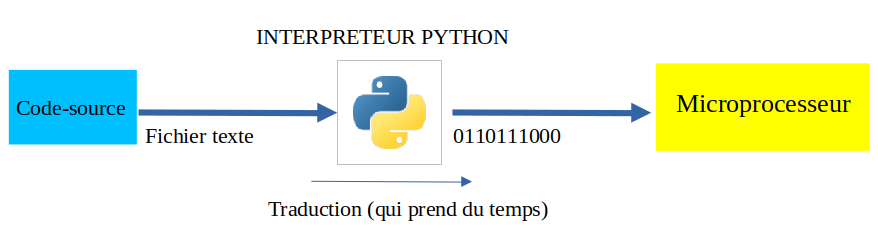
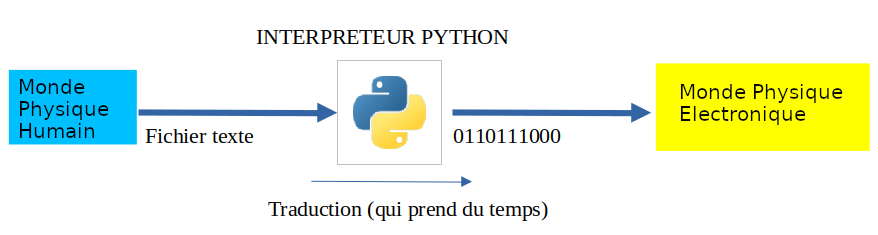
Langage haut-niveau : ne pas se soucier de la réalité du stockage
1 mois en NSI et pas un mot sur le binaire pour l'instant. Pourquoi ? Simplement car Python et Javascript sont des langages dits "de haut-niveau" : ils sont conçus pour que le développeur n'ai pas besoin de se soucier de la façon dont les données sont réellement gérées physiquement.
Le développeur parle à l'interpréteur Python.
L'interpréteur Python traduit et parle en langage machine.
On peut dire que l'interpréteur joue le rôle d'interface entre les deux mondes.
Langage bas-niveau : gestion du stockage réel des données
Au niveau électronique physique, l'ordinateur stocke les données sous forme d'octets.
Un système informatique ne sait que stocker des 0 ou des 1 .
Il faut donc savoir passer d'une représentation décimale (base 10) à une représentation binaire (base 2).
Encore faut-il savoir comment cela fonctionne...
C'est le principe de cette première activité.
Et si on ne sait pas comment ça fonctionne, c'est grave ?
Dans 99% des cas, non. Les langages de haut niveau permettent même de programmer sans jamais faire de binaire. D'ailleurs, la preuve : vous n'en avez pas fait une ligne depuis le début de l'année !
Logiciel nécessaire pour l'activité : Arduino, la bibliothèque Makeblock et un robot, uniquement si vous voulez reproduire l'expérience d'introduction.
Exercices corrigés complémentaires de cours : exos
On notera que la boucle FOR se code différement qu'en Python mais qu'on retrouve dans l'ordre :
la valeur initiale : vitesse=0
La valeur extrême qu'on ne pourra pas atteindre : vitesse<500. Comme on a noté strictement inférieur, la vitesse atteindra 499, pas 500.
L'augmentation de 1 à chaque tour de boucle : vitesse++. C'est une façon d'écrire vitesse=vitesse+1
L'une des grosses différences du C (et d'Arduino) par rapport à Python est qu'on doit impérativement fournir le type de la variable qu'on est en train de créer. Ici, j'ai choisi de stocker mes entiers dans une variable de type byte. Dans ce contexte, celui correspond à un octet. Nous verrons ce que cela représente dans cette activité.
Finalement, comment afficher la valeur de la variable vitesse lors de chaque bouclage ?
En lisant la documentation, on se rend compte qu'il existe une méthode permettant d'agir sur les afficheurs : la méthode display.
La réalité physique vient d'interagir avec nos instructions qui sont censées fonctionner, mais non...
On constate que
Déjà, j'ai du mal à trouver mon bouton. Bon ça, c'est pas grave.
Ensuite, le moteur patine à faible vitesse. C'est normal aussi. Il ne parvient pas à contrer les frottements statiques si on ne fournit pas assez de puissance.
Par contre, il va bien de plus en plus vite mais s'arrête à 255 !
Et le compteur repart à 0 ! Et ensuite, c'est la boucle infinie alors qu'on a une boucle bornée POUR !
Si vous avez compris comment fonctionne la base 10, vous avez compris la base 2 puisque c'est plus simple : il n'y a que deux chiffres possibles 0 ou 1 !
Si on ouvre une clé USB, on peut voir ceci : pas facile de voir les 0 ou les 1 .
Par contre, dans les premiers ordinateurs, les 0 et les 1 des programmes étaient stockés sur des cartes perforées : c'était plus simple à visualiser : c'est perforé ou non perforé. Deux états physiques bien visibles.
Première partie : les bits
Voyons comment fonctionne le décodage d'un nombre en base 2 ainsi que l'addition.
Il suffit de transformer ce que nous avons vu avec la base 10.
Première modification : nom et contenu des cases
3.1 - Que peut-on mettre dans les cases d'un nombre en base 2 ?
flowchart LR
0 --> 1
Chaque case se nomme un BIT, mot qui provient de la contraction de BINARY DIGIT.
