur, noté s(n) ou Sn qui est un entier naturel.
Aucun entier naturel n'a 0 pour successeur.
...
2 - Construire des démonstrations à partir des axiomes
En associant ces axiomes à l'aide de la logique, on peut démontrer de nouvelles propriétés. D'où l'image des legos.
Une propriété valide dans une théorie n'est donc jamais une invention : elle est présente depuis le début. Encore fallait-il savoir comment "l'assembler" pour la démontrer.
Un théorème est une propriété démontrée dont la portée d'utilisation est grande, ce qui justifie le fait qu'il soit reconnu dans le cadre d'une théorie donnée. Beaucoup de propriétés démontrées n'ont pas le statut de "théorèmes".
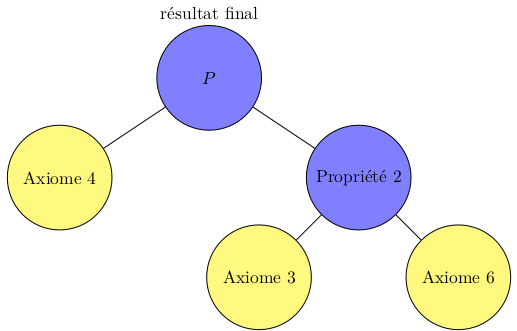
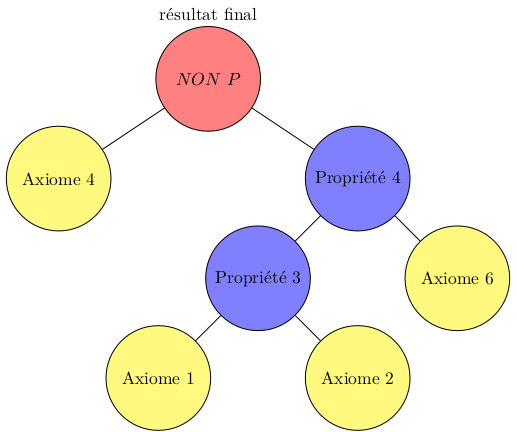
La démonstration d'une proposition P pourrait donc être représentée comme un Arbre dont
les feuilles sont les axiomes et théorèmes (propriétés déjà démontrées et reconnues), et
la racine est liée à la proposition P qu'on veut démontrer démontrer (aboutir à P est VRAI) ou réfuter (aboutir à NON P est VRAI).
Cet Arbre est un peu particulière puisque pour le réaliser on part des feuilles et on remonte vers la racine qui sera P si on démontre la propriété ou NON P si on la réfute. Les liens de parenté sont établis en utilisant les règles de la logique que nous avons vu (ET, OU, NON, IMPLIQUE...)
Cela devrait vous faire penser à nos algorithmes : des associations d'instructions aboutissant à une réponse.
3 -Le choix des axiomes
Le choix des axiomes à prendre en compte pour rendre chacune des théories "efficaces" est un enjeu majeur.
Une fois les bases de la logique mathématique posées par les travaux de Bool et De Morgan, Frege va clarifier et formaliser le raisonnement logique en 1879 et va dégager trois caractéristiques qu'une théorie mathématique devrait avoir (notez que j'utilise le conditionnel) :
cohérence : impossibilité de démontrer une proposition et son contraire
complétude : à l'intérieur de la théorie, tout énoncé A est
soit démontrable (A est VRAI),
soit réfutable (not A est VRAI)
décidabilité : il existe une procédure de décision permettant de tester tout énoncé de la théorie.
Tout ceci va aboutir à une profonde refondation des mathématiques par les théoriciens de l'époque : la formalisation de la logique mathématique et l'apparition des théories axiomatiques. Grande réussite des mathématiques : son auto-réflexivité lui permet d'étudier des objets qui sont eux-mêmes... les théories mathématiques.
De nombreux théoriciens (dont Hilbert) vont justement tenter de trouver quels axiomes choisir pour chaque théorie de façon à éviter deux problèmes :
Si on sélectionne trop peu d'axiomes comme fondation d'une théorie, on peut aboutir à des situations où certaines propositions (qui pourtant sont bien VRAIES ou FAUSSES) ne sont ni démontrables, ni réfutables : la théorie construite est incompléte : on manque de "briques" pour construire certains raisonnements.
On peut ainsi trouver des énoncés pour lesquels :
alors que la proposition P est vraie pour l'ensemble d'objets qui vous intéresse, on ne parviendra jamais à le démontrer... Pourquoi ? Simplement car il existe au moins un autre ensemble d'objets compatibles avec la théorie étudiée dans laquelle P n'est pas vraie. Dans ce cas, pour votre ensemble, vous ne trouverez jamais de contre-exemples disant que c'est faux, mais en même temps, vous ne pourrez jamais démontrer que c'est vrai ! Il restera donc toujours un petit doute quand on fait qu'on soit bien dans cette situation.
même chose avec une proposition P qui semble fausse dès que vous l'appliquez à votre ensemble d'objets, mais que vous ne parvennez pas à réfuter.