Que peut-on placer dans un bit ? Des chiffres.
Combien et lesquels ? Base 2 donc 2 CHIFFRES :
Deuxième modification : le poids des cases
3.2 - Poids des bits
Le bit de poids faible est toujours à droite.
On peut facilement trouver le poids des cases en utilisant les puissances de 2 puisqu'on multiplie par deux à chaque fois qu'on décale vers la gauche :
Le poids de cette case est
8
4
2
1
qu'on peut écrire sous la forme
23
22
21
20
20 = 1
21 = 2
22 = 2*2 = 4
23 = 2*2*2 = 8
24 = 2*2*2*2 = 16
25 = 2*2*2*2*2 = 32
...
Exemple 1
Si j'écris un nombre à 4 bits M = 1 0 1 1 , je dois faire ceci pour trouver la valeur de ce nombre en base 10 :
Nombre M =
1
0
1
1
Le poids de cette case est
8
4
2
1
On obtient donc
8
0
2
1
D'où la valeur de M en base 10 : M = 8 + 0 + 2 + 1 = 11 .
Exemple 2
Si j'écris un nombre à 4 bits M = 1 1 0 0 , je dois faire ceci pour trouver la valeur de ce nombre en base 10 :
Nombre M =
1
1
0
0
Le poids de cette case est
8
4
2
1
On obtient donc
8
4
0
0
D'où la valeur de M en base 10 : M = 8 + 4 + 0 + 0 = 12 .
01° Déterminer la valeur en base 10 des nombres A, B, C, D fournis en binaire :
Nombre A
Nombre A =
1
0
0
0
Le poids de cette case est
8
4
2
1
On obtient donc
?
?
?
?
Nombre B
Nombre B =
0
0
1
0
Le poids de cette case est
8
4
2
1
Nombre C
Nombre C =
0
1
1
0
Nombre D
Nombre D =
1
1
1
0
...CORRECTION...
A = 8 + 0 + 0 + 0 = 8 en base 10
B = 0 + 0 + 2 + 0 = 2 en base 10
C = 0 + 4 + 2 + 0 = 6 en base 10
D = 8 + 4 + 2 + 0 = 14 en base 10
3.3 - Notation des bases
C'est un peu bizarre d'écrire que 1100 = 12 ou que 1011 = 11 non ?
Le problème vient du fait qu'un nombre en base 10 peut très bien ne contenir que des 1 et 0. Mille par exemple : 1000.
Or 1000 pourrait également représenter un nombre en base 2.
Nombre M =
1
0
0
0
Le poids de cette case est
8
4
2
1
On obtient donc
8
0
0
0
D'où la valeur de M en base 10 : M = 8 + 0 + 0 + 0 = 8 .
On voit donc qu'il faudrait noter (1000 en base 2) vaut (8 en base 10).
Pour rendre les choses plus claires, une notation courante consiste à indiquer la base en indice, avec ou sans parenthèses.
N = (1000) 2 = (8) 10
N = 1000 2 = 8 10
Le décimal (base 10) étant notre base naturelle, on la précise rarement lorsqu'on fournit un nombre dans cette base. On retrouve assez souvent cette façon de faire dans les textes :
10002 = 8
Sous entendu, 8 en base 10 puisqu'on ne précise pas la base.
A titre d'exemple final, voilà la correction de l'exercice 1 en utilisant ces notations :
A = 1000 2 = ( 8 + 0 + 0 + 0 ) 10 = 8
B = 0010 2 = ( 0 + 0 + 2 + 0 ) 10 = 2
C = 0110 2 = ( 0 + 4 + 2 + 0 ) 10 = 6
C'est déjà plus clair.
2e partie : Incrémentation et addition
Alors ça fonctionne comment l'addition ? Pourquoi 1 2 + 1 2 donne 10 2 ? On se le demande, non ?
Jusqu'à 1, il n'y a pas de difficulté, il suffit de suivre la liste des CHIFFRES disponibles : 0 puis 1 .
3.4 - Incrémenter en binaire (rajouter 1)
flowchart LR
0 --> 1
Lorsqu'on veut rajouter 1 dans une cases, la case a deux valeurs de départ, donc il y a deux cas à gérer.
Un 0 devient son successeur 1
Un 1 étant le dernier chiffre en base 2, on repasse à 0 en rajoutant une retenue 1 dans la case juste à gauche.
CLIQUER SUR L'IMAGE pour ANIMER ou STOPPER
Utiliser une base différente de 10 ne change rien à la "logique" des nombres.
Après ||| choses, il y a encore |||| choses quelque soit la façon dont on exprime le nombre de choses.
C'est comme l'idée d'un chat. Le fait de dire "cat" en anglais ne change rien à l'idée derrière "chat" en Français ou "gato" en Espagnol ou "Katze" en Allemand ou encore "猫" en Japonais...
Il s'agit juste d'un langage.
Quelques exemples
Exemple 1 : le successeur de 02 ?
Nombre de base
0
Si on rajoute +1 à l'unité
+1
on obtient
1
...EXPLICATION...
On peut augmenter le chiffre de l'unité 0 en le faisant juste passer au chiffre suivant : 1 .
Exemple 2 le successeur de 12 ?
Nombre de base
1
Si on rajoute +1 à l'unité
+1
+1
on obtient
1
0
...EXPLICATION...
On ne peut augmenter le chiffre de l'unité qui est déjà à 1 .
On le repasse donc à 0 ET on incrémente la case juste à gauche.
La case des "dizaines" était initialement à 0 : elle passe donc à 1 .
Exemple 3 le successeur de 102 ?
Nombre de base
1
0
Si on rajoute +1 à l'unité
+1
on obtient
1
1
...EXPLICATION...
On peut augmenter le chiffre de l'unité 0 en le faisant juste passer au chiffre suivant : 1 .
Exemple 4 le successeur de 112 ?
Nombre de base
1
1
Si on rajoute +1 à l'unité
+1
+1
+1
on obtient
1
0
0
...EXPLICATION...
On ne peut augmenter le chiffre du bit de poids faible qui est déjà à 1 .
On le passe donc à 0 ET on incrémente la case juste à gauche.
La case suivante était initialement à 1 : elle passe donc à 0 également et on va devoir augmenter de 1 la case suivante.
Le chiffre de la case la plus à gauche 0 passe donc à 1 .
02° Compléter la séquence de nombres binaires de 000 à 111 en incrémentant le nombre précédent de 1 à chaque fois (vous pouvez modifier les valeurs dans les cases vides ? en cliquant sur le caractère. Indiquer sur votre copie le nombre équivalent en base 10 dans la dernière colonne.
0
0
0
En base 10 ?
0
0
1
En base 10 ?
?
?
?
En base 10 ?
?
?
?
En base 10 ?
?
?
?
En base 10 ?
?
?
?
En base 10 ?
?
?
?
En base 10 ?
1
1
1
En base 10 ?
...CORRECTION...
0
0
0
0
0
0
1
1
0
1
0
2
0
1
1
3
1
0
0
4
1
0
1
5
1
1
0
6
1
1
1
7
3e partie : nombres de cas possibles
Si on possède une case ? à remplir, on peut donc définir 2 valeurs de 0 à 1 .
Comme le premier cas est numéroté 0, on a bien 1+1 = 2 valeurs possibles.
Si on dispose de 2 cases ?? à remplir, on peut définir des valeurs de 00 à 11 .
Comme le premier cas est numéroté 0, on a bien 3+1 = 4 valeurs possibles :
Cas 0 : 00
Cas 1 : 01
Cas 2 : 10
Cas 3 : 11
Si on dispose de 3 cases ??? à remplir, on peut définir des valeurs de 000 à 111 .
Comme le premier cas est numéroté 0, on a bien 7+1 = 8 valeurs possibles.
Cas 0 : 000
Cas 1 : 001
Cas 2 : 010
Cas 3 : 011
Cas 4 : 100
Cas 5 : 101
Cas 6 : 110
Cas 7 : 111
On voit bien qu'il y a une généralisation à trouver. Laquelle ?
Je vous laisse chercher un peu ...
Et la réponse est :
3.5 - Nombre de cas dénombrables en base 2
Nombre de cas possibles avec X bits : le nombre de valeurs possibles est 2X.
Les X bits à 0 -Valeur minimale avec X bits : 0
Les 8 bits à 1 -Valeur maximale avec X bits : 2X - 1
Exemple : si on dispose de 8 bits
Le nombre de possibilités est 28 = 256
Les 8 bits à 0 - Valeur minimale avec 8 bits : 0
Les 8 bits à 1 - Valeur maximale avec 8 bits : 255
Bilan sur la base 2 (binaire)
Résumé binaire - base 2
flowchart LR
0 --> 1
Que peut-on mettre dans les cases d'un nombre en base 2 ?
Chaque case se nomme un BIT (contraction de BINARY DIGIT).
Les 2 CHIFFRES de la base 2 sont : 0 ou 1 .
On peut facilement trouver le poids des cases en utilisant les puissances de 2 :
Le poids de cette case est
8
4
2
1
qu'on peut écrire sous la forme
23
22
21
20
Méthode à utiliser pour incrémenter (rajouter 1)
Si le bit est à 0 , on le place à 1 .
Si le bit est à 1 , il s'agit du dernier chiffre disponible. On replace donc le bit à 0 ET on rajoute 1 dans la case juste à gauche.
Dans l'autre sens, ce n'est pas plus compliqué lorsque le nombre n'est pas grand : il suffit d'activer progressivement les bits de poids forts nécessaire pour encoder le nombre.
4.2 - Octet : décimal vers binaire, méthode intuitive
Nous allons présenter ici la méthode de l'activation progressive.
On active progressivement les bits en commençant systématiquement par le bit le plus grand nécessaire pour encoder correctement le nombre entier.
Exemple avec 121
CLIQUER SUR L'IMAGE pour ANIMER ou STOPPER
Pour obtenir une correction pas à pas étape par étape, vous pouvez suivre le déroulé ci-desous.
...Déroulé pas à pas...
Nombre M =
?
?
?
?
?
?
?
?
Les bits codent
128
64
32
16
8
4
2
1
Le bit associé à 128 est inutile : on le place à 0.
On active par contre le bit associé à 64 qu'on place à 1.
Il nous reste donc 121 - 64 = 57 à encoder.