Si on revient à l'image de l'Arbre, cela veut dire qu'on ne parviendra jamais à atteindre P ou NON P en partant des axiomes et théorèmes (propositions démontrées) de la théorie. La théorie ne peut donc pas trancher (ce qui ne veut pas dire que la propriété P n'est pas soit VRAI soit FAUX) appliquée aux objets qui vous intéresse vous.
Si on sélectionne trop d'axiomes comme fondation d'une théorie, il existe des propositions P pour lesquelles on parvient à montrer P avec une démonstration et à réfuter P avec une autre démonstration : la théorie construite est incohérente. Là, c'est l'inverse du cas précédent : on a pris trop de briques sans se rendre compte qu'elles étaient en partie contradictoire.
Situation embarrassante...
C'est une théorie qui prouve tout et son contraire...
A partir du moment où ceci a été clairement établi, plusieurs mathématiciens ont tenté pendant des années d'aboutir au parfait choix d'axiomes, un choix qui permettrait d'aboutir à ceci :
On aurait alors une théorie dans laquelle on pourrait tout démontrer ou réfuter. On pourrait répondre à toutes les énoncés.
Trouver cette théorie parfaite permettrait de pouvoir répondre à n'importe quel énoncé portant sur l'objet d'études de la théorie. Pourvu qu'on parvienne comment la démontrer ou la réfuter. Mais savoir qu'une démonstration ou une réfutation existe serait déjà confortable : on sait au moins qu'on travaille à trouver quelque chose qui existe.
4 - La réponse de Kurt Gödel
Un jeune mathématicien autrichien (naturalisé américain après sa fuite du régime nazi) va alors parvenir à démontrer en 1931 deux théorèmes importants de la logique mathématique.
Le premier théorème d'incomplétude établit qu'une théorie suffisante pour y démontrer les théorèmes de base de l'arithmétique est nécessairement incomplète : certains énoncés seront nécessairement indécidables dans cette théorie. Rappelons que cela signifie simplement qu'on ne pourra jamais les démontrer ou les réfuter dans le cadre de cette théorie.
Le second théorème d'incomplétude va lui établir qu'une théorie cohérente ne peut pas démontrer sa propre cohérence.
Notez bien que cela n'empêche pas les mathématiciens de dormir : ne faites pas dire à ces théorèmes plus qu'ils ne le font. Cela veut juste dire
qu'il existera toujours des énoncés indécidables dans une théorie cohérente
qu'on ne peut pas démontrer qu'une théorie est cohérente même si elle l'est : cela fait partie des énoncés... indécidables de la théorie.
Si les axiomes utilisés pour bâtir les théories reconnues actuelles menaient à des théories incohérentes, quelqu'un aurait bien réussi à trouver un cas problématique. Et même dans ce cas, il "suffirait" sans doute de redéfinir un système d'axiomes un peu plus restreint. Certains choses seraient à revoir, mais pas tout. C'est ce qui s'est passé avec la première version de la théorie des ensembles. Après ajustement, elle n'en est que plus solide.
Attention, il faut bien comprendre que nous parlons ici de l'indécidabilité logique d'un énoncé dans une théorie précise. Il est possible que l'énoncé soit décidable dans le cadre d'une autre théorie.
L'informatique théorique étant l'étude des fondements logiques et mathématiques de l'informatique, on va bien entendu retrouver les mêmes conséquences.
Néanmoins, souvenez-vous de ce qu'on vous a raconté sur les algorithmes : ils ne sont pas conçu pour résoudre un énoncé unique mais toute une classe d'énoncés similaires.
On le résumera en disant qu'un algorithme est concu pour résoudre une classe de problèmes et pas une seule instance du problème.
Et certains problèmes ne seront pas résolvables par un algorithme. On dira que ces problèmes sont indécidables de façon absolue.
5 - L'algorithme de démonstration ultime ?
Nous avons vu qu'une démonstration est en quelque sorte un Arbre utilisant les axiomes d'une théorie et de la logique.
Vous connaissez certainement l'histoire du singe qu'on place devant un clavier. En le laissant tapant ce qu'il veut pendant un temps infini, on pourrait obtenir une copie de n'importe quelle oeuvre.
Nous pourrions faire de même avec les démonstrations : faire tourner un programme qui teste un par un tous les Arbres de démonstration possibles à partir d'un certain ensemble d'axiomes jusqu'à démontrer ou réfuter n'importe quelle proposition P qu'on lui fournit en ENTREE. Si, pendant le parcours des raisonnements possibles, nous obtenons
un Arbre dont la racine est P, nous aurons démontré la proposition P. L'algorithme pourrait renvoyer True.
un Arbre dont la racine est NON P, nous aurons réfuté la proposition P. L'algorithme pourrait renvoyer False.
Malheureusement, dans le cadre d'une théorie suffisamment élaborée, nous ne pourrons jamais prouver la correction de cet algorithme à cause du premier théorème d'incomplétude : certaines propriétés font partie des propriétés indécidables : il est donc certain que l'algorithme va parfois établir des Arbres de démonstration sans jamais tomber ni sur P, ni sur NON P pour la bonne raison de cette proposition précise n'est ni démontrable, ni réfutable !