Nombre M =
0
1
?
?
?
?
?
?
Les bits codent
128
64
32
16
8
4
2
1
On active donc le bit de 32. Et il reste 57 - 32 = 25 à encoder.
Nombre M =
0
1
1
?
?
?
?
?
Les bits codent
128
64
32
16
8
4
2
1
On active donc le bit de 16. Et il reste 25 - 16 = 9 à encoder.
On active donc le bit de 9. Et il reste 9 - 8 = 1 à encoder : il suffit d'activer le bit de poids faile et c'est fini. On sait qu'on peut placer les autres à 0.
Nombre M =
0
1
1
1
1
0
0
1
Les bits codent
128
64
32
16
8
4
2
1
Sur une copie, on peut justifier de cette façon :
Pour encoder 121 :
On active le bit du 64. Il reste 121 - 64 = 57 à encoder.
On active le 32. Il reste 57 - 32 = 25.
On active le 16. Il reste 25 - 16 = 9.
On active le 8. Il reste 9 - 8 = 1.
On active le 1. Il reste 1 - 1 = 0. Fini
04° En activant progressivement les bits de poids fort nécessaires, trouver l'encodage binaire des entiers suivants :
Octet D : 37
Octet E : 72
Octet F : 123
4.3 - Octet : décimal vers binaire, méthode systématique
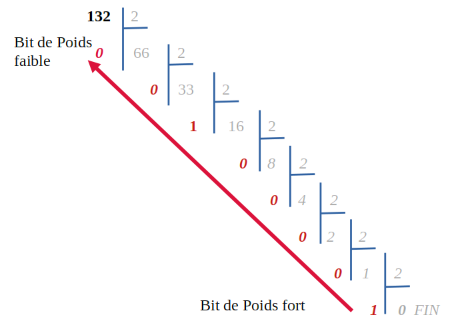
La méthode de la division euclidienne par deux est plus systématique. Elle consiste à diviser le nombre par deux jusqu'à atteindre un quotient de 0.
Les restes de la division euclidienne vont fournir les valeurs des bits.
CLIQUER SUR L'IMAGE pour ANIMER ou STOPPER
On effectue la division euclidienne de 132 par 2. On obtient un reste de 0 et un résultat de 66.
On effectue la division euclidienne de 66 par 2. On obtient un reste de 0 et un résultat de 33.
On effectue la division euclidienne de 33 par 2. On obtient un reste de 1 et un résultat de 16.
...
On continue jusqu'à avoir un résultat de 0.
Comment obtenir la décomposition ?
En partant du bas pour le bit de poids fort et en remontant vers le haut jusqu'au bit de poids faible :
On peut alors écrire que 132 10 = 1000 0100 2.
05° En utilisant la méthode de la division par deux, trouver l'encodage binaire des entiers suivants :
Lorsqu'on veut mémoriser une information en machine, il suffit donc d'attribuer une valeur à une information.
Cela se nomme un encodage.
Les techniques d'encodage n'ont rien de secret : elles doivent être connues et diffusées de façon à pouvoir encoder puis à décoder.
Ne confondez pas encodage et chiffrement/cryptage.
5.1 Encodage d'un entier naturel
La première utilisation de l'octet est bien entendu la mise en mémoire d'un nombre entier naturel de 0 à 255 inclus.
5.2 Encodage d'un caractère
Un autre exemple: l'encodage de caractères, dont toutes les versions sont compatibles avec les valeurs de l'encodage ASCII pour les valeurs inférieures à 128.
En ASCII, la lettre A est encodé par un octet valant 65, le B par 66...
Voici un court extrait de cette table d'encodage :
_0
_1
_2
_3
_4
_5
_6
_7
_8
_9
6_
<
=
>
?
@
A
B
C
D
E
7_
F
G
H
I
J
K
L
M
N
O
8_
P
Q
R
S
T
U
V
W
X
Y
9_
Z
[
\
]
^
_
`
a
b
c
10_
d
e
f
g
h
i
j
k
l
m
11_
n
o
p
q
r
s
t
u
v
w
On voit que
le signe inférieur < est encodé par le nombre 60,
le A par le nombre 65,
le a par 97 ...
Avec ce type d'encodage de caractères sur un octet, on ne peut donc représenter que 256 caractères différents.
5.3 Encodage des couleurs
Un dernier exemple : l'encodage des couleurs. Vous avez peut-être vu en seconde que les pixels sont composés d'une composant R pour Red, G pour Green et B pour Blue.
Chaque composante est une valeur qui est stockée dans un octet. On dispose donc de 256 nuances de la couleur, variant de 0 à 255.
Un pixel prend donc une place mémoire de 3 octets.
Si on rajoute une couche de transparence, on lui attribue également un octet, pour atteindre un poids de 4 octets par pixel.
Voici les intensités de rouge pour des valeurs comprises entre 0 et 255. Vous allez voir que cela suffit car l'oeil humain ne peut déjà pas distinguer des intensités de valeurs proches.
Valeur
Visuel
Valeur
Visuel
Valeur
Visuel
0
85
170
1
86
171
2
87
172
3
88
173
4
89
174
5
90
175
6
91
176
7
92
177
8
93
178
9
94
179
10
95
180
11
96
181
12
97
182
13
98
183
14
99
184
15
100
185
16
101
186
17
102
187
18
103
188
19
104
189
20
105
190
21
106
191
22
107
192
23
108
193
24
109
194
25
110
195
26
111
196
27
112
197
28
113
198
29
114
199
30
115
200
31
116
201
32
117
202
33
118
203
34
119
204
35
120
205
36
121
206
37
122
207
38
123
208
39
124
209
40
125
210
41
126
211
42
127
212
43
128
213
44
129
214
45
130
215
46
131
216
47
132
217
48
133
218
49
134
219
50
135
220
51
136
221
52
137
222
53
138
223
54
139
224
55
140
225
56
141
226
57
142
227
58
143
228
59
144
229
60
145
230
61
146
231
62
147
232
63
148
233
64
149
234
65
150
235
66
151
236
67
152
237
68
153
238
69
154
239
70
155
240
71
156
241
72
157
242
73
158
243
74
159
244
75
160
245
76
161
246
77
162
247
78
163
248
79
164
249
80
165
250
81
166
251
82
167
252
83
168
253
84
169
254
85
170
255
Nous retrouverons cette notion d'octets dans beaucoup d'activités. Nous verrons ainsi plus dans le détail l'encodage et la taille nécessaire pour placer en mémoire un texte, une image ou une vidéo.
Il existe deux types de sous-unités de l'octet mais seul le premier est couramment utilisé dans la description des produits.
6.1 Unités courantes : k M G T
Sous-unité
Valeur en décimal
Pourquoi ?
Un kilo (k) représente 103
1 000
Un Méga (M) représente 106
1 000 000
un million, soit 1000 x 1 000
Un Giga (G) représente 109
1 000 000 000
un milliard, soit 1000 x 1 000 000
Un Téra (T) représente 1012
1 000 000 000 000
mille milliards, soit 1000 x 1 000 000 000
On voit donc que chaque sous-unité représente 1000 fois plus que la précédente.
Autres sous-unités que vous pourriez rencontrer
Avant 1998, un ko voulait dire 1024 octets. Aujourd'hui, 1 ko veut bien dire 1000 octets. Si on veut parler d'un kilo-octet valant 1024 octets, on parle de kio plutôt que de ko.
Aujourd'hui 1 ko = 1000 o
Aujourd'hui 1 kio = 1024 o
Le système précédent est basé sur la base 10. En informatique, on travaille en base 2 puisqu'on est en binaire. Il existe donc une façon plus 'naturelle' de définir les relations entre les unités. Naturelle pour un ordinateur, moins pour les humains...
Pour les distinguer des autres unités, on rajoute un i à la fin.
Sous-unité
Valeur en décimal
Pourquoi ?
Un kilo (ki) représente 210
1 024
Un Méga (Mi) représente 220
1 048 576
Presque un million, 1024 x 1024
Un Giga (Gi) représente 230
1 073 741 824
Presque un milliard, soit 1024 x 1 048 576
Un Téra (Ti) représente 240
1 099 511 627 776
Presque mille milliards, soit 1024 plus que 1 Gi
On voit donc que chaque sous-unité représente 1024 fois plus que la précédente.
06° On considère un texte de 200 000 caractères. Calculer le nombre d'octets nécessaires à son stockage
en octets (o),
en bits,
en ko (ko)
en Mo (Mo)
...CORRECTION...
200 000 caractères donnent donc nbr_octets = 200 000 o.
Comme un octet est composé de 8 bits, nous obtenons :
nbr_bits = 200 000 * 8, soit nbr_bits = 1 600 000 b.
Pour obtenir le poids en ko, il suffit de diviser ce nombre par 1000 :
Avant d'en montrer toute l'utilité, voyons comme fonctionne l'hexadécimal.
7.1 Cases
Voyons comment fonctionne le décodage d'un nombre en base 16 ainsi que l'addition.
Que peut-on mettre dans les cases en hexadécimal ?
Des chiffres.
Combien et lesquels ?
Base 16 donc 16 CHIFFRES : 0 - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - A - B - C - D - E - F .
Pourquoi avoir pris des lettres plutôt que d'inventer de nouveaux symboles ? Parce que c'est plus facile ! En plus, les tables ne comportant que 128 symboles initialement, c'était plus rentable de recycler plutôt que d'en inventer de nouveaux. Il n'y avait déjà plus de place.
De 0 à 9, ce ne change pas :
N = 010= 016
N = 110= 116
N = 210= 216
...
N = 910= 916
Mais ensuite
N = 1010= A16
N = 1110= B16
N = 1210= C16
N = 1310= D16
N = 1410= E16
N = 1510= F16
La case de poids faible ( 1 ) est toujours située à droite.
Poids de case exprimé en puissance de 16
On peut écrire facilement le poids des cases en utilisant les puissances de 16 :
La case code
4096
256
16
1
qu'on peut écrire sous la forme
163
162
161
160
Exemple
Si j'écris M= 342916, je fais ceci en réalité dans ma tête :
Nombre M =
3
4
2
9
La case code
4096
256
16
1
On obtient donc
4096*3
256*4
16*2
1*9
D'ou la valeur de M en base 10 : M = 4096*3 + 256*4 + 16*2 + 9 = 13353 .