Notre programme pourrait donc tomber par hasard sur certaines démonstrations, mais ne peut pas démontrer ou réfuter n'importe quelle proposition fournie en ENTREE : il n'est donc pas CORRECT
Il s'agit donc d'un problème indécidable car même en changeant de théorie cohérente, il y aura toujours des propositions indécidables.
La preuve de terminaison d'un algorithme permet d'affirmer qu'il s'arrête de façon certaine sur toutes les entrées valides qu'on lui fournit (c'est à dire les entrées respectant les préconditions).
[Théorème de la] Preuve de terminaison (en français) :
Si les deux propositions A et B suivantes sont vraies alors la boucle s'arrête :
A : la boucle peut s'écrire sous la forme TANT QUEVARIANT>0
B : le VARIANT est une suite d'ENTIERS strictement décroissante.
Justification : si le variant est effectivement une suite entière décroissante, il va nécessairement décroître et devenir négatif ou nul. Cela va alors provoquer l'arrêt de la boucle puisqu'on boucle tant qu'il est positif uniquement.
[Théorème de la] Preuve de terminaison (en langage mathématique) :
(A et B) ⇒ Arrêt
Cette écriture peut se traduire de ces deux façons similaires :
Si A est vrai et B est vrai, alors l'algorithme s'arrête TOUJOURS au bout d'un certain temps.
A vrai et B vrai implique que l'algorithme s'arrête TOUJOURS au bout d'un certain temps.
Attention à la négation
Si A ou B sont faux, on n'apprend rien sur l'arrêt certain de l'algorithme : il est possible que l'algorithme s'arrête toujours, boucle parfois ou boucle toujours.
Il s'agit bien d'une implication, pas d'une équivalence.
(A et B) ⇒ Arrêt
non (A et B) ⇒ Aucune information certaine
Les formules de De Morgan permettent d'ailleurs de l'écrire de cette façon également :
(non A) ou (non B) ⇒ Aucune information certaine
Cela veut bien dire : "Si A est faux ou si B est faux alors on ne peut tirer aucune conclusion sur l'arrêt certain ou pas de cette boucle".
Rappel : Preuve de correction et invariant
Définitions
La preuve de correction d'un algorithme permet d'affirmer
qu'il fournit toujours une réponse correcte
sur toutes les entrées valides qu'on lui fournit.
Pour faire la preuve de correction d'un algorithme, il faut trouver un INVARIANT : une propriété P vérifiable qui reste vraie lors des différentes étapes de l'algorithme.
Un INVARIANT DE BOUCLE est
une propriété vrai avant la première itération ;
qui reste vraie à chaque itération de la boucle ;
elle est donc vraie après avoir effectué le dernier tour de boucle.
Cet invariant permettra de prouver que le résultat final après exécution est bien le résultat attendu.
Malheureusement, il n'y a pas de méthodologie automatique miraculeuse pour trouver cet invariant. Il faut réfléchir et tenter des choses, comme avec toute démonstration.
Démonstration en 3 phases
Une fois qu'on dispose d'un INVARIANT P, la démonstration se fait en trois temps.
Phase d'initialisation : P0 est VRAI
On doit prouver que l'INVARIANT est VRAI avant le premier tour de boucle. On a donc fait 0 tour en entier.
Le plus souvent, cette partie est triviale.
Phase de conservation : Pk➡ Pk+1
Hypothèse de départ :
On fait l'hypothèse que la propriété Pk est vraie après un certain nombre de tours de boucle.
Déroulement d'un nouveau tour de boucle
On doit montrer qu'en réalisant un tour supplémentaire, l'invariant P reste vrai à la fin de cette boucle. Pk+1 sera donc vérifiée.
On peut donc résumer cela par l'équation Pk➡ Pk+1 qui veut dire SI Pk est vraie alors Pk+1 sera encore vraie après un tour supplémentaire.
Phase de terminaison
On doit prouver qu'après le dernier tour, l'algorithme termine exactement sur la situation voulue. Ni trop, ni trop peu.
C'est pour cela qu'on nomme cet étape "la phase de terminaison", à ne pas confondre avec la preuve de terminaison / preuve d'arrêt.
On utilisant (1) + (2), on montre ceci :
P0➡ P1➡ P2➡ P3... >
On utilisant (3), on montre en plus que l'algorithme s'arrête au bon moment.
P0➡ P1➡ P2➡ P3... ➡ Pfinal
Attention, la méthode est proche des démonstrations pour la récurrence mais pas vraiment identique. C'est pour cela d'ailleurs que les noms ne sont pas les mêmes. Avec la récurrence, les noms des phases sont
initialisation,
hérédité et
conclusion.
Activité publiée le 24 05 2021
Dernière modification : 24 05 2021
Auteur : ows. h.










{kind=link}