On peut donc écrire N = 342916 = 1335310.
L'exemple ne comporte aucun chiffre A à F volontairement. Difficile de savoir que 3429 est un nombre exprimé en hexadécimale si on ne l'indique pas par l'indice 16.
07° Montrer qu'on a bien N = 4116 = 6510. Il s'agit des deux valeurs rencontrées pour A en ASCII.
...CORRECTION...
Il suffit de calculer la valeur en base 10 avec 4 dans la case de droite et 1 dans la case de gauche..
On obtient N = 4 * 16 + 1 = 65.
08° Montrer que N = FF16 = 25510. Il s'agit de la valeur maximale pour un octet.
...CORRECTION...
Il suffit de calculer la valeur en base 10 avec F dans la case de droite et F dans la case de gauche.
Le chiffre F en base 16 correspond au nombre 15 en base 10.
On obtient N = 15 * 16 + 15 * 1 = 255.
09° Montrer que N = FE16 = 25410. Il s'agit de la valeur maximale pour un octet.
...CORRECTION...
Il suffit de calculer la valeur en base 10 avec F dans la case de droite et E dans la case de gauche.
Le chiffre E en base 16 correspond au nombre 14 en base 10.
On obtient N = 15 * 16 + 14 * 1 = 254.
7.2 Addition
Alors ça fonctionne comment l'addition ? Pourquoi F+1 donne 10 ? On se le demande non ?
Jusqu'à F, il n'y a pas de difficulté, il suffit de suivre la liste des CHIFFRES disponibles.
Base 16 donc 16 CHIFFRES : 0 - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - A - B - C - D - E - F .
Méthode à utiliser pour incrémenter (rajouter 1)
Tenter de rajouter 1 dans la case de l'unité (la case de poids faible, celle de droite). Pour cela, il suffit de placer le prochain chiffre dans la liste 0 ⇨ 1 ⇨ 2 ⇨ 3 ⇨ 4 ⇨ 5 ⇨ 6 ⇨ 7 ⇨ 8 ⇨ 9 ⇨ A ⇨ B ⇨ C ⇨ D ⇨ E ⇨ F
Si on est déja au dernier chiffre ( F ), on revient au premier chiffre ( 0 ) dans cette case ET on rajoute un dans la case juste à gauche. On fait une retenue.
Exemple 1 :
Si on rajoute 1 à
9
on obtient
A
...EXPLICATION...
On peut augmenter le chiffre de l'unité 9 en le faisant juste passer au chiffre suivant : A .
Exemple 2 :
Si on rajoute 1 à
E
on obtient
F
...EXPLICATION...
On peut augmenter le chiffre de l'unité E en le faisant juste passer au chiffre suivant : F .
Exemple 3 : cette fois, on va devoir rajouter une case à droite (elle contient 0 initialement puisqu'elle n'apparaît pas)
Si on rajoute 1 à
F
on obtient
1
0
...EXPLICATION...
On ne peut augmenter le chiffre de l'unité qui est déjà à F .
On la passe donc à 0 ET on incrémente la case juste à gauche.
La case de gauche était initialement à 0 : elle passe donc à 1 .
Exemple 4 :
Si on rajoute 1 à
1
3
on obtient
1
4
...EXPLICATION...
On peut augmenter le chiffre de l'unité 3 en le faisant juste passer au chiffre suivant : 4 .
Exemple 5 :
Si on rajoute 1 à
F
3
on obtient
F
4
...EXPLICATION...
On peut augmenter le chiffre de l'unité 3 en le faisant juste passer au chiffre suivant : 4 .
Exemple 6 :
Si on rajoute 1 à
3
F
F
on obtient
4
0
0
...EXPLICATION...
On ne peut augmenter le chiffre qui est déjà à F .
On la passe donc à 0 ET on incrémente la case juste à gauche.
La case juste à gauche était initialement à F : elle passe donc à 0 également et on va devoir augmenter de 1 la case suivante, la case la plus à gauche.
Le chiffre des centaines 3 passe donc à 4 .
7.3 Nombres de cas dénombrables
Si on ne possède qu'une case ? à remplir, on peut donc définir 16 valeurs de 0 à 15 10 ( soit F 16).
Comme le premier cas est numéroté 0, on a bien 15+1 = 16 valeurs possibles.
Si on dispose de 2 cases ?? à remplir, on peut définir des valeurs de 00 à FF .
Comme le premier cas est numéroté 0, on a bien 255+1 = 256 valeurs possibles.
On voit bien qu'il y a une généralisation à trouver. Laquelle ?
Nombre de cas dénombrables en base 16
En hexadécimal, si on dispose de X cases pouvant accueillir un des 16 chiffres de la base 16, le nombre de valeurs possibles est 16X10.
Attention : dans la mesure où le premier cas est 0, la valeur maximale est donc 16X - 110
Exemple : si on dispose de 4 cases
Le nombre de possibilité est 164 = 65 536
On peut alors stocker des valeurs partant de 0 jusqu'à 65535.
7.4 Bilan sur la base 16 (hexadécimal)
Résumé hexadécimal
Que peut-on mettre dans les cases d'un nombre en base 16 ?
Des chiffres. Combien et lesquels ?
Base 10 donc 10 CHIFFRES : 0 - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - A - B - C - D - E - F .
On peut facilement trouver le poids des cases en utilisant les puissances de 16 :
La case code
4096
256
16
1
qu'on peut écrire sous la forme
163
162
161
160
Méthode à utiliser pour incrémenter (rajouter 1)
Tenter de rajouter 1 dans la case de l'unité (la case de poids faible, celle de droite). Pour cela, il suffit de placer le prochain chiffre dans la liste 0 ⇨ 1 ⇨ 2 ⇨ 3 ⇨ 4 ⇨ 5 ⇨ 6 ⇨ 7 ⇨ 8 ⇨ 9 ⇨ A ⇨ B ⇨ C ⇨ D ⇨ E ⇨ F
Si on est déja au dernier chiffre ( F ), on revient au premier chiffre ( 0 ) dans cette case ET on rajoute un dans la case juste à gauche.
Nombre de valeurs disponibles en base 16
En hexadécimal, si on dispose de X cases pouvant accueillir un des 10 chiffres de la base 16, le nombre de valeurs possibles est 16X.
Attention : dans la mesure où le premier cas est 0, la valeur maximale est donc 16X - 1
La carte mère de votre ordinateur possède deux types de mémoire :
la mémoire morte (fixée par le constructeur et permettant le démarrage et l'utilisation de l'ordinateur) et
la mémoire vive (rapide d'accès mais qui disparaît à chaque fois qu'on éteint le système).
Ces deux mémoires ont une taille limitée.
Si l'on veut stocker ou partager de grandes quantités de données, il faut donc un autre type de dispositif, une mémoire de masse : disques durs, clés USB... Nous allons parler de ces dispositifs, anciens et récents, dans cette partie.
La carte perforée (≈ 1930)
Cette carte est l'héritière des bandes perforées utilisées dans les métiers à
tisser, les pianos et les orgues de Barbarie. Le créateur initial du système de bandes est le français Basile Bouchon en 1725.
Les cartes perforées sont les premiers systèmes de mémoire de masse et de communication (entrée/sortie) qui ont été utilisés au début des systèmes informatiques.
Carte perforée (Mutatis mutandis CC BY-SA sur Wikimedia)
En 1928, IBM dépose le brevet de la carte dite 80 colonnes qui sera la plus utilisée.
Carte perforée
Date d'introduction : vers 1930
Ordre de grandeur du stockage mémoire : 100 octets par carte (20 cm de long).
Ordre de grandeur du débit de lecture : 100 octets par seconde.
La bande magnétique (≈ 1950)
En 1950, l'apparition de la bande magnétique va rapidement mettre le stockage précédent à la retraite. La bande magnétique n'existe plus dans l'informatique domestique mais reste encore très utilisée dans les centres de stockage professionnels.
Bande magnétique (CC BY-SA sur Wikimedia)
Il s'agit d'une bande plastique d'environ 1,5 cm de largeur sur laquelle on place une poudre d'oxyde de Fer (Fe2O3) qui a comme propriété de pouvoir rester aimantée une fois soumise à un champ magnétique. C'est ainsi qu'on créé le 1 et le 0 : en fonction de l'aimantation du petit secteur qu'on teste.
En 1951 l'UNIVAC était ainsi muni de bandes magnétiques.
Grace Hopper devant l'UNIVAC en 1960 (image Wikipedia CC BY 2.0 - sur Flickr par Jan Arkesteijn)
Le principal problème ? Il faut dérouler la bande pour arriver à l'endroit voulu. On dit que l'accès est séquentiel : il faut parcourir la bande dans l'ordre. Ca peut être très long si l'information voulue est plutot en fin de bande !
Bande magnétique
Date d'introduction : vers 1950
Ordre de grandeur du stockage mémoire : 40 octets par cm de bande au début, beaucoup plus aujourd'hui.
Ordre de grandeur du débit de lecture : environ 2 ko par seconde au début, jusqu'à 2 Mo par seconde aujourd'hui.
La bande magnétique reste une référence en terme d'archivage de données car elle est moins chère qu'un disque dur. Autre avantage non négligeable : les erreurs d'écriture (un 0 qui se transforme en 1 ou inversement) sont 1000 fois moins nombreuses sur bande magnétique.
L'une des versions grand public de cette technologie est bien entendu la cassette :
Lecteur de cassette (D-Kuru CC BY-SA 3.0 sur Wikipedia)
Le disque dur (hard drive) (≈ 1955)
Nous restons sur un principe de fonctionnement électro-magnétique avec stockage magnétique.
Comme pour les bandes magnétiques :
écriture : on crée un courant électrique qui modifie les propriétés magnétiques de la partie voulue du disque.
lecture : on détecte les propriétés magnétiques de la zone voulue du disque car lorsque la tête de lecture passe au dessus, il y a création d'un courant électrique (état 1) ou non (état 0)
La différence fondamentale ? Il ne s'agit pas de bandes mais de disques qui tournent. L'information est répartie par secteur sur tout le disque : pour atteindre la zone voulue, il suffit donc au pire d'attendre que le disque ai fait un tour. C'est plus rapide que de rembobiner toute la bande.
Principe d'un disque (Stéphane CC BY-SA 3.0)
En 1956, la société IBM crée un premier disque dur de 5 Mo. L’ensemble mesurait alors 1,52 x 1,73 x 0,74 m !
Ordre de grandeur du stockage mémoire : le Mo au début, le To aujourd'hui.
Ordre de grandeur du débit de lecture : plusieurs centaines de Mo par seconde aujourd'hui.
C'est à partir des années 1990 que le prix et la taille des disques durs leur permettent d'être présents dans tous les ordinateurs personnels. Et à l'époque, les disques durs étaient internes. Pour transporter un programme ou des informations d'un ordinateur à l'autre, il fallait donc autre chose...
Sans Internet, on utilisait... des disquettes pour transporter l'information d'un ordinateur à un autre.
Le floopy disk ou disquette (disque souple) (≈ 1970)
Une petite révolution cette disquette : dès les années 1960 (et avant la démocratisation des disques durs) on cherche à remplacer le disque dur par un système moins cher et moins lourd.
En 1967, IBM crée la première disquette, capable de contenir environ 80 000 caractères. Elle devait permettre par exemple de transmettre des mises à jour sans Internet. Peu à peu, la disquette remplacera la bande perforée.
Disquette (image en domaine public)
Disquette (floppy disk)
Date d'introduction : vers 1967
Ordre de grandeur du stockage mémoire : la dizaine de ko au début (80 ko), le Mo ensuite (jusqu'à 3 Mo).
Ordre de grandeur du débit de lecture : plusieurs centaines de ko par seconde.
Belle révolution qui a permis le transfert d'informations de façon aisée.
Mais la disquette n'a pas survecu à la démocratisation des disques (CD, DVD, Blueray), d'Internet, des disques durs externes puis des clés USB.
Les disques CD(≈ 1980) - DVD(≈ 2000) et Blu-ray(≈ 2010)
Il s'agit de dispositifs optiques, tous basés à peu près sur le même principe d'un rayon laser qui parvient ou pas à traverser une zone opaque pour lui, ou pas.
CD / DVD / Blu-ray
Date d'introduction : vers 1990, 2000 et 2010
Ordre de grandeur du stockage mémoire :
700 Mo pour le CD,
8500 Mo pour le DVD et
128000 Mo pour le Blu-ray.
Ordre de grandeur du débit de lecture : 8 Mo par seconde.
Mémoires Flash : cartes(≈ 1990) et USB(≈ 2000)
Avec ces dispositifs, on change de technologie : jusqu'à présent, on avait un stockage de masse magnétique avec partie mécanique mobile pour enrouler ou faire tourner.
La technologie Flash est basée sur l'utilisation de transistors MOS, il s'agit donc d'un stockage purement électronique, sans aucune partie mobile.
La plupart des clés USB et les cartes SD sont issues de cette technologie.
Interieur d'une clé USB (image libre de droit, Wikipedia)
Ces dispositifs sont extrémement pratiques car on peut en trouver une grande variété en terme de taille de stockage : de quelques centaines de Mo à 1 To.
Attention aux bonnes affaires apparentes : pensez toujours à vérifier la vitesse de lecture et d'écriture. Avoir une clé de grande capacité c'est bien. S'il faut 9 jours pour la remplir, c'est nettement moins pratique !
L'USB 2.0 peut avoir une vitesse autour de 25 Mo.s-1.
L'USB 3.0 peut avoir une vitesse autour de 300 Mo.s-1.
L'USB 4.0 peut avoir une vitesse autour de de 40 Go.s-1.
On trouve également des objets ayant la forme d'une clé USB mais contenant plutôt un mini disque dur. On parle alors de flash disk, de microdrive ou de disque dur externe.
Les escrocs ont su profiter de l'attrait de la clé USB. On peut y mettre ce qu'on veut et lancer des programmes automatiquement lorsqu'on connecte la clé sur un ordinateur. Sachant que la difficulté n°1 est d'infecter un premier ordinateur lorsqu'on veut rentrer illégalement sur un réseau, l'arnaque consiste à laisser par terre une clé USB infectée du virus voulu. Qui peut résister et tenter de voir à qui appartient la clé ? Rajoutez une petite étiquette intrigante et vous êtes presque certain que quelqu'un finira par brancher la clé sur son ordinateur. Le facteur humain est souvent le point faible du réseau informatique !
/* 1 Importation de la biliothèque MeOrion */#include"MeOrion.h"/* 2 Instanciations des objets permettant de controler le robot */MeDCMotormoteur_gauche(M1);MeDCMotormoteur_droit(M2);Me7SegmentDisplayafficheur(PORT_6);/* 3 Fonction setup qui s'active une fois automatiquement au lancement */voidsetup(){for(bytevitesse=0;vitesse<500;vitesse++){moteur_gauche.run(vitesse);moteur_droit.run(-vitesse);afficheur.display(vitesse);delay(200);}moteur_gauche.stop();moteur_droit.stop();}/* 4 Fonction loop qui s'active en boucle une fois le setup effectué */voidloop(){}
CLIQUEZ ICI POUR VOIR L'ANIMATION :
moteur_gauche :
moteur_droit :
afficheur :
vitesse :
Activité publiée le 28 08 2019
Dernière modification : 03 10 2024
Auteur : ows. h.







], via Wikimedia Commons")





